Which Augmentation Should I Use? An Empirical Investigation of Augmentations for Self-Supervised Phonocardiogram Representation Learning
2312.00502
0
0
🔍
Abstract
Despite the recent increase in research activity, deep-learning models have not yet been widely accepted in several real-world settings, such as medicine. The shortage of high-quality annotated data often hinders the development of robust and generalizable models, which do not suffer from degraded effectiveness when presented with out-of-distribution (OOD) datasets. Contrastive Self-Supervised Learning (SSL) offers a potential solution to labeled data scarcity, as it takes advantage of unlabeled data to increase model effectiveness and robustness. However, the selection of appropriate transformations during the learning process is not a trivial task and even breaks down the ability of the network to extract meaningful information. In this research, we propose uncovering the optimal augmentations for applying contrastive learning in 1D phonocardiogram (PCG) classification. We perform an extensive comparative evaluation of a wide range of audio-based augmentations, evaluate models on multiple datasets across downstream tasks, and report on the impact of each augmentation. We demonstrate that depending on its training distribution, the effectiveness of a fully-supervised model can degrade up to 32%, while SSL models only lose up to 10% or even improve in some cases. We argue and experimentally demonstrate that, contrastive SSL pretraining can assist in providing robust classifiers which can generalize to unseen, OOD data, without relying on time- and labor-intensive annotation processes by medical experts. Furthermore, the proposed evaluation protocol sheds light on the most promising and appropriate augmentations for robust PCG signal processing, by calculating their effect size on model training. Finally, we provide researchers and practitioners with a roadmap towards producing robust models for PCG classification, in addition to an open-source codebase for developing novel approaches.
Create account to get full access
Overview
- Deep learning models have not yet been widely adopted in real-world settings like medicine due to a lack of high-quality annotated data.
- Contrastive Self-Supervised Learning (SSL) can leverage unlabeled data to improve model effectiveness and robustness, but selecting the right data transformations is challenging.
- This research proposes finding the optimal data augmentations for applying contrastive learning to 1D phonocardiogram (PCG) classification.
Plain English Explanation
Deep learning models, which are a type of artificial intelligence, have not been widely used in important real-world applications like healthcare. This is often due to a lack of high-quality labeled data - information that has been carefully categorized by human experts.
Without enough labeled data, deep learning models can struggle to make accurate predictions, especially when faced with new, previously unseen data. Contrastive Self-Supervised Learning (SSL) offers a potential solution by using unlabeled data to help the model learn general patterns and become more robust. However, the process of selecting the right data transformations, or changes, to apply during this self-supervised learning can be tricky and can even reduce the model's ability to extract meaningful information.
In this research, the authors set out to find the best data transformations, or "augmentations," to use when applying contrastive learning to the task of classifying 1D phonocardiogram (PCG) signals. PCG signals are recordings of the sounds made by the heart, and this type of data is commonly used in medical diagnosis. The researchers extensively tested a wide range of audio-based data augmentations to see how they affected the model's performance on both in-distribution and out-of-distribution (OOD) datasets.
Technical Explanation
The researchers conducted a comprehensive evaluation of various audio-based data augmentations for applying contrastive Self-Supervised Learning (SSL) to 1D phonocardiogram (PCG) classification. They tested the impact of different augmentations, such as pitch shifting, time stretching, and noise injection, on the model's performance on both in-distribution and out-of-distribution (OOD) datasets.
The results showed that a fully-supervised model's effectiveness can degrade by up to 32% when faced with OOD data, while the SSL models only lost up to 10% performance or even improved in some cases. This demonstrates that contrastive SSL pretraining can help produce more robust and generalizable classifiers that can handle unseen data, without relying on extensive manual annotation by medical experts.
The researchers also provide a detailed evaluation protocol that sheds light on the most promising and appropriate data augmentations for robust PCG signal processing. By calculating the effect size of each augmentation on model training, they were able to identify the most effective transformations.
Finally, the authors provide researchers and practitioners with a roadmap for developing robust models for PCG classification, along with an open-source codebase for exploring new approaches.
Critical Analysis
The research presents a thorough evaluation of data augmentation techniques for contrastive SSL in the context of PCG classification, which is an important real-world application. The authors make a compelling case for the benefits of SSL in improving model robustness and generalization, especially when dealing with the challenge of limited labeled data in medical domains.
However, the paper does not address some potential limitations of the study. For example, it is unclear how the specific choice of PCG datasets and tasks may have influenced the results, and whether the findings would generalize to other medical imaging or signal processing domains. Additionally, the impact of various architectural choices and hyperparameter tuning on the SSL performance is not explored in depth.
Further research could investigate the generalizability of the proposed approach across a wider range of medical applications, as well as explore more advanced SSL techniques, such as prompt-based pseudo-labeling strategies or contrastive credibility propagation, to improve sample efficiency and robustness even further.
