Generating Speakers by Prompting Listener Impressions for Pre-trained Multi-Speaker Text-to-Speech Systems
2406.08812
0
0
Abstract
This paper proposes a speech synthesis system that allows users to specify and control the acoustic characteristics of a speaker by means of prompts describing the speaker's traits of synthesized speech. Unlike previous approaches, our method utilizes listener impressions to construct prompts, which are easier to collect and align more naturally with everyday descriptions of speaker traits. We adopt the Low-rank Adaptation (LoRA) technique to swiftly tailor a pre-trained language model to our needs, facilitating the extraction of speaker-related traits from the prompt text. Besides, different from other prompt-driven text-to-speech (TTS) systems, we separate the prompt-to-speaker module from the multi-speaker TTS system, enhancing system flexibility and compatibility with various pre-trained multi-speaker TTS systems. Moreover, for the prompt-to-speaker characteristic module, we also compared the discriminative method and flow-matching based generative method and we found that combining both methods can help the system simultaneously capture speaker-related information from prompts better and generate speech with higher fidelity.
Create account to get full access
Overview
- This paper proposes a method for generating new speakers in pre-trained multi-speaker text-to-speech (TTS) systems by prompting the system with listener impressions.
- The approach allows for the creation of diverse and customized voices without the need for time-consuming speaker recordings.
- The authors demonstrate the effectiveness of their method on several pre-trained TTS models, showing that it can generate speakers with distinct vocal characteristics.
Plain English Explanation
The research in this paper focuses on a way to create new speakers for text-to-speech (TTS) systems without having to record lots of audio data for each new voice. TTS systems are AI models that can convert written text into spoken audio. Many TTS systems are trained on recordings from multiple speakers, allowing them to produce speech in different voices.
However, adding new speakers to a TTS system usually requires collecting and annotating a large amount of audio data for that speaker, which can be time-consuming and expensive. The researchers in this paper propose a solution to this problem. They show that you can generate new speakers for a pre-trained TTS system by simply providing a short text prompt that describes the desired voice characteristics, such as age, gender, and personality.
The key insight is that the TTS model can learn to associate these listener impressions with the acoustic features of different speakers. By prompting the model with the desired voice traits, it can then generate a new speaker that matches those characteristics. The authors demonstrate that this approach works well across several existing TTS models, allowing for the creation of diverse and customized voices without the need for extensive speaker recordings.
