Controllable Prompt Tuning For Balancing Group Distributional Robustness

0
Sign in to get full access
Overview
• This paper introduces a novel approach called "Plug-and-Play Prompts" (PaP) for prompt tuning, which aims to improve the controllability and robustness of language models.
• The key idea is to learn a set of prompts that can be "plugged in" to various language models, allowing for fine-grained control over the model's output while maintaining performance on both in-distribution and out-of-distribution tasks.
• The authors also present two related methods, "Robust Prompt Tuning" and "DeCoop," which build upon the PaP framework to further enhance the robustness and controllability of language models.
Plain English Explanation
• Plug-and-Play Prompts (PaP) is a new way to control and customize how language models, like those used in chatbots or text generation, produce their output.
• Typically, language models are trained on a lot of text data and learn patterns, but it can be hard to get them to do exactly what you want. PaP allows you to create "prompts" - short pieces of text that you can plug into the model to guide its output in a specific direction.
• For example, you could create a prompt that makes the model write in a more formal or informal style, or one that steers it towards a particular topic or viewpoint. These prompts can be used across different language models, giving you more control.
• The paper also introduces two related methods, Robust Prompt Tuning and DeCoop, that build on the PaP idea to make the prompts and language models more reliable and less sensitive to changes in the input data.
Technical Explanation
• Plug-and-Play Prompts (PaP) introduces a novel prompt tuning approach that learns a set of prompts that can be "plugged in" to different language models to control their output.
• The key innovation is that the prompts are trained to be model-agnostic, meaning they can be used with various language models without retraining the entire model.
• The authors also present two related methods:
- Robust Prompt Tuning, which trains the prompts to be robust to adversarial perturbations, improving their performance on out-of-distribution tasks.
- DeCoop, which combines prompt tuning with a novel out-of-distribution detection mechanism to further enhance the robustness of the system.
• Experiments on a range of language understanding and generation tasks demonstrate the effectiveness of these approaches in improving the controllability and robustness of language models.
Critical Analysis
• The paper introduces several promising techniques for enhancing the controllability and robustness of language models, which are important for practical applications.
• However, the authors acknowledge that the proposed methods may not be able to fully address the problem of out-of-distribution generalization, as there are inherent limitations to the prompt-based approach.
• Additionally, the paper does not extensively explore the potential ethical implications of having more control over language model outputs, such as the risk of generating biased or manipulative text.
• Further research is needed to better understand the broader implications of these techniques and to explore alternative approaches that may complement or extend the capabilities of prompt-based systems.
Conclusion
• The Plug-and-Play Prompts, Robust Prompt Tuning, and DeCoop methods presented in this paper represent an important step forward in enhancing the controllability and robustness of language models.
• By enabling fine-grained control over model outputs through the use of prompts, these techniques have the potential to improve the reliability and versatility of language-based AI systems, with applications in areas like controllable text generation and federated learning.
• However, further research is needed to fully address the limitations of these approaches and explore the broader implications for AI development and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Controllable Prompt Tuning For Balancing Group Distributional Robustness
Hoang Phan, Andrew Gordon Wilson, Qi Lei
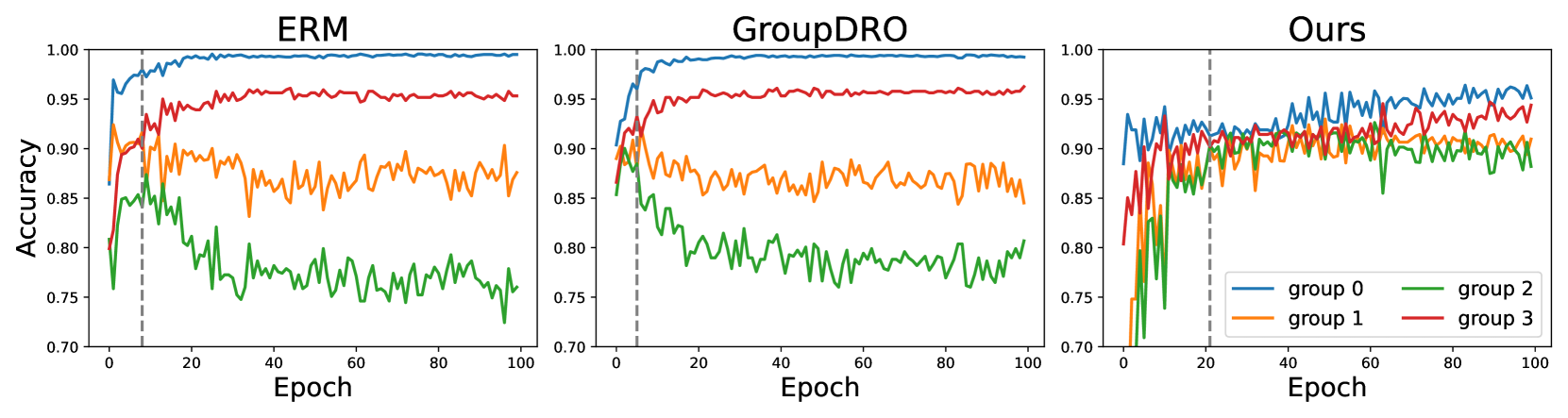
Models trained on data composed of different groups or domains can suffer from severe performance degradation under distribution shifts. While recent methods have largely focused on optimizing the worst-group objective, this often comes at the expense of good performance on other groups. To address this problem, we introduce an optimization scheme to achieve good performance across groups and find a good solution for all without severely sacrificing performance on any of them. However, directly applying such optimization involves updating the parameters of the entire network, making it both computationally expensive and challenging. Thus, we introduce Controllable Prompt Tuning (CPT), which couples our approach with prompt-tuning techniques. On spurious correlation benchmarks, our procedures achieve state-of-the-art results across both transformer and non-transformer architectures, as well as unimodal and multimodal data, while requiring only 0.4% tunable parameters.
Read more6/6/2024
0
Plug and Play with Prompts: A Prompt Tuning Approach for Controlling Text Generation
Rohan Deepak Ajwani, Zining Zhu, Jonathan Rose, Frank Rudzicz
Transformer-based Large Language Models (LLMs) have shown exceptional language generation capabilities in response to text-based prompts. However, controlling the direction of generation via textual prompts has been challenging, especially with smaller models. In this work, we explore the use of Prompt Tuning to achieve controlled language generation. Generated text is steered using prompt embeddings, which are trained using a small language model, used as a discriminator. Moreover, we demonstrate that these prompt embeddings can be trained with a very small dataset, with as low as a few hundred training examples. Our method thus offers a data and parameter efficient solution towards controlling language model outputs. We carry out extensive evaluation on four datasets: SST-5 and Yelp (sentiment analysis), GYAFC (formality) and JIGSAW (toxic language). Finally, we demonstrate the efficacy of our method towards mitigating harmful, toxic, and biased text generated by language models.
Read more4/9/2024

