Continuum Attention for Neural Operators
2406.06486
0
0

Abstract
Transformers, and the attention mechanism in particular, have become ubiquitous in machine learning. Their success in modeling nonlocal, long-range correlations has led to their widespread adoption in natural language processing, computer vision, and time-series problems. Neural operators, which map spaces of functions into spaces of functions, are necessarily both nonlinear and nonlocal if they are universal; it is thus natural to ask whether the attention mechanism can be used in the design of neural operators. Motivated by this, we study transformers in the function space setting. We formulate attention as a map between infinite dimensional function spaces and prove that the attention mechanism as implemented in practice is a Monte Carlo or finite difference approximation of this operator. The function space formulation allows for the design of transformer neural operators, a class of architectures designed to learn mappings between function spaces, for which we prove a universal approximation result. The prohibitive cost of applying the attention operator to functions defined on multi-dimensional domains leads to the need for more efficient attention-based architectures. For this reason we also introduce a function space generalization of the patching strategy from computer vision, and introduce a class of associated neural operators. Numerical results, on an array of operator learning problems, demonstrate the promise of our approaches to function space formulations of attention and their use in neural operators.
Create account to get full access
Overview
- This paper introduces a novel neural network architecture called "Continuum Attention for Neural Operators" that aims to improve the performance of neural networks on tasks involving continuous functions or operators.
- The key innovation is the use of a "continuum attention" mechanism that allows the network to dynamically focus on relevant parts of the input function during computation.
- The authors demonstrate the effectiveness of their approach on several benchmark tasks, including learning to solve partial differential equations and approximating smooth functions.
Plain English Explanation
The paper introduces a new type of neural network that is designed to work well with continuous functions or mathematical operators. Typical neural networks struggle with these types of inputs because they are not well-suited to capturing the continuous nature of the information.
The core idea behind the "Continuum Attention" approach is to allow the neural network to adaptively focus on the most relevant parts of the input function during the computation. This is done through a specialized attention mechanism that learns to identify and emphasize the important regions of the input.
To give a concrete example, imagine you're trying to train a neural network to solve partial differential equations. These equations describe continuous physical processes, like the flow of heat or the motion of fluids. A traditional neural network may have trouble capturing all the nuances of these continuous phenomena. But the Continuum Attention model can learn to selectively attend to the most critical parts of the input equation, leading to better performance.
The authors show that this approach outperforms existing neural network architectures on a variety of benchmark tasks involving continuous functions and operators. This suggests the Continuum Attention mechanism is a promising new tool for tackling problems that require reasoning about continuous mathematical objects.
Technical Explanation
The key innovation in this paper is the introduction of a "Continuum Attention" mechanism for neural networks. This attention module allows the network to dynamically focus on relevant parts of the input function or operator during the computation.
Traditionally, neural networks have struggled with continuous inputs because they are primarily designed to work with discrete, grid-like data (e.g., images, text). To address this, the authors draw inspiration from the attention as hypernetwork and attention as RNN approaches, which have shown the benefits of using attention mechanisms for continuous data.
