Continuous Sign Language Recognition with Adapted Conformer via Unsupervised Pretraining

0

Sign in to get full access
Overview
- This paper proposes a novel approach for continuous sign language recognition using an adapted Conformer model with unsupervised pretraining.
- The researchers explore using Conformer, a state-of-the-art transformer-based architecture, for sign language recognition and introduce several key modifications to improve performance.
- Unsupervised pretraining is used to leverage large amounts of unlabeled sign language data and boost the model's performance on downstream tasks.
Plain English Explanation
The paper focuses on improving continuous sign language recognition, which is the task of automatically interpreting and transcribing sign language gestures and movements in real-time. The researchers took a model called Conformer, which has shown great success in speech recognition, and adapted it for the sign language recognition problem.
Conformer is a type of neural network that combines the strengths of convolutional and transformer-based models, making it well-suited for complex sequence-to-sequence tasks like sign language recognition. The researchers made several key modifications to the standard Conformer architecture to better capture the unique characteristics of sign language, such as incorporating relative attention mechanisms and pyramid-style feature extraction.
Additionally, the researchers leveraged the power of unsupervised pretraining, which involves training the model on a large amount of unlabeled sign language data before fine-tuning it on the specific task of continuous sign language recognition. This helps the model learn general representations of sign language that can be effectively applied to the downstream task, even when labeled training data is limited.
By combining the adapted Conformer architecture with unsupervised pretraining, the researchers were able to achieve state-of-the-art performance on several benchmark continuous sign language recognition datasets, demonstrating the effectiveness of their approach.
Technical Explanation
The paper proposes a novel continuous sign language recognition (CSLR) model based on the Conformer architecture, which has shown strong results in speech recognition. The researchers introduce several key modifications to the standard Conformer model to better suit the characteristics of sign language.
First, they incorporate a relative attention mechanism, which allows the model to better capture the relative spatial and temporal relationships between sign language components. This is crucial for understanding the complex, continuous nature of sign language sequences.
Additionally, the researchers employ a pyramid-style feature extraction approach, where the input video frames are progressively downsampled and processed through multiple Conformer blocks. This enables the model to capture both local and global features of the sign language gestures.
To further improve performance, the researchers leverage unsupervised pretraining, which involves training the model on a large amount of unlabeled sign language data before fine-tuning it on the specific CSLR task. This helps the model learn general representations of sign language that can be effectively applied to the downstream task, even when labeled training data is limited.
The researchers evaluate their adapted Conformer model on several benchmark CSLR datasets, including MSASL and PHOENIX2014T. They demonstrate state-of-the-art performance, outperforming previous methods and showcasing the effectiveness of their approach.
Critical Analysis
The paper presents a compelling and well-designed solution for continuous sign language recognition. The researchers' key innovations, such as the adapted Conformer architecture and the use of unsupervised pretraining, are well-justified and aligned with the unique challenges of the sign language recognition task.
One potential limitation of the study is the reliance on the Mediapipe framework for pose estimation, which may not generalize as well to different sign language datasets or real-world deployment scenarios. Additionally, the paper does not provide a detailed analysis of the model's performance on low-resource settings or its robustness to variations in signing styles and environments.
Further research could explore the potential of transfer learning techniques to leverage sign language datasets across different languages and domains, as well as investigate the feasibility of end-to-end sign language recognition models that directly process video inputs without relying on pose estimation.
Conclusion
This paper presents a novel approach for continuous sign language recognition that combines an adapted Conformer architecture with unsupervised pretraining. By incorporating relative attention mechanisms and pyramid-style feature extraction, the researchers have developed a model that can effectively capture the complex, continuous nature of sign language sequences.
The use of unsupervised pretraining on large amounts of unlabeled sign language data further boosts the model's performance, demonstrating the power of leveraging unlabeled data to improve the efficiency of sign language recognition systems.
