Contracting Skeletal Kinematics for Human-Related Video Anomaly Detection

0
❗
Sign in to get full access
Overview
- Detecting anomalies in human behavior is crucial for recognizing and responding to dangerous situations like fights or falls
- Anomaly detection is challenging because anomalous events are rare and the system must identify novel anomalies it has not seen before
- The paper proposes a model called COSKAD that encodes skeletal human motion using a graph convolutional network and learns to project the motion data onto a low-dimensional latent space for anomaly detection
Plain English Explanation
The researchers developed a system called COSKAD to detect unusual or anomalous human behavior in videos. Detecting anomalies is important because it can help identify dangerous situations like fights or falls, especially for elderly individuals. However, anomaly detection is complex because anomalous events are infrequent, and the system must be able to recognize novel anomalies it hasn't seen before during training.
The key idea behind COSKAD is to represent the movements of the human skeleton in the video using a graph convolutional network. This allows the system to learn a compact, low-dimensional representation or "embedding" of the skeletal motion. The researchers then propose projecting these skeletal motion embeddings onto three different types of latent spaces - Euclidean, spherical, and hyperbolic. By learning to contract the embeddings onto a low-dimensional latent space, the system can more easily identify unusual motion patterns that deviate from the "normal" motion it has observed.
The researchers show that this approach outperforms existing state-of-the-art methods for anomaly detection on several benchmark datasets, including a new human-focused dataset they created with annotated skeletons. Their system sets a new performance record on some of these datasets, rivaling even video-based anomaly detection methods.
Technical Explanation
COSKAD is a novel model for video anomaly detection that encodes skeletal human motion using a graph convolutional network (GCN). The key innovation is that COSKAD learns to project the skeletal motion embeddings onto a low-dimensional latent space in a way that "contracts" the embeddings onto a minimum-volume manifold.
The researchers explore three different types of latent spaces for this projection:
- Euclidean - The standard Euclidean (flat) space used by most prior work.
- Spherical - A curved, spherical latent space.
- Hyperbolic - A negatively curved, hyperbolic latent space.
All three latent space variants of COSKAD outperform existing state-of-the-art methods on the UBnormal dataset, which the researchers extended to include human-annotated skeletal data. COSKAD also sets a new performance record on the human-focused versions of the ShanghaiTech Campus and CUHK Avenue datasets, matching the performance of more complex video-based anomaly detection approaches.
The key insight is that by learning to project the skeletal motion embeddings onto a low-dimensional latent space in an optimal way, COSKAD can more effectively identify unusual or anomalous motion patterns that deviate from the "normal" motion seen during training. This latent space projection approach allows COSKAD to perform open-set recognition, meaning it can detect novel anomalies it has not observed before.
Critical Analysis
The researchers acknowledge that their COSKAD model has some limitations. First, it relies on accurate skeletal pose estimation, which can be challenging in real-world scenarios with occlusions or low image quality. Modeling 3D infant kinetics using adaptive graph structures may help address this limitation.
Additionally, COSKAD is designed for single-person anomaly detection. Extending the approach to handle multi-person interactions or estimating poses across datasets could further broaden its applicability. The researchers mention plans to release the source code and dataset upon acceptance, which will allow the community to build upon and validate their findings.
Overall, the COSKAD model represents a promising advance in video anomaly detection by leveraging skeletal motion data and innovative latent space projection techniques. While it has some limitations, the strong performance on benchmark datasets suggests it could be a valuable tool for applications like surveillance, eldercare, and human-robot interaction.
Conclusion
The COSKAD model proposed in this paper addresses the challenge of video anomaly detection by encoding skeletal human motion and learning to project the motion embeddings onto low-dimensional latent spaces. By contracting the embeddings onto minimum-volume manifolds in Euclidean, spherical, and hyperbolic spaces, COSKAD can effectively identify unusual motion patterns that deviate from "normal" behavior.
The researchers demonstrate that COSKAD outperforms existing state-of-the-art methods on several benchmark datasets, including a new human-focused dataset they created. Their system sets a new performance record on some datasets, even matching the results of more complex video-based anomaly detection approaches.
