Convergence Analysis of Flow Matching in Latent Space with Transformers
2404.02538
0
0
🧪
Abstract
We present theoretical convergence guarantees for ODE-based generative models, specifically flow matching. We use a pre-trained autoencoder network to map high-dimensional original inputs to a low-dimensional latent space, where a transformer network is trained to predict the velocity field of the transformation from a standard normal distribution to the target latent distribution. Our error analysis demonstrates the effectiveness of this approach, showing that the distribution of samples generated via estimated ODE flow converges to the target distribution in the Wasserstein-2 distance under mild and practical assumptions. Furthermore, we show that arbitrary smooth functions can be effectively approximated by transformer networks with Lipschitz continuity, which may be of independent interest.
Create account to get full access
Overview
- The paper presents theoretical guarantees for the convergence of ODE-based generative models, specifically flow matching.
- The researchers use a pre-trained autoencoder network to map high-dimensional inputs to a low-dimensional latent space, and then train a transformer network to predict the velocity field of the transformation from a standard normal distribution to the target latent distribution.
- The error analysis demonstrates the effectiveness of this approach, showing that the distribution of generated samples converges to the target distribution under mild and practical assumptions.
- The paper also shows that arbitrary smooth functions can be effectively approximated by transformer networks with Lipschitz continuity.
Plain English Explanation
The paper describes a new way to generate realistic-looking data, such as images or text, by using a pre-trained autoencoder network and a transformer network. The autoencoder maps the original high-dimensional data (like images) to a low-dimensional "latent space," which is a simpler, more compact representation of the data. Then, the transformer network is trained to predict how the data should move and change within this latent space to match the target distribution, which could be real-world data like natural images.
The key insight is that this process can be modeled as an "ordinary differential equation" (ODE), which describes how the data evolves over time. The researchers prove that, under reasonable assumptions, the generated samples will converge to the target distribution, meaning the generated data will become increasingly similar to the real data. Additionally, they show that the transformer network can effectively approximate any smooth function, which is a powerful mathematical property.
This approach is exciting because it provides a principled way to generate high-quality, realistic-looking data without having to manually design complex generative models. By leveraging pre-trained networks and ODEs, the method can potentially be applied to a wide range of data types and tasks, such as generating natural images, realistic text, or simulated physical systems.
Technical Explanation
The paper proposes a novel framework for ODE-based generative modeling, specifically focusing on the flow matching problem. The core idea is to use a pre-trained autoencoder network to map high-dimensional original inputs (e.g., images) to a low-dimensional latent space. Then, a transformer network is trained to predict the velocity field of the transformation from a standard normal distribution to the target latent distribution.
The researchers provide a detailed error analysis, demonstrating that the distribution of generated samples via the estimated ODE flow converges to the target distribution in the Wasserstein-2 distance under mild and practical assumptions. This means that as the model training progresses, the generated samples become increasingly similar to the real data.
Furthermore, the paper shows that arbitrary smooth functions can be effectively approximated by transformer networks with Lipschitz continuity. This is an important result, as it suggests that the transformer network can capture a wide range of complex, non-linear transformations required for effective generative modeling.
The proposed approach has several advantages: it leverages pre-trained networks to simplify the generative modeling task, it provides theoretical convergence guarantees, and it can potentially be applied to a wide range of data types and tasks beyond just image generation.
Critical Analysis
The paper presents a well-designed and theoretically grounded framework for ODE-based generative modeling. The convergence guarantees and the ability to approximate arbitrary smooth functions are significant theoretical contributions.
However, the paper does not address some potential limitations of the approach. For example, it is unclear how the method would scale to high-dimensional or complex data distributions, as the error analysis and convergence rates may degrade with increasing dimensionality. Additionally, the paper does not discuss the computational efficiency of the approach, which could be a practical concern for real-world applications.
Furthermore, the paper does not provide a comprehensive comparison to other state-of-the-art generative modeling techniques, such as variational autoencoders or generative adversarial networks. A more thorough empirical evaluation and benchmarking against these methods would help to situate the proposed approach within the broader context of generative modeling research.
Despite these limitations, the paper presents a promising direction for ODE-based generative modeling and opens up avenues for further research in this area. Exploring the scalability, computational efficiency, and practical applications of the proposed framework could be valuable directions for future work.
Conclusion
The paper introduces a novel ODE-based generative modeling framework that leverages pre-trained autoencoder and transformer networks. The theoretical convergence guarantees and the ability to approximate arbitrary smooth functions are important contributions that could have significant implications for the field of generative modeling.