Conclusion
This research highlights the potential of contrastive Self-Supervised Learning (SSL) to address the challenge of limited labeled data in real-world applications, such as medical diagnosis using phonocardiogram (PCG) signals. By systematically evaluating a wide range of data augmentation techniques, the authors demonstrate that SSL can help produce more robust and generalizable models that are less susceptible to performance degradation when faced with out-of-distribution data.
The study provides valuable insights and a roadmap for researchers and practitioners working on developing effective and reliable deep learning models for PCG classification and other medical signal processing tasks. The open-source codebase shared by the authors further facilitates the exploration and adoption of these techniques by the broader community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
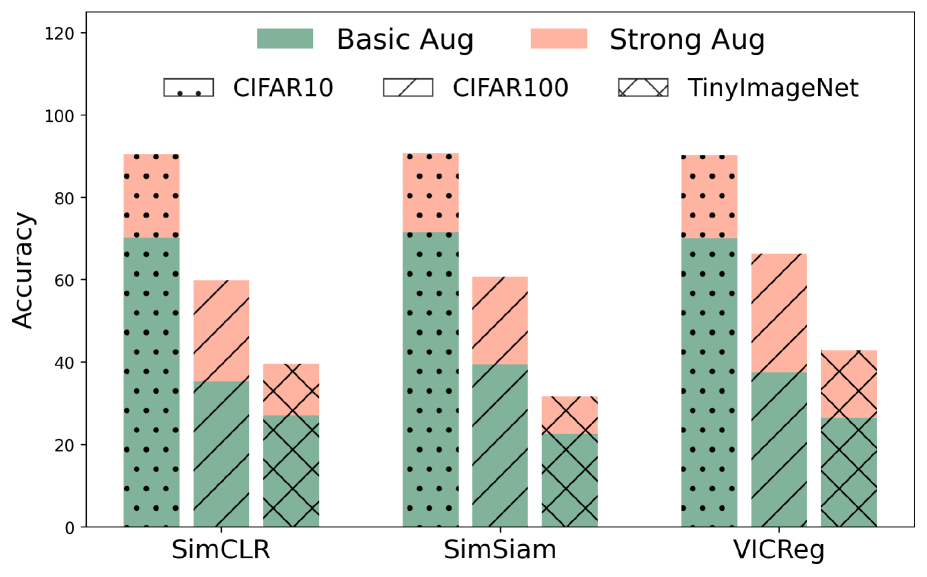
Can We Break Free from Strong Data Augmentations in Self-Supervised Learning?
Shruthi Gowda, Elahe Arani, Bahram Zonooz
0
0
Self-supervised learning (SSL) has emerged as a promising solution for addressing the challenge of limited labeled data in deep neural networks (DNNs), offering scalability potential. However, the impact of design dependencies within the SSL framework remains insufficiently investigated. In this study, we comprehensively explore SSL behavior across a spectrum of augmentations, revealing their crucial role in shaping SSL model performance and learning mechanisms. Leveraging these insights, we propose a novel learning approach that integrates prior knowledge, with the aim of curtailing the need for extensive data augmentations and thereby amplifying the efficacy of learned representations. Notably, our findings underscore that SSL models imbued with prior knowledge exhibit reduced texture bias, diminished reliance on shortcuts and augmentations, and improved robustness against both natural and adversarial corruptions. These findings not only illuminate a new direction in SSL research, but also pave the way for enhancing DNN performance while concurrently alleviating the imperative for intensive data augmentation, thereby enhancing scalability and real-world problem-solving capabilities.
4/16/2024

Can Generative Models Improve Self-Supervised Representation Learning?
Sana Ayromlou, Arash Afkanpour, Vahid Reza Khazaie, Fereshteh Forghani
0
0
The rapid advancement in self-supervised learning (SSL) has highlighted its potential to leverage unlabeled data for learning rich visual representations. However, the existing SSL techniques, particularly those employing different augmentations of the same image, often rely on a limited set of simple transformations that are not representative of real-world data variations. This constrains the diversity and quality of samples, which leads to sub-optimal representations. In this paper, we introduce a novel framework that enriches the SSL paradigm by utilizing generative models to produce semantically consistent image augmentations. By directly conditioning generative models on a source image representation, our method enables the generation of diverse augmentations while maintaining the semantics of the source image, thus offering a richer set of data for self-supervised learning. Our extensive experimental results on various SSL methods demonstrate that our framework significantly enhances the quality of learned visual representations by up to 10% Top-1 accuracy in downstream tasks. This research demonstrates that incorporating generative models into the SSL workflow opens new avenues for exploring the potential of synthetic data. This development paves the way for more robust and versatile representation learning techniques.
