Controlling Emotion in Text-to-Speech with Natural Language Prompts
2406.06406
0
0
Abstract
In recent years, prompting has quickly become one of the standard ways of steering the outputs of generative machine learning models, due to its intuitive use of natural language. In this work, we propose a system conditioned on embeddings derived from an emotionally rich text that serves as prompt. Thereby, a joint representation of speaker and prompt embeddings is integrated at several points within a transformer-based architecture. Our approach is trained on merged emotional speech and text datasets and varies prompts in each training iteration to increase the generalization capabilities of the model. Objective and subjective evaluation results demonstrate the ability of the conditioned synthesis system to accurately transfer the emotions present in a prompt to speech. At the same time, precise tractability of speaker identities as well as overall high speech quality and intelligibility are maintained.
Create account to get full access
Overview
This paper explores how natural language prompts can be used to control the emotional expression in text-to-speech (TTS) systems. The researchers propose a "plug-and-play" approach that allows for easy integration of emotional control into TTS models, without requiring extensive retraining. This builds upon previous work on hierarchical emotion prediction and control for TTS and a unified framework for multimodal prompt-induced TTS.
Plain English Explanation
The ability to control the emotional expression in text-to-speech (TTS) systems is important for making AI-generated speech sound more natural and engaging. This paper presents a new method that allows users to adjust the emotional tone of TTS output using simple language prompts.
The key idea is to create a "plug-and-play" system that can be easily integrated with existing TTS models, without requiring extensive retraining. Users can provide short phrases that convey the desired emotional state, such as "speak angrily" or "sound excited." The system then automatically adjusts the acoustic properties of the generated speech to match that emotional tone.
This builds on previous research that has looked at ways to predict and control the emotions expressed in TTS as well as using multimodal prompts to influence TTS. The new approach aims to make it simpler and more accessible for users to customize the emotional expression of TTS output.
Technical Explanation
The paper proposes a "plug-and-play" framework for controlling the emotional expression in text-to-speech (TTS) systems using natural language prompts. The approach involves training a separate emotion prediction model that can map language prompts to target emotional states. This emotion prediction model is then integrated with a pre-trained TTS model, allowing the emotional tone of the generated speech to be adjusted based on the provided prompts.
Specifically, the researchers trained the emotion prediction model on a dataset of emotional speech, learning to associate language prompts with acoustic features like pitch, energy, and speaking rate that convey different emotions. During inference, the emotion prediction model takes a language prompt as input and outputs target emotional features, which are then used to condition the TTS model and generate speech with the desired emotional expression.
The researchers evaluated their approach on a range of language prompts and TTS models, demonstrating that it can effectively control the emotional tone of the generated speech without requiring extensive retraining of the underlying TTS system. This builds on prior work on hierarchical emotion prediction and control for TTS and a unified framework for multimodal prompt-induced TTS, further advancing the state-of-the-art in emotional speech synthesis.
Critical Analysis
The proposed approach for controlling emotion in text-to-speech using natural language prompts is a promising step forward, but there are some potential limitations and areas for further research.
One key limitation is that the emotion prediction model was trained on a specific dataset of emotional speech, which may not fully capture the nuance and complexity of human emotional expression. There is a risk that the system could struggle to generalize to more diverse or subtle emotional tones. Further research is needed to explore how well the approach works across a wider range of emotional states and speaking styles.
Additionally, the paper does not address potential biases or fairness issues that could arise from the emotion prediction model. There is a risk that the system could perpetuate or amplify societal biases around emotional expression, for example by associating certain emotions with particular demographic groups. Careful consideration of these ethical concerns is important as this technology is developed further.
Despite these caveats, the core idea of using natural language prompts to easily control the emotional expression of TTS is a valuable contribution. The research on the usefulness of emotional prosody in neural machine translation suggests that this could have important applications in enhancing the naturalness and engagement of AI-generated speech. As the field of generative AI continues to advance, techniques like this for imbuing synthetic speech with appropriate emotional nuance will likely become increasingly important.