While the paper does not address all potential limitations of the approach, it presents a well-designed and theoretically grounded framework that could be a valuable addition to the toolbox of generative modeling techniques. Further research on the scalability, computational efficiency, and practical applications of this approach could help to unlock its full potential and drive progress in the generation of high-quality, realistic-looking data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Flow Map Matching
Nicholas M. Boffi, Michael S. Albergo, Eric Vanden-Eijnden
0
0
Generative models based on dynamical transport of measure, such as diffusion models, flow matching models, and stochastic interpolants, learn an ordinary or stochastic differential equation whose trajectories push initial conditions from a known base distribution onto the target. While training is cheap, samples are generated via simulation, which is more expensive than one-step models like GANs. To close this gap, we introduce flow map matching -- an algorithm that learns the two-time flow map of an underlying ordinary differential equation. The approach leads to an efficient few-step generative model whose step count can be chosen a-posteriori to smoothly trade off accuracy for computational expense. Leveraging the stochastic interpolant framework, we introduce losses for both direct training of flow maps and distillation from pre-trained (or otherwise known) velocity fields. Theoretically, we show that our approach unifies many existing few-step generative models, including consistency models, consistency trajectory models, progressive distillation, and neural operator approaches, which can be obtained as particular cases of our formalism. With experiments on CIFAR-10 and ImageNet 32x32, we show that flow map matching leads to high-quality samples with significantly reduced sampling cost compared to diffusion or stochastic interpolant methods.
6/12/2024
Flow matching achieves minimax optimal convergence
Kenji Fukumizu, Taiji Suzuki, Noboru Isobe, Kazusato Oko, Masanori Koyama
0
0
Flow matching (FM) has gained significant attention as a simulation-free generative model. Unlike diffusion models, which are based on stochastic differential equations, FM employs a simpler approach by solving an ordinary differential equation with an initial condition from a normal distribution, thus streamlining the sample generation process. This paper discusses the convergence properties of FM in terms of the $p$-Wasserstein distance, a measure of distributional discrepancy. We establish that FM can achieve the minmax optimal convergence rate for $1 leq p leq 2$, presenting the first theoretical evidence that FM can reach convergence rates comparable to those of diffusion models. Our analysis extends existing frameworks by examining a broader class of mean and variance functions for the vector fields and identifies specific conditions necessary to attain these optimal rates.
6/3/2024
🤔
Convergence of flow-based generative models via proximal gradient descent in Wasserstein space
Xiuyuan Cheng, Jianfeng Lu, Yixin Tan, Yao Xie
0
0
Flow-based generative models enjoy certain advantages in computing the data generation and the likelihood, and have recently shown competitive empirical performance. Compared to the accumulating theoretical studies on related score-based diffusion models, analysis of flow-based models, which are deterministic in both forward (data-to-noise) and reverse (noise-to-data) directions, remain sparse. In this paper, we provide a theoretical guarantee of generating data distribution by a progressive flow model, the so-called JKO flow model, which implements the Jordan-Kinderleherer-Otto (JKO) scheme in a normalizing flow network. Leveraging the exponential convergence of the proximal gradient descent (GD) in Wasserstein space, we prove the Kullback-Leibler (KL) guarantee of data generation by a JKO flow model to be $O(varepsilon^2)$ when using $N lesssim log (1/varepsilon)$ many JKO steps ($N$ Residual Blocks in the flow) where $varepsilon $ is the error in the per-step first-order condition. The assumption on data density is merely a finite second moment, and the theory extends to data distributions without density and when there are inversion errors in the reverse process where we obtain KL-$W_2$ mixed error guarantees. The non-asymptotic convergence rate of the JKO-type $W_2$-proximal GD is proved for a general class of convex objective functionals that includes the KL divergence as a special case, which can be of independent interest. The analysis framework can extend to other first-order Wasserstein optimization schemes applied to flow-based generative models.