The researchers' work represents a significant advancement in the field of sign language recognition and has the potential to improve accessibility and communication for the deaf and hard-of-hearing community. As the field continues to evolve, this paper's innovative techniques and insights will undoubtedly inspire future research and development in this important area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Continuous Sign Language Recognition with Adapted Conformer via Unsupervised Pretraining
Neena Aloysius, Geetha M, Prema Nedungadi
Conventional Deep Learning frameworks for continuous sign language recognition (CSLR) are comprised of a single or multi-modal feature extractor, a sequence-learning module, and a decoder for outputting the glosses. The sequence learning module is a crucial part wherein transformers have demonstrated their efficacy in the sequence-to-sequence tasks. Analyzing the research progress in the field of Natural Language Processing and Speech Recognition, a rapid introduction of various transformer variants is observed. However, in the realm of sign language, experimentation in the sequence learning component is limited. In this work, the state-of-the-art Conformer model for Speech Recognition is adapted for CSLR and the proposed model is termed ConSignformer. This marks the first instance of employing Conformer for a vision-based task. ConSignformer has bimodal pipeline of CNN as feature extractor and Conformer for sequence learning. For improved context learning we also introduce Cross-Modal Relative Attention (CMRA). By incorporating CMRA into the model, it becomes more adept at learning and utilizing complex relationships within the data. To further enhance the Conformer model, unsupervised pretraining called Regressional Feature Extraction is conducted on a curated sign language dataset. The pretrained Conformer is then fine-tuned for the downstream recognition task. The experimental results confirm the effectiveness of the adopted pretraining strategy and demonstrate how CMRA contributes to the recognition process. Remarkably, leveraging a Conformer-based backbone, our model achieves state-of-the-art performance on the benchmark datasets: PHOENIX-2014 and PHOENIX-2014T.