While COSKAD has some limitations, such as reliance on accurate skeletal pose estimation and a focus on single-person anomalies, its strong performance suggests it could be a valuable tool for real-world applications like surveillance, eldercare, and human-robot interaction that require the ability to detect and respond to anomalous or dangerous human behaviors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
Contracting Skeletal Kinematics for Human-Related Video Anomaly Detection
Alessandro Flaborea, Guido D'Amely, Stefano D'Arrigo, Marco Aurelio Sterpa, Alessio Sampieri, Fabio Galasso
Detecting the anomaly of human behavior is paramount to timely recognizing endangering situations, such as street fights or elderly falls. However, anomaly detection is complex since anomalous events are rare and because it is an open set recognition task, i.e., what is anomalous at inference has not been observed at training. We propose COSKAD, a novel model that encodes skeletal human motion by a graph convolutional network and learns to COntract SKeletal kinematic embeddings onto a latent hypersphere of minimum volume for Video Anomaly Detection. We propose three latent spaces: the commonly-adopted Euclidean and the novel spherical and hyperbolic. All variants outperform the state-of-the-art on the most recent UBnormal dataset, for which we contribute a human-related version with annotated skeletons. COSKAD sets a new state-of-the-art on the human-related versions of ShanghaiTech Campus and CUHK Avenue, with performance comparable to video-based methods. Source code and dataset will be released upon acceptance.
Read more7/24/2024
0
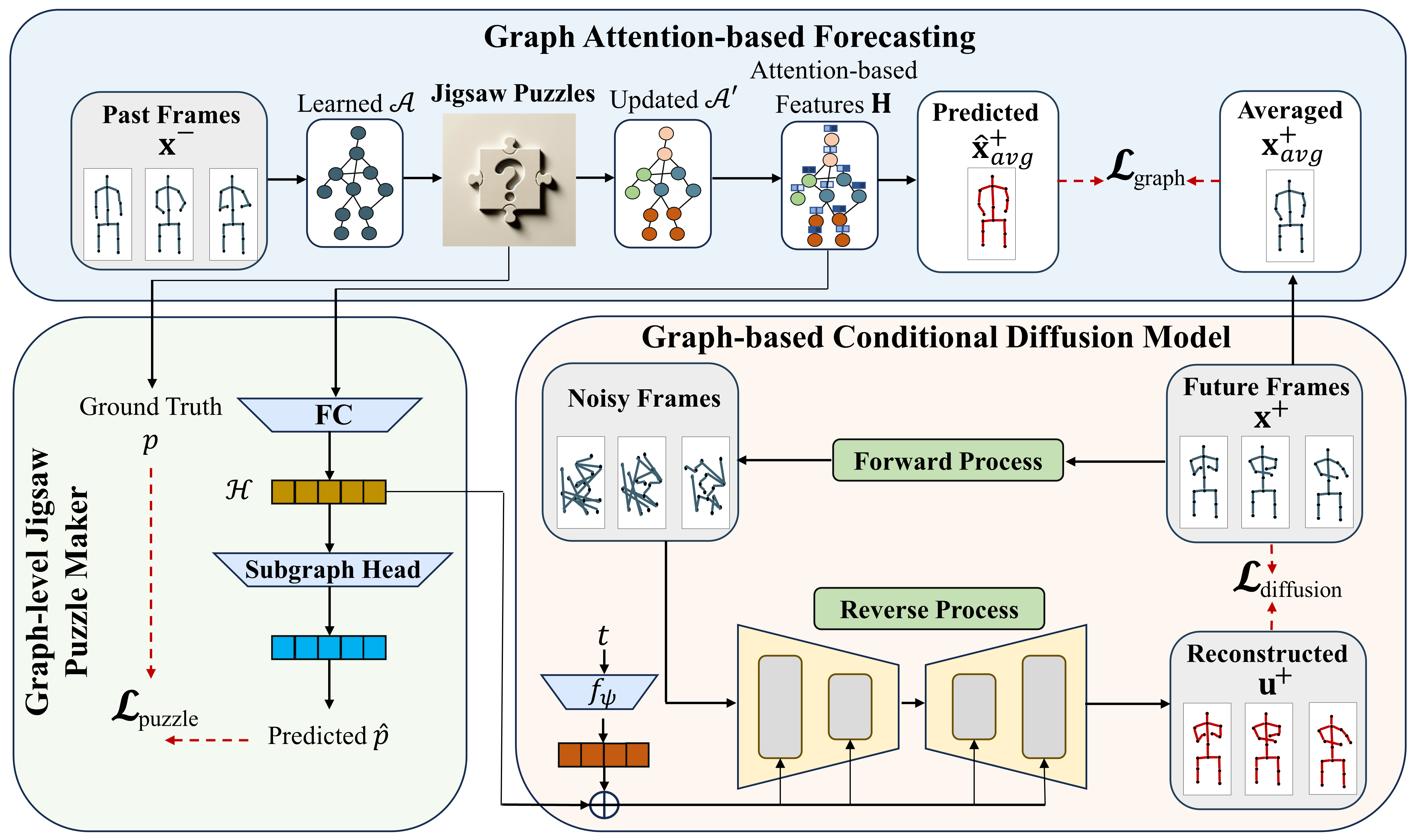
Graph-Jigsaw Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection
Ali Karami, Thi Kieu Khanh Ho, Narges Armanfard
Skeleton-based video anomaly detection (SVAD) is a crucial task in computer vision. Accurately identifying abnormal patterns or events enables operators to promptly detect suspicious activities, thereby enhancing safety. Achieving this demands a comprehensive understanding of human motions, both at body and region levels, while also accounting for the wide variations of performing a single action. However, existing studies fail to simultaneously address these crucial properties. This paper introduces a novel, practical and lightweight framework, namely Graph-Jigsaw Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection (GiCiSAD) to overcome the challenges associated with SVAD. GiCiSAD consists of three novel modules: the Graph Attention-based Forecasting module to capture the spatio-temporal dependencies inherent in the data, the Graph-level Jigsaw Puzzle Maker module to distinguish subtle region-level discrepancies between normal and abnormal motions, and the Graph-based Conditional Diffusion model to generate a wide spectrum of human motions. Extensive experiments on four widely used skeleton-based video datasets show that GiCiSAD outperforms existing methods with significantly fewer training parameters, establishing it as the new state-of-the-art.
Read more9/4/2024

0
Unveiling Context-Related Anomalies: Knowledge Graph Empowered Decoupling of Scene and Action for Human-Related Video Anomaly Detection