5/28/2024
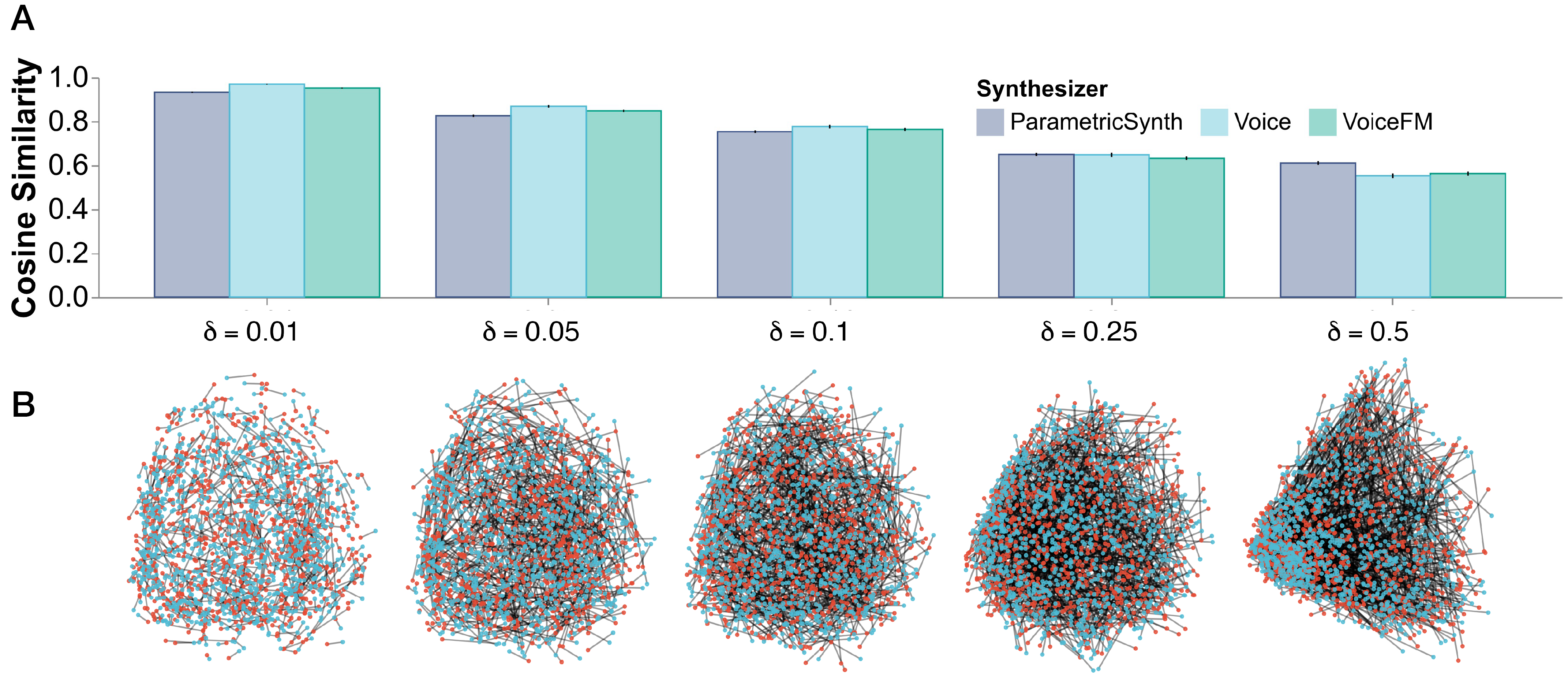
Contrastive Learning from Synthetic Audio Doppelgangers
Manuel Cherep, Nikhil Singh
0
0
Learning robust audio representations currently demands extensive datasets of real-world sound recordings. By applying artificial transformations to these recordings, models can learn to recognize similarities despite subtle variations through techniques like contrastive learning. However, these transformations are only approximations of the true diversity found in real-world sounds, which are generated by complex interactions of physical processes, from vocal cord vibrations to the resonance of musical instruments. We propose a solution to both the data scale and transformation limitations, leveraging synthetic audio. By randomly perturbing the parameters of a sound synthesizer, we generate audio doppelgangers-synthetic positive pairs with causally manipulated variations in timbre, pitch, and temporal envelopes. These variations, difficult to achieve through transformations of existing audio, provide a rich source of contrastive information. Despite the shift to randomly generated synthetic data, our method produces strong representations, competitive with real data on standard audio classification benchmarks. Notably, our approach is lightweight, requires no data storage, and has only a single hyperparameter, which we extensively analyze. We offer this method as a complement to existing strategies for contrastive learning in audio, using synthesized sounds to reduce the data burden on practitioners.
6/11/2024

Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
0
0
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
6/13/2024