0
Efficient Test-Time Prompt Tuning for Vision-Language Models
Yuhan Zhu, Guozhen Zhang, Chen Xu, Haocheng Shen, Xiaoxin Chen, Gangshan Wu, Limin Wang
Vision-language models have showcased impressive zero-shot classification capabilities when equipped with suitable text prompts. Previous studies have shown the effectiveness of test-time prompt tuning; however, these methods typically require per-image prompt adaptation during inference, which incurs high computational budgets and limits scalability and practical deployment. To overcome this issue, we introduce Self-TPT, a novel framework leveraging Self-supervised learning for efficient Test-time Prompt Tuning. The key aspect of Self-TPT is that it turns to efficient predefined class adaptation via self-supervised learning, thus avoiding computation-heavy per-image adaptation at inference. Self-TPT begins by co-training the self-supervised and the classification task using source data, then applies the self-supervised task exclusively for test-time new class adaptation. Specifically, we propose Contrastive Prompt Learning (CPT) as the key task for self-supervision. CPT is designed to minimize the intra-class distances while enhancing inter-class distinguishability via contrastive learning. Furthermore, empirical evidence suggests that CPT could closely mimic back-propagated gradients of the classification task, offering a plausible explanation for its effectiveness. Motivated by this finding, we further introduce a gradient matching loss to explicitly enhance the gradient similarity. We evaluated Self-TPT across three challenging zero-shot benchmarks. The results consistently demonstrate that Self-TPT not only significantly reduces inference costs but also achieves state-of-the-art performance, effectively balancing the efficiency-efficacy trade-off.
Read more8/13/2024

0
Revisiting the Robust Generalization of Adversarial Prompt Tuning
Fan Yang, Mingxuan Xia, Sangzhou Xia, Chicheng Ma, Hui Hui
Understanding the vulnerability of large-scale pre-trained vision-language models like CLIP against adversarial attacks is key to ensuring zero-shot generalization capacity on various downstream tasks. State-of-the-art defense mechanisms generally adopt prompt learning strategies for adversarial fine-tuning to improve the adversarial robustness of the pre-trained model while keeping the efficiency of adapting to downstream tasks. Such a setup leads to the problem of over-fitting which impedes further improvement of the model's generalization capacity on both clean and adversarial examples. In this work, we propose an adaptive Consistency-guided Adversarial Prompt Tuning (i.e., CAPT) framework that utilizes multi-modal prompt learning to enhance the alignment of image and text features for adversarial examples and leverage the strong generalization of pre-trained CLIP to guide the model-enhancing its robust generalization on adversarial examples while maintaining its accuracy on clean ones. We also design a novel adaptive consistency objective function to balance the consistency of adversarial inputs and clean inputs between the fine-tuning model and the pre-trained model. We conduct extensive experiments across 14 datasets and 4 data sparsity schemes (from 1-shot to full training data settings) to show the superiority of CAPT over other state-of-the-art adaption methods. CAPT demonstrated excellent performance in terms of the in-distribution performance and the generalization under input distribution shift and across datasets.
Read more5/21/2024