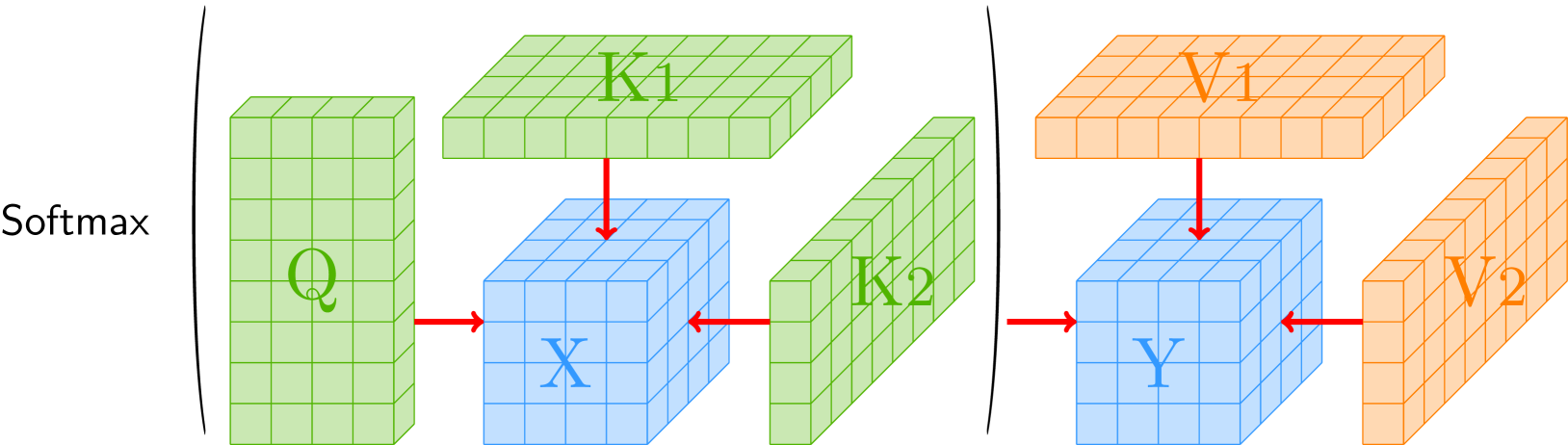
The Continuum Attention module works by first encoding the input function or operator into a set of query, key, and value tensors. These tensors are then used to compute attention weights that indicate the relevance of different parts of the input. Unlike traditional attention, where the queries, keys, and values are discrete entities, in the Continuum Attention module they are continuous functions.
This continuous attention mechanism allows the network to adaptively focus on the most important regions of the input, as demonstrated in the Are Queries, Keys Always Relevant? A Case Study paper. The authors also show that the Continuum Attention module can be combined with other neural network components, such as tensor attention, to further enhance performance.
Critical Analysis
The Continuum Attention approach presented in this paper is a promising step forward in developing neural networks that can effectively handle continuous functions and operators. The authors have demonstrated the effectiveness of their approach on several benchmark tasks, which is a strong validation of the underlying ideas.
However, it's important to note that the paper primarily focuses on idealized, synthetic tasks, such as learning to solve partial differential equations. While these are valuable test cases, it will be important to see how the Continuum Attention mechanism performs on more complex, real-world problems involving continuous data.
Additionally, the authors acknowledge that their approach can be computationally expensive, especially for high-dimensional input functions. This may limit its practical applicability in certain domains. Further research could explore ways to improve the efficiency of the Continuum Attention module, perhaps by drawing on techniques from the Tensor Attention Training paper.
Overall, the Continuum Attention for Neural Operators is an exciting development that could have a significant impact on a wide range of fields that rely on continuous mathematical modeling. As with any new research, it will be important to continue exploring its strengths, limitations, and potential applications in the years to come.
Conclusion
This paper introduces a novel neural network architecture called "Continuum Attention for Neural Operators" that aims to improve the performance of neural networks on tasks involving continuous functions or operators. The key innovation is the use of a "continuum attention" mechanism that allows the network to dynamically focus on relevant parts of the input function during computation.
The authors demonstrate the effectiveness of their approach on several benchmark tasks, including learning to solve partial differential equations and approximating smooth functions. This suggests the Continuum Attention mechanism is a promising new tool for tackling problems that require reasoning about continuous mathematical objects.
While the paper focuses on idealized, synthetic tasks, the Continuum Attention approach represents an important step forward in developing neural networks that can effectively handle continuous data. As this research continues to evolve, it could have significant implications for a wide range of fields that rely on continuous mathematical modeling, from fluid dynamics to climate science.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Attention as a Hypernetwork
Simon Schug, Seijin Kobayashi, Yassir Akram, Jo~ao Sacramento, Razvan Pascanu
0
0
Transformers can under some circumstances generalize to novel problem instances whose constituent parts might have been encountered during training but whose compositions have not. What mechanisms underlie this ability for compositional generalization? By reformulating multi-head attention as a hypernetwork, we reveal that a low-dimensional latent code specifies key-query specific operations. We find empirically that this latent code is highly structured, capturing information about the subtasks performed by the network. Using the framework of attention as a hypernetwork we further propose a simple modification of multi-head linear attention that strengthens the ability for compositional generalization on a range of abstract reasoning tasks. In particular, we introduce a symbolic version of the Raven Progressive Matrices human intelligence test on which we demonstrate how scaling model size and data enables compositional generalization and gives rise to a functionally structured latent code in the transformer.