Conclusion
This paper presents a novel approach for controlling the emotional expression in text-to-speech (TTS) systems using natural language prompts. By training a separate emotion prediction model and integrating it with a pre-trained TTS system, the researchers have developed a "plug-and-play" framework that allows users to easily adjust the emotional tone of the generated speech.
This work builds upon previous research on emotion prediction and control for TTS, as well as the use of multimodal prompts to influence speech synthesis. While there are some potential limitations and areas for further investigation, the core idea of using language prompts to shape the emotional expression of TTS is a valuable contribution that could have important applications as generative AI systems become more widespread and sophisticated.
Overall, this paper demonstrates the potential for language-based control of emotional expression in text-to-speech, paving the way for more natural and engaging AI-generated speech in a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
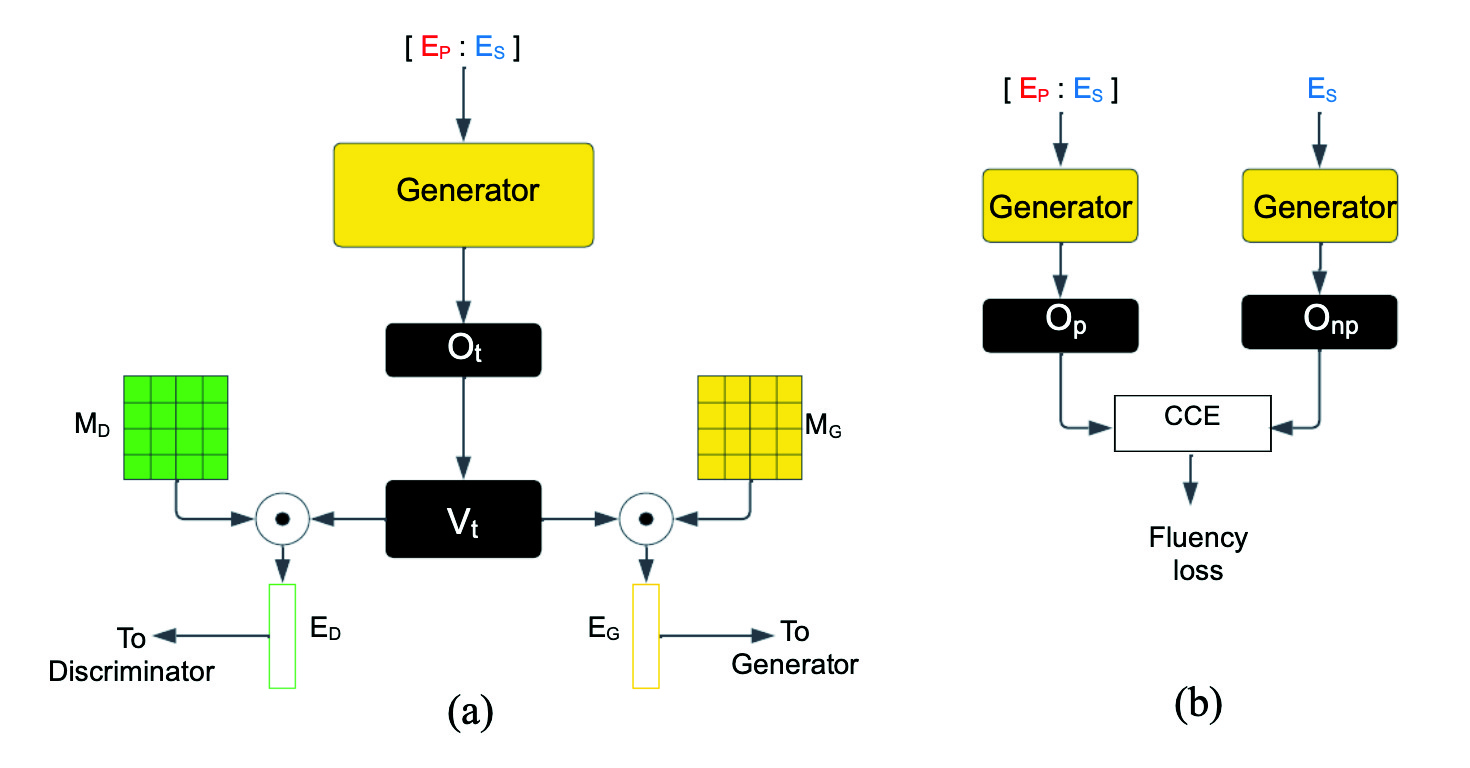
Plug and Play with Prompts: A Prompt Tuning Approach for Controlling Text Generation
Rohan Deepak Ajwani, Zining Zhu, Jonathan Rose, Frank Rudzicz
0
0
Transformer-based Large Language Models (LLMs) have shown exceptional language generation capabilities in response to text-based prompts. However, controlling the direction of generation via textual prompts has been challenging, especially with smaller models. In this work, we explore the use of Prompt Tuning to achieve controlled language generation. Generated