This approach complements other research on enhancing TTS systems by giving users more control over the generated speech, such as emotion and style. The ability to easily create new speakers expands the potential applications of TTS technology, making it more accessible and adaptable to different user needs.
Technical Explanation
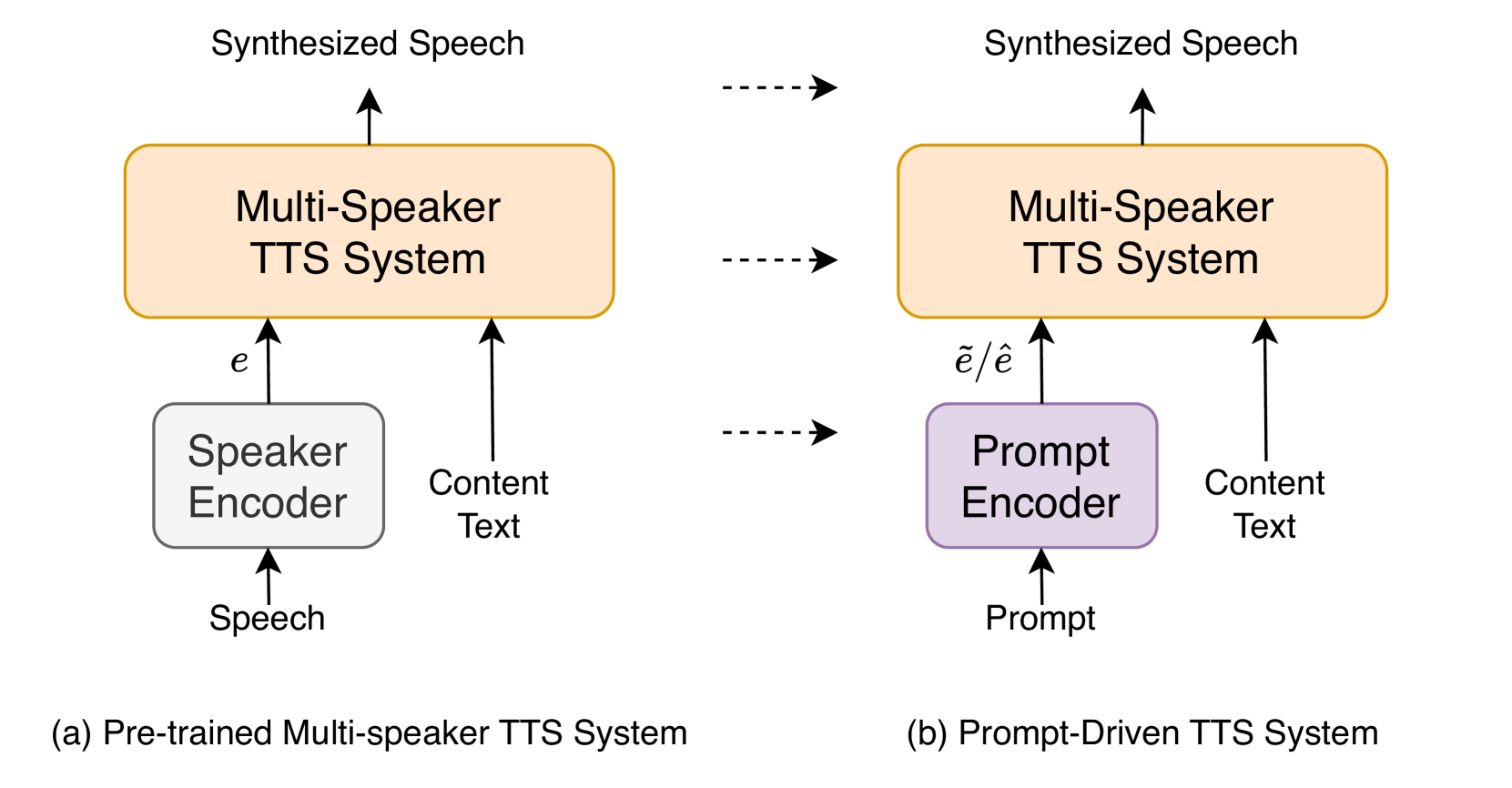
The researchers propose a method called "Prompt-driven Speaker Generation" that allows for the creation of new speakers in pre-trained multi-speaker TTS systems. The key idea is to use a short text prompt that describes the desired voice characteristics, such as age, gender, and personality, to generate a new speaker with those traits.
The approach works by leveraging the pre-trained TTS model's ability to associate acoustic features with different speakers. The researchers fine-tune the model using a dataset of speaker impressions, where each sample consists of a short text prompt paired with the acoustic features of a corresponding speaker. This training teaches the model to map the textual descriptions of voice characteristics to the associated voice patterns.
During inference, the fine-tuned model can then generate a new speaker by taking in a prompt describing the desired voice and producing the corresponding acoustic features. The authors demonstrate this approach on several pre-trained TTS models, including Plug-and-Play Prompts and MEGA-TTS, showing that it can generate speakers with distinct vocal characteristics.
The proposed method addresses the challenge of expanding the speaker diversity of TTS systems without the need for extensive speaker recordings. By allowing users to create new speakers through simple text prompts, it enhances the customizability and accessibility of TTS technology. This complements other research on controlling the emotional expression and general-purpose prompting of TTS systems, further expanding the possibilities for personalized and expressive synthetic speech.
Critical Analysis
The proposed "Prompt-driven Speaker Generation" method is a promising approach for enhancing the speaker diversity of pre-trained multi-speaker TTS systems. By leveraging text prompts to generate new speakers, the technique addresses the challenge of requiring extensive speaker recordings for each new voice.
One potential limitation of the method is the reliance on a dataset of speaker impressions for fine-tuning the TTS model. The quality and diversity of the training data may impact the model's ability to generate a wide range of new speakers. Additionally, the authors acknowledge that the generated speakers may not perfectly match the desired voice characteristics, and further research is needed to improve the fidelity of the generated voices.
Another area for further exploration is the generalization of the approach to more diverse speaker characteristics, such as accents, emotions, and speaking styles. While the paper demonstrates the method's effectiveness on several pre-trained TTS models, it would be valuable to investigate its performance across a broader range of TTS architectures and use cases.