Read more5/21/2024
0
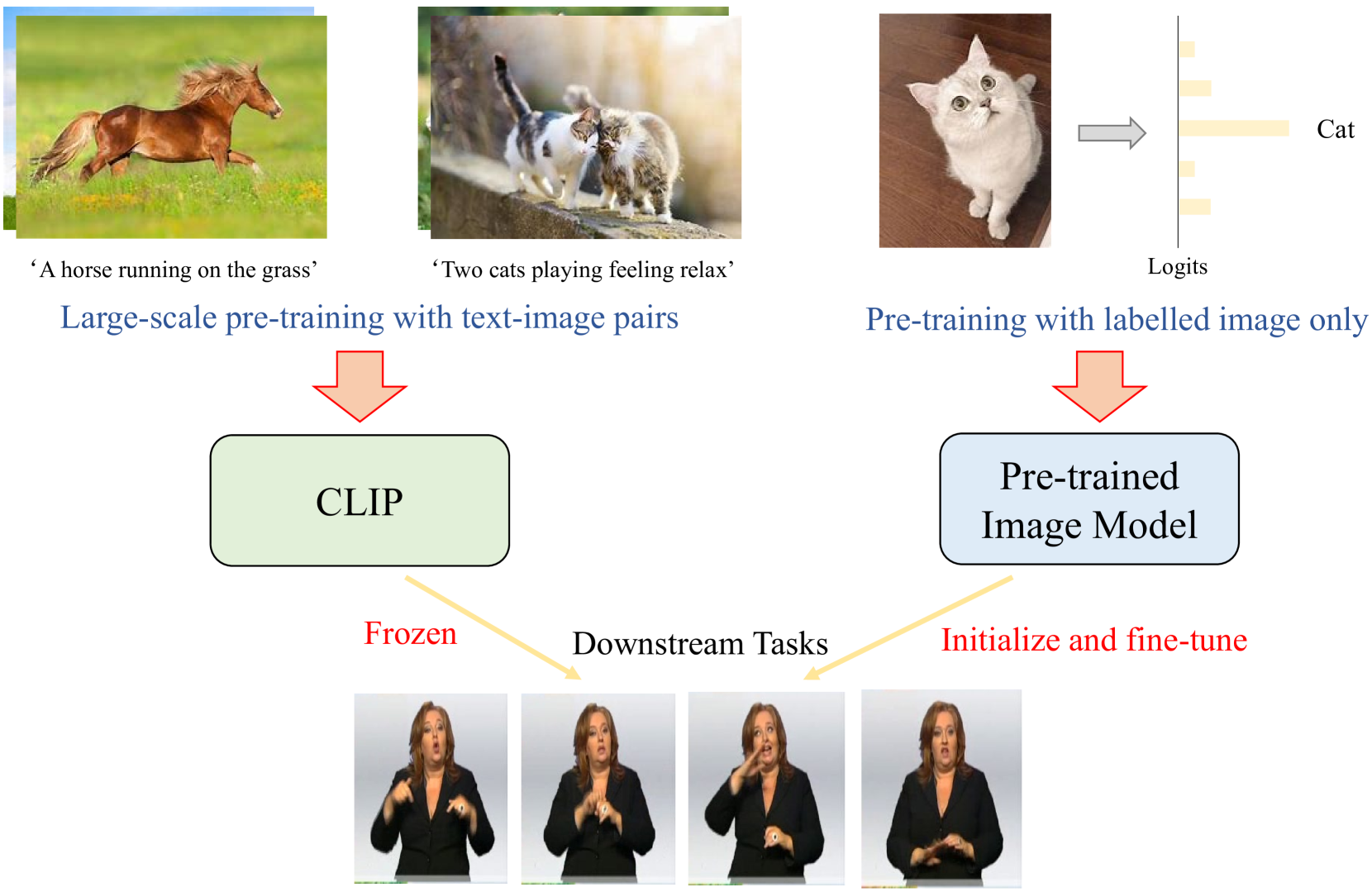
Improving Continuous Sign Language Recognition with Adapted Image Models
Lianyu Hu, Tongkai Shi, Liqing Gao, Zekang Liu, Wei Feng
The increase of web-scale weakly labelled image-text pairs have greatly facilitated the development of large-scale vision-language models (e.g., CLIP), which have shown impressive generalization performance over a series of downstream tasks. However, the massive model size and scarcity of available data limit their applications to fine-tune the whole model in downstream tasks. Besides, fully fine-tuning the model easily forgets the generic essential knowledge acquired in the pretraining stage and overfits the downstream data. To enable high efficiency when adapting these large vision-language models (e.g., CLIP) to performing continuous sign language recognition (CSLR) while preserving their generalizability, we propose a novel strategy (AdaptSign). Especially, CLIP is adopted as the visual backbone to extract frame-wise features whose parameters are fixed, and a set of learnable modules are introduced to model spatial sign variations or capture temporal sign movements. The introduced additional modules are quite lightweight, only owning 3.2% extra computations with high efficiency. The generic knowledge acquired in the pretraining stage is well-preserved in the frozen CLIP backbone in this process. Extensive experiments show that despite being efficient, AdaptSign is able to demonstrate superior performance across a series of CSLR benchmarks including PHOENIX14, PHOENIX14-T, CSL-Daily and CSL compared to existing methods. Visualizations show that AdaptSign could learn to dynamically pay major attention to the informative spatial regions and cross-frame trajectories in sign videos.
Read more4/15/2024
0
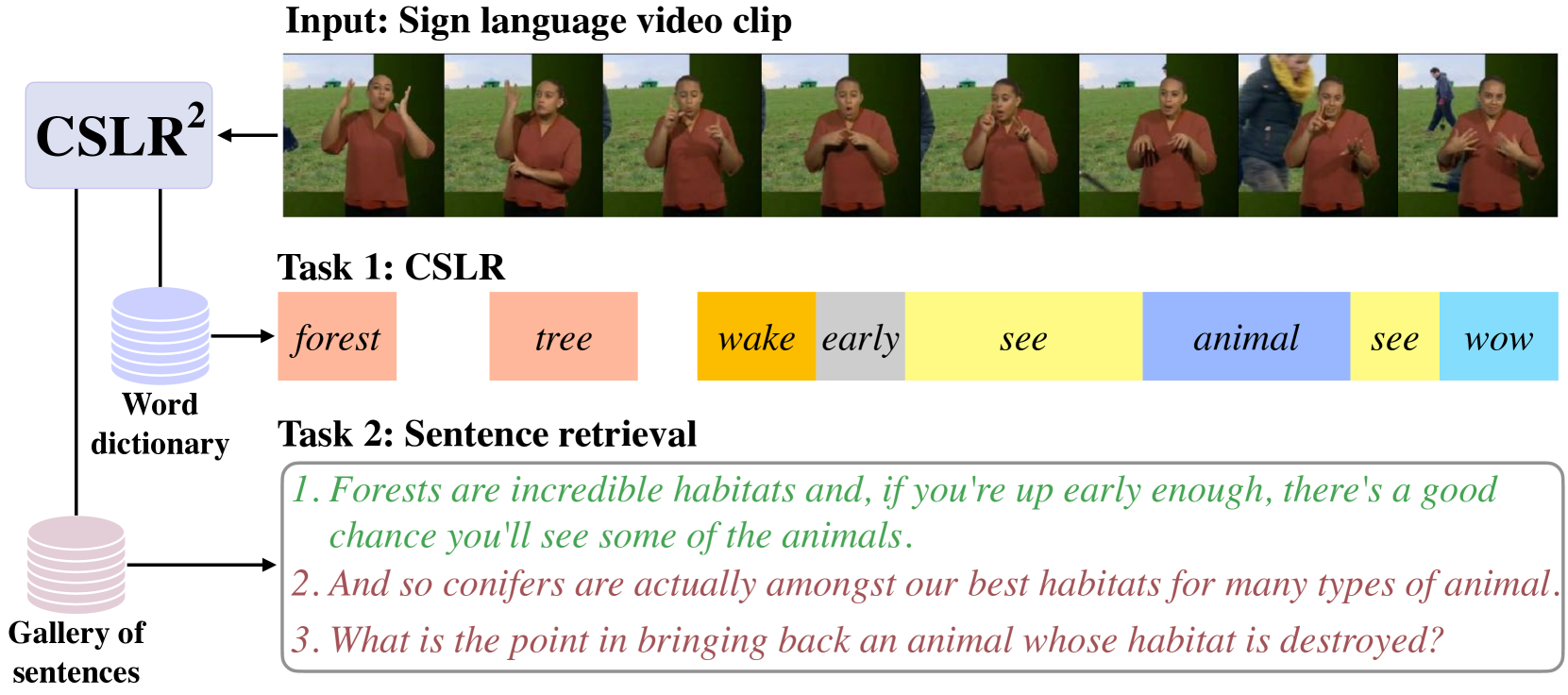
A Tale of Two Languages: Large-Vocabulary Continuous Sign Language Recognition from Spoken Language Supervision
Charles Raude, K R Prajwal, Liliane Momeni, Hannah Bull, Samuel Albanie, Andrew Zisserman, Gul Varol
