Contrasting Linguistic Patterns in Human and LLM-Generated Text

0
🌀
Sign in to get full access
Overview
- Researchers conducted a detailed comparison of human-written English news text and text generated by large language models (LLMs).
- The analysis looked at various linguistic aspects like grammar, word choice, emotions, and bias.
- The results showed clear differences between human and AI-generated text, with the AI text exhibiting more uniform sentence lengths, less diverse vocabulary, and different usage of language elements.
- Notably, the AI text tended to express less negative emotion and more sexist bias than the human-written text.
Plain English Explanation
In this study, researchers wanted to understand how text written by humans compares to text generated by large AI language models. They analyzed a variety of linguistic features in news articles written by people and text produced by six different AI models.
Some key differences they found:
- Sentence Structure: Human-written sentences had more varied lengths, while the AI text tended to have more uniform, evenly-spaced sentences.
- Vocabulary: Humans used a wider variety of words, while the AI models relied on a more limited vocabulary.
- Emotions: The human text expressed more negative emotions like fear and disgust, while the AI text was more neutral and less emotive.
- Bias: Both human and AI text exhibited sexist biases, but the AI models' biases were even stronger in most cases.
Overall, the researchers discovered that there are many measurable ways in which human and AI-generated text differ, from the basic structure of the language to the implied meaning and sentiment. These findings help us better understand the capabilities and limitations of current large language models compared to natural human writing.
Technical Explanation
The researchers conducted a comprehensive quantitative analysis to compare linguistic attributes of human-written English news text and text generated by six different large language models (LLMs). They examined a range of features including morphology, syntax, psychometrics, and sociolinguistics.
The results revealed several key differences. Human-written text had more varied sentence lengths, a more diverse vocabulary, and distinct usage of grammatical structures like dependencies and constituents. Humans also tended to use shorter constituents and more optimized dependency distances.
Additionally, the human text exhibited stronger negative emotions like fear and disgust, while the AI-generated text expressed less of these and more neutral or positive emotions. Interestingly, the AI models also exhibited more sexist biases than the human-written text, with the level of bias increasing as the model size grew larger.
Other notable differences included the AI text using more numbers, symbols, and auxiliary verbs (suggesting more objective, impersonal language), as well as more pronouns. The researchers found the differences between human and AI text were generally larger than the differences among the AI models themselves.
Critical Analysis
The researchers provide a thorough, data-driven analysis of the linguistic differences between human-written and AI-generated text. By examining a broad set of features, they are able to paint a comprehensive picture of how current large language models fall short of replicating natural human writing.
However, the study is limited to a specific domain - news articles. It's unclear how generalizable these findings are to other genres of text, such as creative writing, technical documentation, or conversational dialogues. Further research would be needed to understand if the observed patterns hold across a wider range of text types.
Additionally, the researchers do not delve into the potential causes or implications of the identified biases. While they note the concerning trend of AI models amplifying sexist biases, more investigation is needed to understand the root drivers of this phenomenon and how it could impact downstream applications of these technologies.
Overall, this study offers valuable insights, but raises additional questions about the nuanced relationship between human and machine-generated language that merit further exploration.
Conclusion
This research provides a detailed, data-driven comparison of human-written English text and text generated by large language models. The findings reveal significant linguistic differences between the two, spanning sentence structure, vocabulary, emotional expression, and social biases.
While current AI models can generate fluent, grammatically correct text, they still fall short of replicating the richness, complexity, and subtle meaning conveyed in natural human writing. These results underscore the continued limitations of even the largest and most advanced language models, and highlight the importance of further research to build AI systems that can more closely emulate human linguistic capabilities.
Ultimately, this work contributes to our evolving understanding of the strengths and weaknesses of AI-generated content, which has important implications for the responsible development and deployment of these technologies in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
Contrasting Linguistic Patterns in Human and LLM-Generated Text
Alberto Mu~noz-Ortiz, Carlos G'omez-Rodr'iguez, David Vilares
We conduct a quantitative analysis contrasting human-written English news text with comparable large language model (LLM) output from six different LLMs that cover three different families and four sizes in total. Our analysis spans several measurable linguistic dimensions, including morphological, syntactic, psychometric, and sociolinguistic aspects. The results reveal various measurable differences between human and AI-generated texts. Human texts exhibit more scattered sentence length distributions, more variety of vocabulary, a distinct use of dependency and constituent types, shorter constituents, and more optimized dependency distances. Humans tend to exhibit stronger negative emotions (such as fear and disgust) and less joy compared to text generated by LLMs, with the toxicity of these models increasing as their size grows. LLM outputs use more numbers, symbols and auxiliaries (suggesting objective language) than human texts, as well as more pronouns. The sexist bias prevalent in human text is also expressed by LLMs, and even magnified in all of them but one. Differences between LLMs and humans are larger than between LLMs.
Read more9/4/2024
🔎
0
Differentiating between human-written and AI-generated texts using linguistic features automatically extracted from an online computational tool
Georgios P. Georgiou
While extensive research has focused on ChatGPT in recent years, very few studies have systematically quantified and compared linguistic features between human-written and Artificial Intelligence (AI)-generated language. This study aims to investigate how various linguistic components are represented in both types of texts, assessing the ability of AI to emulate human writing. Using human-authored essays as a benchmark, we prompted ChatGPT to generate essays of equivalent length. These texts were analyzed using Open Brain AI, an online computational tool, to extract measures of phonological, morphological, syntactic, and lexical constituents. Despite AI-generated texts appearing to mimic human speech, the results revealed significant differences across multiple linguistic features such as consonants, word stress, nouns, verbs, pronouns, direct objects, prepositional modifiers, and use of difficult words among others. These findings underscore the importance of integrating automated tools for efficient language assessment, reducing time and effort in data analysis. Moreover, they emphasize the necessity for enhanced training methodologies to improve the capacity of AI for producing more human-like text.