text is steered using prompt embeddings, which are trained using a small language model, used as a discriminator. Moreover, we demonstrate that these prompt embeddings can be trained with a very small dataset, with as low as a few hundred training examples. Our method thus offers a data and parameter efficient solution towards controlling language model outputs. We carry out extensive evaluation on four datasets: SST-5 and Yelp (sentiment analysis), GYAFC (formality) and JIGSAW (toxic language). Finally, we demonstrate the efficacy of our method towards mitigating harmful, toxic, and biased text generated by language models.
4/9/2024
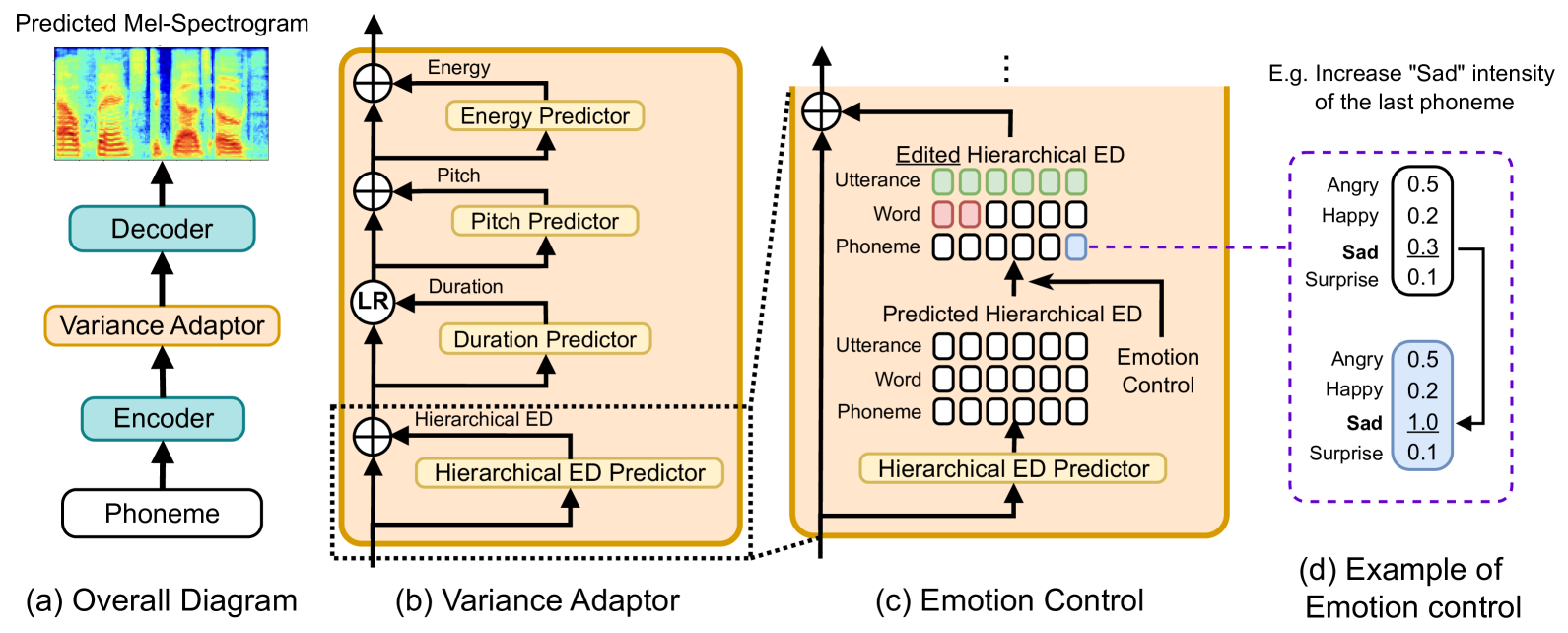
Hierarchical Emotion Prediction and Control in Text-to-Speech Synthesis
Sho Inoue, Kun Zhou, Shuai Wang, Haizhou Li
0
0
It remains a challenge to effectively control the emotion rendering in text-to-speech (TTS) synthesis. Prior studies have primarily focused on learning a global prosodic representation at the utterance level, which strongly correlates with linguistic prosody. Our goal is to construct a hierarchical emotion distribution (ED) that effectively encapsulates intensity variations of emotions at various levels of granularity, encompassing phonemes, words, and utterances. During TTS training, the hierarchical ED is extracted from the ground-truth audio and guides the predictor to establish a connection between emotional and linguistic prosody. At run-time inference, the TTS model generates emotional speech and, at the same time, provides quantitative control of emotion over the speech constituents. Both objective and subjective evaluations validate the effectiveness of the proposed framework in terms of emotion prediction and control.