Overall, the research presented in this paper represents an important step towards more customizable and accessible TTS systems. By empowering users to create new speakers through simple text prompts, the proposed method has the potential to enable a wide range of applications, from personalized digital assistants to audiobook narration. As the field of TTS continues to evolve, this work and similar approaches may pave the way for a future where synthetic speech can be tailored to the unique needs and preferences of individual users.
Conclusion
This research paper introduces a novel method called "Prompt-driven Speaker Generation" that allows for the creation of new speakers in pre-trained multi-speaker text-to-speech (TTS) systems. By fine-tuning the TTS model to associate textual descriptions of voice characteristics with the corresponding acoustic features, the approach enables the generation of diverse and customized speakers without the need for extensive speaker recordings.
The authors demonstrate the effectiveness of their method on several pre-trained TTS models, showing that it can generate speakers with distinct vocal characteristics. This work complements other research on enhancing TTS systems, such as controlling emotion and using general-purpose prompting, further expanding the possibilities for personalized and expressive synthetic speech.
While the proposed method has some limitations and areas for further exploration, it represents an important step towards more accessible and customizable TTS technology. As the field continues to evolve, this research may pave the way for a future where users can easily create new speakers tailored to their specific needs and preferences, unlocking a wide range of applications in areas like digital assistants, audiobook narration, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024
Controlling Emotion in Text-to-Speech with Natural Language Prompts
Thomas Bott, Florian Lux, Ngoc Thang Vu
0
0
In recent years, prompting has quickly become one of the standard ways of steering the outputs of generative machine learning models, due to its intuitive use of natural language. In this work, we propose a system conditioned on embeddings derived from an emotionally rich text that serves as prompt. Thereby, a joint representation of speaker and prompt embeddings is integrated at several points within a transformer-based architecture. Our approach is trained on merged emotional speech and text datasets and varies prompts in each training iteration to increase the generalization capabilities of the model. Objective and subjective evaluation results demonstrate the ability of the conditioned synthesis system to accurately transfer the emotions present in a prompt to speech. At the same time, precise tractability of speaker identities as well as overall high speech quality and intelligibility are maintained.
6/13/2024
🗣️
Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, Zhou Zhao
0
0
Zero-shot text-to-speech (TTS) aims to synthesize voices with unseen speech prompts, which significantly reduces the data and computation requirements for voice cloning by skipping the fine-tuning process. However, the prompting mechanisms of zero-shot TTS still face challenges in the following aspects: 1) previous works of zero-shot TTS are typically trained with single-sentence prompts, which significantly restricts their performance when the data is relatively sufficient during the inference stage. 2) The prosodic information in prompts is highly coupled with timbre, making it untransferable to each other. This paper introduces Mega-TTS 2, a generic prompting mechanism for zero-shot TTS, to tackle the aforementioned challenges. Specifically, we design a powerful acoustic autoencoder that separately encodes the prosody and timbre information into the compressed latent space while providing high-quality reconstructions. Then, we propose a multi-reference timbre encoder and a prosody latent language model (P-LLM) to extract useful information from multi-sentence prompts. We further leverage the probabilities derived from multiple P-LLM outputs to produce transferable and controllable prosody. Experimental results demonstrate that Mega-TTS 2 could not only synthesize identity-preserving speech with a short prompt of an unseen speaker from arbitrary sources but consistently outperform the fine-tuning method when the volume of data ranges from 10 seconds to 5 minutes. Furthermore, our method enables to transfer various speaking styles to the target timbre in a fine-grained and controlled manner. Audio samples can be found in https://boostprompt.github.io/boostprompt/.