In this work, our goals are two fold: large-vocabulary continuous sign language recognition (CSLR), and sign language retrieval. To this end, we introduce a multi-task Transformer model, CSLR2, that is able to ingest a signing sequence and output in a joint embedding space between signed language and spoken language text. To enable CSLR evaluation in the large-vocabulary setting, we introduce new dataset annotations that have been manually collected. These provide continuous sign-level annotations for six hours of test videos, and will be made publicly available. We demonstrate that by a careful choice of loss functions, training the model for both the CSLR and retrieval tasks is mutually beneficial in terms of performance -- retrieval improves CSLR performance by providing context, while CSLR improves retrieval with more fine-grained supervision. We further show the benefits of leveraging weak and noisy supervision from large-vocabulary datasets such as BOBSL, namely sign-level pseudo-labels, and English subtitles. Our model significantly outperforms the previous state of the art on both tasks.
Read more5/17/2024

0
A Comparative Study of Continuous Sign Language Recognition Techniques
Sarah Alyami, Hamzah Luqman
Continuous Sign Language Recognition (CSLR) focuses on the interpretation of a sequence of sign language gestures performed continually without pauses. In this study, we conduct an empirical evaluation of recent deep learning CSLR techniques and assess their performance across various datasets and sign languages. The models selected for analysis implement a range of approaches for extracting meaningful features and employ distinct training strategies. To determine their efficacy in modeling different sign languages, these models were evaluated using multiple datasets, specifically RWTH-PHOENIX-Weather-2014, ArabSign, and GrSL, each representing a unique sign language. The performance of the models was further tested with unseen signers and sentences. The conducted experiments establish new benchmarks on the selected datasets and provide valuable insights into the robustness and generalization of the evaluated techniques under challenging scenarios.
Read more6/19/2024