5/16/2024
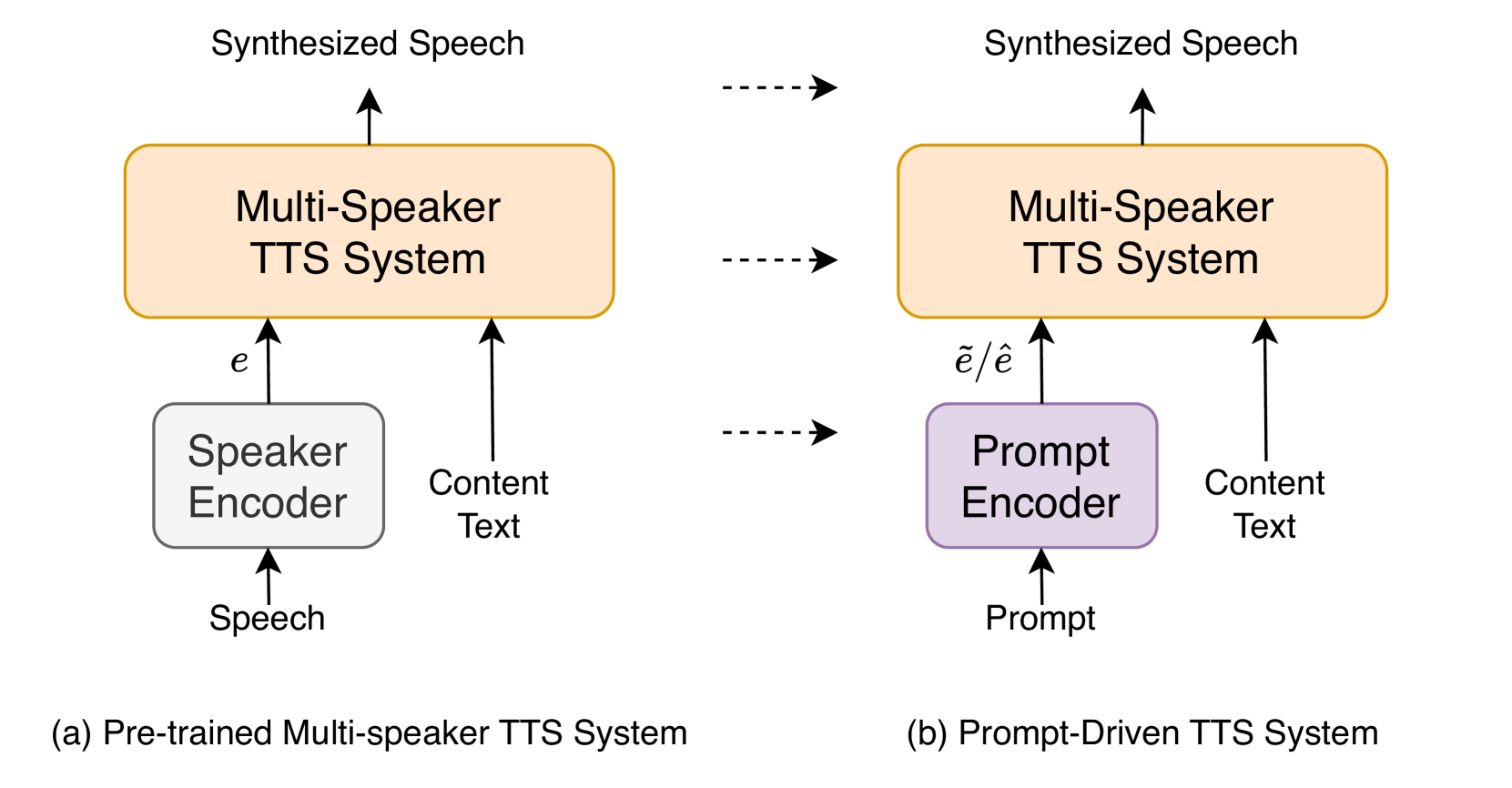
Generating Speakers by Prompting Listener Impressions for Pre-trained Multi-Speaker Text-to-Speech Systems
Zhengyang Chen, Xuechen Liu, Erica Cooper, Junichi Yamagishi, Yanmin Qian
0
0
This paper proposes a speech synthesis system that allows users to specify and control the acoustic characteristics of a speaker by means of prompts describing the speaker's traits of synthesized speech. Unlike previous approaches, our method utilizes listener impressions to construct prompts, which are easier to collect and align more naturally with everyday descriptions of speaker traits. We adopt the Low-rank Adaptation (LoRA) technique to swiftly tailor a pre-trained language model to our needs, facilitating the extraction of speaker-related traits from the prompt text. Besides, different from other prompt-driven text-to-speech (TTS) systems, we separate the prompt-to-speaker module from the multi-speaker TTS system, enhancing system flexibility and compatibility with various pre-trained multi-speaker TTS systems. Moreover, for the prompt-to-speaker characteristic module, we also compared the discriminative method and flow-matching based generative method and we found that combining both methods can help the system simultaneously capture speaker-related information from prompts better and generate speech with higher fidelity.
6/14/2024
❗
MM-TTS: A Unified Framework for Multimodal, Prompt-Induced Emotional Text-to-Speech Synthesis