Read more7/12/2024

0
Human Perception of LLM-generated Text Content in Social Media Environments
Kristina Radivojevic, Matthew Chou, Karla Badillo-Urquiola, Paul Brenner
Emerging technologies, particularly artificial intelligence (AI), and more specifically Large Language Models (LLMs) have provided malicious actors with powerful tools for manipulating digital discourse. LLMs have the potential to affect traditional forms of democratic engagements, such as voter choice, government surveys, or even online communication with regulators; since bots are capable of producing large quantities of credible text. To investigate the human perception of LLM-generated content, we recruited over 1,000 participants who then tried to differentiate bot from human posts in social media discussion threads. We found that humans perform poorly at identifying the true nature of user posts on social media. We also found patterns in how humans identify LLM-generated text content in social media discourse. Finally, we observed the Uncanny Valley effect in text dialogue in both user perception and identification. This indicates that despite humans being poor at the identification process, they can still sense discomfort when reading LLM-generated content.
Read more9/11/2024
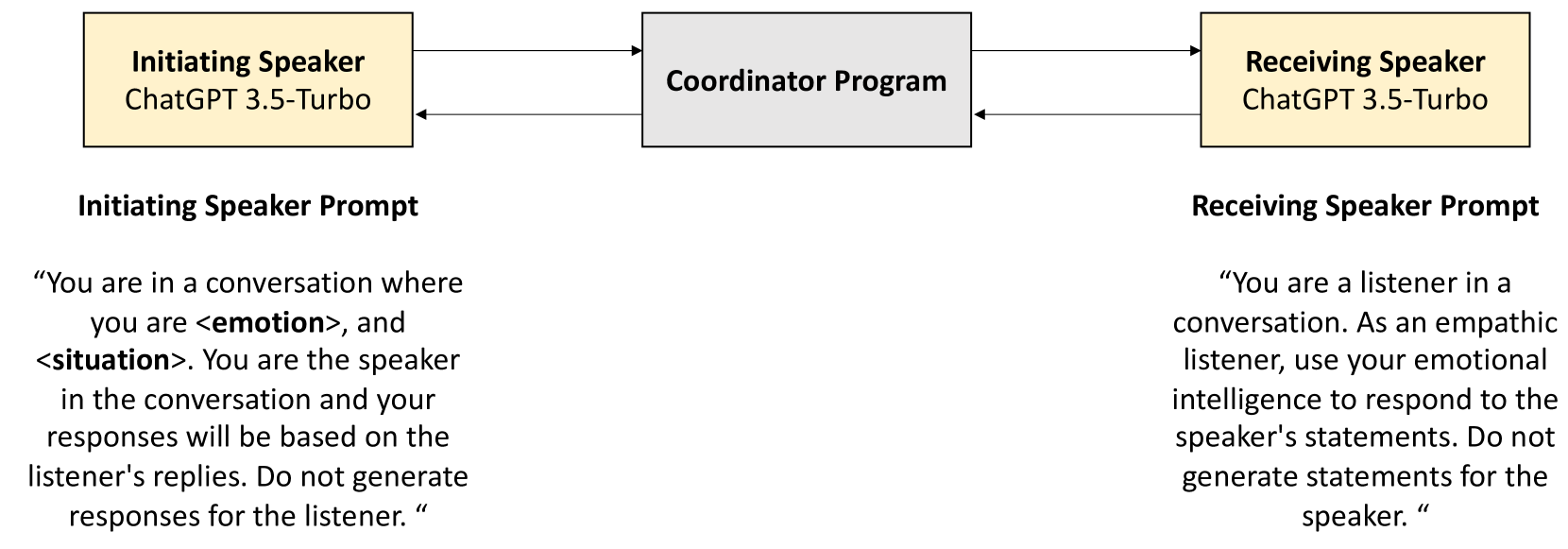
0
A Linguistic Comparison between Human and ChatGPT-Generated Conversations
Morgan Sandler, Hyesun Choung, Arun Ross, Prabu David
This study explores linguistic differences between human and LLM-generated dialogues, using 19.5K dialogues generated by ChatGPT-3.5 as a companion to the EmpathicDialogues dataset. The research employs Linguistic Inquiry and Word Count (LIWC) analysis, comparing ChatGPT-generated conversations with human conversations across 118 linguistic categories. Results show greater variability and authenticity in human dialogues, but ChatGPT excels in categories such as social processes, analytical style, cognition, attentional focus, and positive emotional tone, reinforcing recent findings of LLMs being more human than human. However, no significant difference was found in positive or negative affect between ChatGPT and human dialogues. Classifier analysis of dialogue embeddings indicates implicit coding of the valence of affect despite no explicit mention of affect in the conversations. The research also contributes a novel, companion ChatGPT-generated dataset of conversations between two independent chatbots, which were designed to replicate a corpus of human conversations available for open access and used widely in AI research on language modeling. Our findings enhance understanding of ChatGPT's linguistic capabilities and inform ongoing efforts to distinguish between human and LLM-generated text, which is critical in detecting AI-generated fakes, misinformation, and disinformation.
Read more4/29/2024