5/20/2024
Convergence Analysis of Probability Flow ODE for Score-based Generative Models
Daniel Zhengyu Huang, Jiaoyang Huang, Zhengjiang Lin
0
0
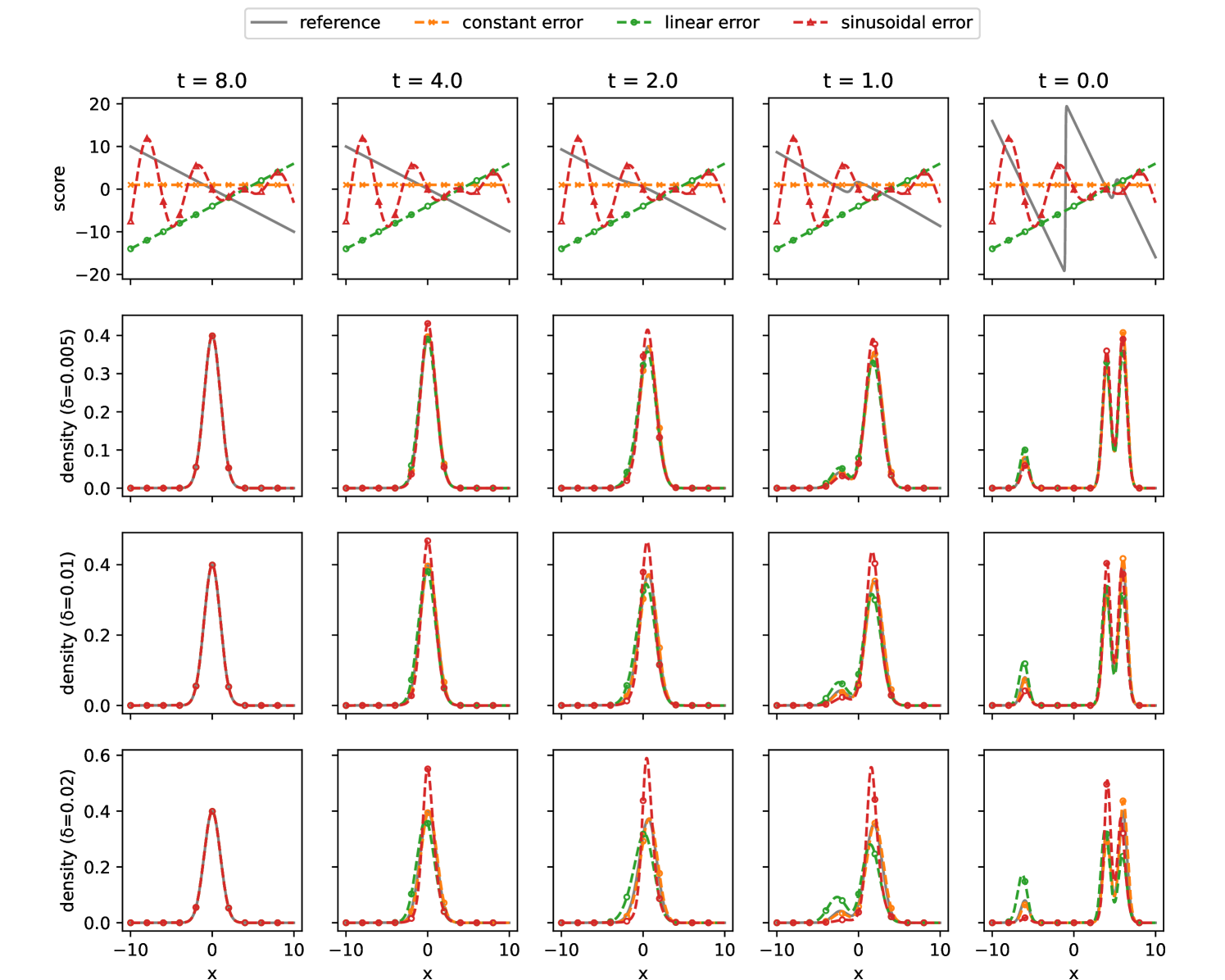
Score-based generative models have emerged as a powerful approach for sampling high-dimensional probability distributions. Despite their effectiveness, their theoretical underpinnings remain relatively underdeveloped. In this work, we study the convergence properties of deterministic samplers based on probability flow ODEs from both theoretical and numerical perspectives. Assuming access to $L^2$-accurate estimates of the score function, we prove the total variation between the target and the generated data distributions can be bounded above by $mathcal{O}(dsqrt{delta})$ in the continuous time level, where $d$ denotes the data dimension and $delta$ represents the $L^2$-score matching error. For practical implementations using a $p$-th order Runge-Kutta integrator with step size $h$, we establish error bounds of $mathcal{O}(d(sqrt{delta} + (dh)^p))$ at the discrete level. Finally, we present numerical studies on problems up to $128$ dimensions to verify our theory, which indicate a better score matching error and dimension dependence.
4/16/2024