Xiang Li, Zhi-Qi Cheng, Jun-Yan He, Xiaojiang Peng, Alexander G. Hauptmann
0
0
Emotional Text-to-Speech (E-TTS) synthesis has gained significant attention in recent years due to its potential to enhance human-computer interaction. However, current E-TTS approaches often struggle to capture the complexity of human emotions, primarily relying on oversimplified emotional labels or single-modality inputs. To address these limitations, we propose the Multimodal Emotional Text-to-Speech System (MM-TTS), a unified framework that leverages emotional cues from multiple modalities to generate highly expressive and emotionally resonant speech. MM-TTS consists of two key components: (1) the Emotion Prompt Alignment Module (EP-Align), which employs contrastive learning to align emotional features across text, audio, and visual modalities, ensuring a coherent fusion of multimodal information; and (2) the Emotion Embedding-Induced TTS (EMI-TTS), which integrates the aligned emotional embeddings with state-of-the-art TTS models to synthesize speech that accurately reflects the intended emotions. Extensive evaluations across diverse datasets demonstrate the superior performance of MM-TTS compared to traditional E-TTS models. Objective metrics, including Word Error Rate (WER) and Character Error Rate (CER), show significant improvements on ESD dataset, with MM-TTS achieving scores of 7.35% and 3.07%, respectively. Subjective assessments further validate that MM-TTS generates speech with emotional fidelity and naturalness comparable to human speech. Our code and pre-trained models are publicly available at https://anonymous.4open.science/r/MMTTS-D214
4/30/2024