4/11/2024
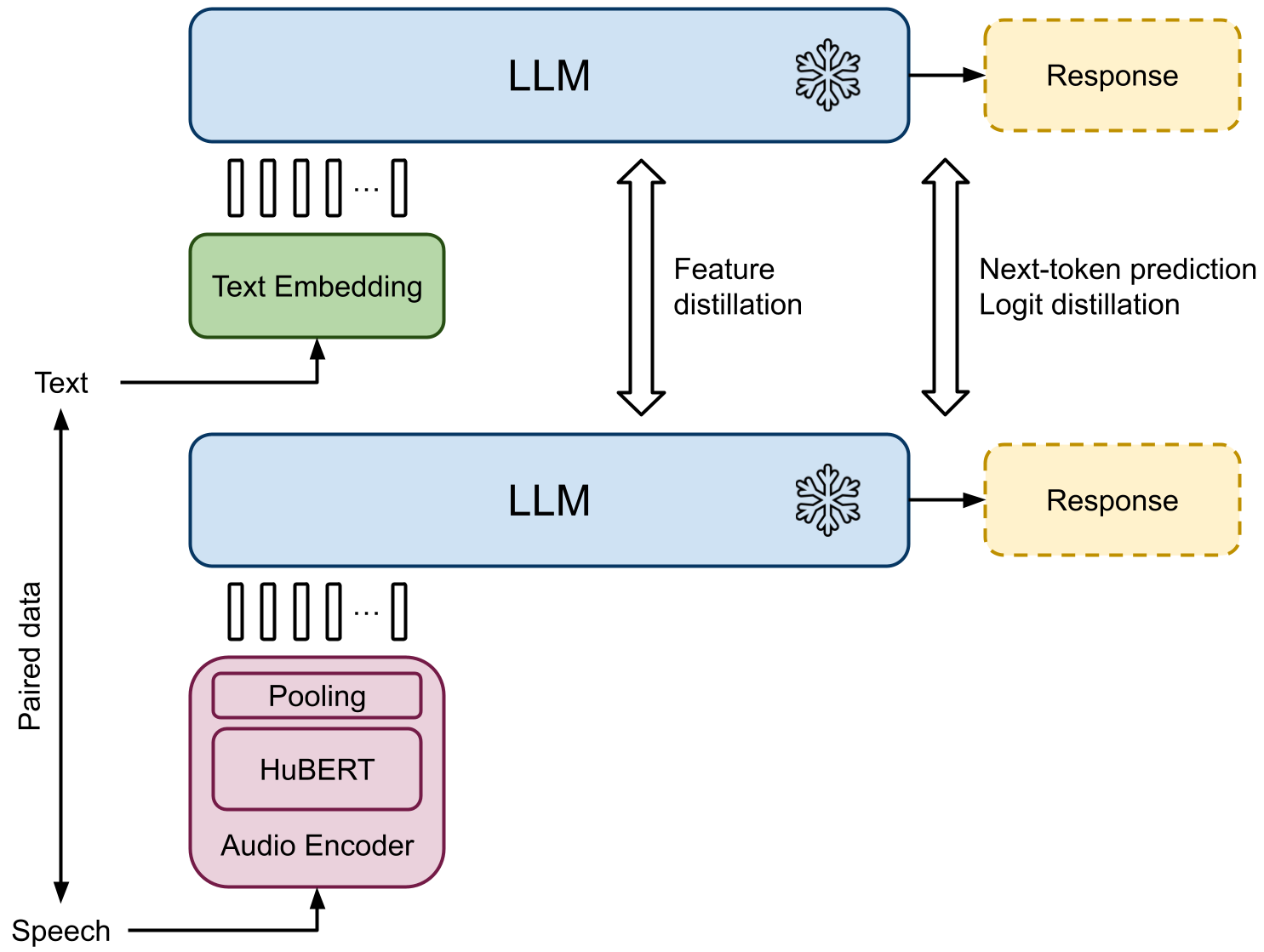
Prompting Large Language Models with Audio for General-Purpose Speech Summarization
Wonjune Kang, Deb Roy
0
0
In this work, we introduce a framework for speech summarization that leverages the processing and reasoning capabilities of large language models (LLMs). We propose an end-to-end system that combines an instruction-tuned LLM with an audio encoder that converts speech into token representations that the LLM can interpret. Using a dataset with paired speech-text data, the overall system is trained to generate consistent responses to prompts with the same semantic information regardless of the input modality. The resulting framework allows the LLM to process speech inputs in the same way as text, enabling speech summarization by simply prompting the LLM. Unlike prior approaches, our method is able to summarize spoken content from any arbitrary domain, and it can produce summaries in different styles by varying the LLM prompting strategy. Experiments demonstrate that our approach outperforms a cascade baseline of speech recognition followed by LLM text processing.
6/11/2024