6/24/2024
✅
Attention as an RNN
Leo Feng, Frederick Tung, Hossein Hajimirsadeghi, Mohamed Osama Ahmed, Yoshua Bengio, Greg Mori
0
0
The advent of Transformers marked a significant breakthrough in sequence modelling, providing a highly performant architecture capable of leveraging GPU parallelism. However, Transformers are computationally expensive at inference time, limiting their applications, particularly in low-resource settings (e.g., mobile and embedded devices). Addressing this, we (1) begin by showing that attention can be viewed as a special Recurrent Neural Network (RNN) with the ability to compute its textit{many-to-one} RNN output efficiently. We then (2) show that popular attention-based models such as Transformers can be viewed as RNN variants. However, unlike traditional RNNs (e.g., LSTMs), these models cannot be updated efficiently with new tokens, an important property in sequence modelling. Tackling this, we (3) introduce a new efficient method of computing attention's textit{many-to-many} RNN output based on the parallel prefix scan algorithm. Building on the new attention formulation, we (4) introduce textbf{Aaren}, an attention-based module that can not only (i) be trained in parallel (like Transformers) but also (ii) be updated efficiently with new tokens, requiring only constant memory for inferences (like traditional RNNs). Empirically, we show Aarens achieve comparable performance to Transformers on $38$ datasets spread across four popular sequential problem settings: reinforcement learning, event forecasting, time series classification, and time series forecasting tasks while being more time and memory-efficient.
5/29/2024

A Primal-Dual Framework for Transformers and Neural Networks
Tan M. Nguyen, Tam Nguyen, Nhat Ho, Andrea L. Bertozzi, Richard G. Baraniuk, Stanley J. Osher
0
0
Self-attention is key to the remarkable success of transformers in sequence modeling tasks including many applications in natural language processing and computer vision. Like neural network layers, these attention mechanisms are often developed by heuristics and experience. To provide a principled framework for constructing attention layers in transformers, we show that the self-attention corresponds to the support vector expansion derived from a support vector regression problem, whose primal formulation has the form of a neural network layer. Using our framework, we derive popular attention layers used in practice and propose two new attentions: 1) the Batch Normalized Attention (Attention-BN) derived from the batch normalization layer and 2) the Attention with Scaled Head (Attention-SH) derived from using less training data to fit the SVR model. We empirically demonstrate the advantages of the Attention-BN and Attention-SH in reducing head redundancy, increasing the model's accuracy, and improving the model's efficiency in a variety of practical applications including image and time-series classification.
6/21/2024
Tensor Attention Training: Provably Efficient Learning of Higher-order Transformers
Jiuxiang Gu, Yingyu Liang, Zhenmei Shi, Zhao Song, Yufa Zhou
0
0
Tensor Attention, a multi-view attention that is able to capture high-order correlations among multiple modalities, can overcome the representational limitations of classical matrix attention. However, the $Omega(n^3)$ time complexity of tensor attention poses a significant obstacle to its practical implementation in transformers, where $n$ is the input sequence length. In this work, we prove that the backward gradient of tensor attention training can be computed in almost linear $n^{1+o(1)}$ time, the same complexity as its forward computation under a bounded entries assumption. We provide a closed-form solution for the gradient and propose a fast computation method utilizing polynomial approximation methods and tensor algebraic tricks. Furthermore, we prove the necessity and tightness of our assumption through hardness analysis, showing that slightly weakening it renders the gradient problem unsolvable in truly subcubic time. Our theoretical results establish the feasibility of efficient higher-order transformer training and may facilitate practical applications of tensor attention architectures.
5/28/2024