Chenglizhao Chen, Xinyu Liu, Mengke Song, Luming Li, Xu Yu, Shanchen Pang
Detecting anomalies in human-related videos is crucial for surveillance applications. Current methods primarily include appearance-based and action-based techniques. Appearance-based methods rely on low-level visual features such as color, texture, and shape. They learn a large number of pixel patterns and features related to known scenes during training, making them effective in detecting anomalies within these familiar contexts. However, when encountering new or significantly changed scenes, i.e., unknown scenes, they often fail because existing SOTA methods do not effectively capture the relationship between actions and their surrounding scenes, resulting in low generalization. In contrast, action-based methods focus on detecting anomalies in human actions but are usually less informative because they tend to overlook the relationship between actions and their scenes, leading to incorrect detection. For instance, the normal event of running on the beach and the abnormal event of running on the street might both be considered normal due to the lack of scene information. In short, current methods struggle to integrate low-level visual and high-level action features, leading to poor anomaly detection in varied and complex scenes. To address this challenge, we propose a novel decoupling-based architecture for human-related video anomaly detection (DecoAD). DecoAD significantly improves the integration of visual and action features through the decoupling and interweaving of scenes and actions, thereby enabling a more intuitive and accurate understanding of complex behaviors and scenes. DecoAD supports fully supervised, weakly supervised, and unsupervised settings.
Read more9/6/2024

0
An Exploratory Study on Human-Centric Video Anomaly Detection through Variational Autoencoders and Trajectory Prediction
Ghazal Alinezhad Noghre, Armin Danesh Pazho, Hamed Tabkhi
Video Anomaly Detection (VAD) represents a challenging and prominent research task within computer vision. In recent years, Pose-based Video Anomaly Detection (PAD) has drawn considerable attention from the research community due to several inherent advantages over pixel-based approaches despite the occasional suboptimal performance. Specifically, PAD is characterized by reduced computational complexity, intrinsic privacy preservation, and the mitigation of concerns related to discrimination and bias against specific demographic groups. This paper introduces TSGAD, a novel human-centric Two-Stream Graph-Improved Anomaly Detection leveraging Variational Autoencoders (VAEs) and trajectory prediction. TSGAD aims to explore the possibility of utilizing VAEs as a new approach for pose-based human-centric VAD alongside the benefits of trajectory prediction. We demonstrate TSGAD's effectiveness through comprehensive experimentation on benchmark datasets. TSGAD demonstrates comparable results with state-of-the-art methods showcasing the potential of adopting variational autoencoders. This suggests a promising direction for future research endeavors. The code base for this work is available at https://github.com/TeCSAR-UNCC/TSGAD.
Read more6/26/2024