Convergence Analysis of Probability Flow ODE for Score-based Generative Models
2404.09730
0
0
Abstract
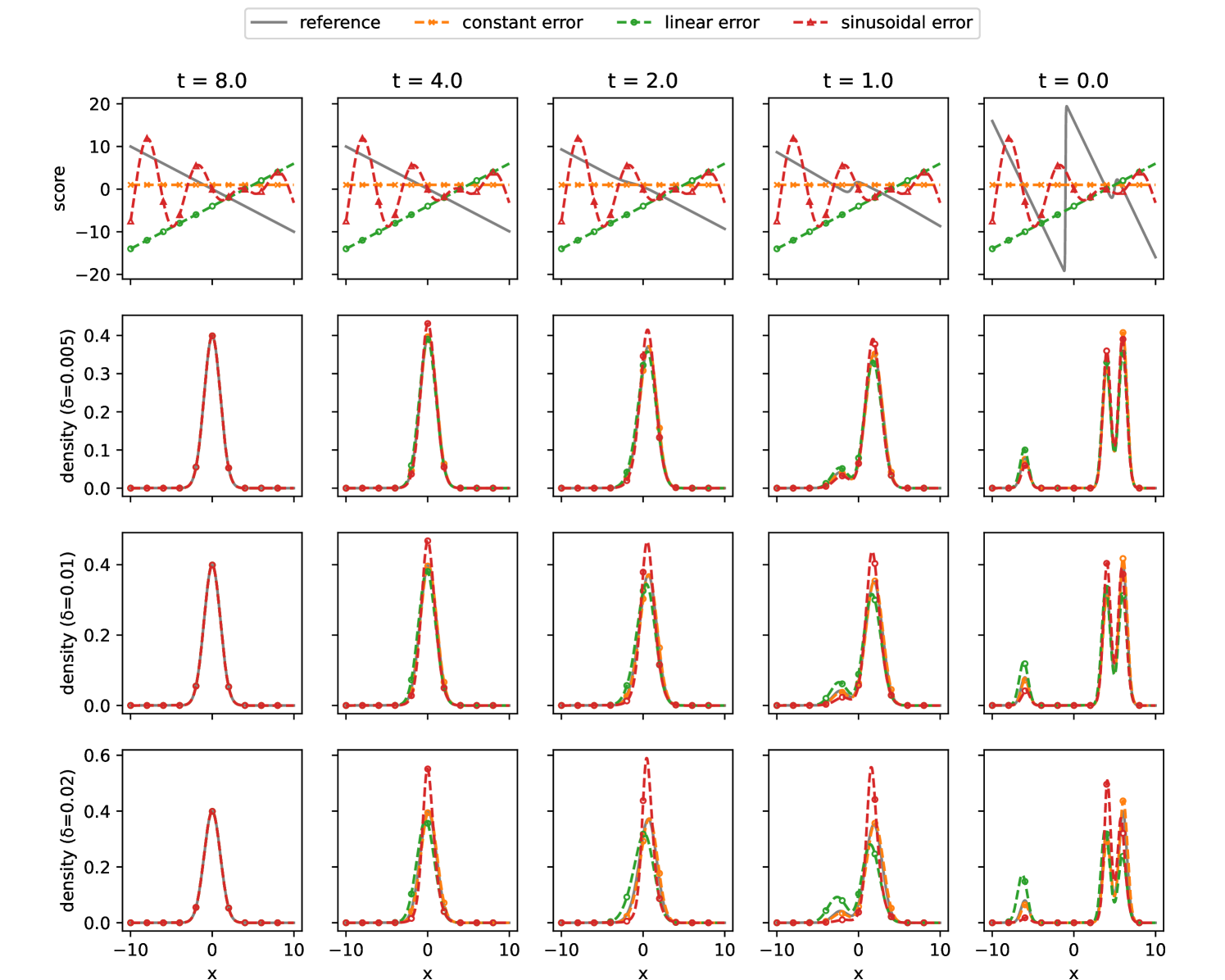
Score-based generative models have emerged as a powerful approach for sampling high-dimensional probability distributions. Despite their effectiveness, their theoretical underpinnings remain relatively underdeveloped. In this work, we study the convergence properties of deterministic samplers based on probability flow ODEs from both theoretical and numerical perspectives. Assuming access to $L^2$-accurate estimates of the score function, we prove the total variation between the target and the generated data distributions can be bounded above by $mathcal{O}(dsqrt{delta})$ in the continuous time level, where $d$ denotes the data dimension and $delta$ represents the $L^2$-score matching error. For practical implementations using a $p$-th order Runge-Kutta integrator with step size $h$, we establish error bounds of $mathcal{O}(d(sqrt{delta} + (dh)^p))$ at the discrete level. Finally, we present numerical studies on problems up to $128$ dimensions to verify our theory, which indicate a better score matching error and dimension dependence.
Create account to get full access
Overview
- The paper presents a convergence analysis of the probability flow ordinary differential equation (ODE) used in score-based generative models.
- Score-based generative models are a class of machine learning models that can generate realistic-looking data samples by learning the "score function" of the data distribution.
- The paper aims to provide theoretical guarantees on the convergence of the probability flow ODE, which is a key component of these models.
Plain English Explanation
In the field of machine learning, there is a type of model called a "score-based generative model" that can create new, realistic-looking data samples. These models work by learning the "score function" of the data distribution, which is a mathematical way of capturing the shape and structure of the data.
A key part of these score-based models is an ordinary differential equation (ODE) called the "probability flow ODE." This ODE is used to guide the model towards generating new data samples that match the distribution of the original training data.
The paper you provided analyzes the convergence properties of this probability flow ODE. In other words, it looks at how the ODE behaves and whether it can reliably produce the desired data samples as the model is trained. The authors provide mathematical proofs and guarantees to show that the ODE will converge to the correct solution, which is an important step in understanding the theoretical foundations of these powerful generative models.
Technical Explanation
The paper Convergence Analysis of Probability Flow ODE for Score-based Generative Models presents a detailed convergence analysis of the probability flow ordinary differential equation (ODE) used in score-based generative models.
Score-based generative models, such as Improved Techniques for Maximum Likelihood Estimation of Diffusion ODEs, [Convergence Result for Continuous Model of Deep Learning via Risk-Sensitive Diffusion Perturbation and Robust Optimization, and Convergence Analysis of Controlled Particle Systems Arising in Deep, are a class of models that can generate realistic-looking data samples by learning the "score function" of the data distribution.
The probability flow ODE is a key component of these score-based models, as it is used to guide the model towards generating new data samples that match the distribution of the original training data. The paper provides a thorough convergence analysis of this ODE, proving that it will reliably converge to the correct solution under certain assumptions.
The technical details of the analysis involve studying the properties of the score function and the dynamics of the probability flow ODE, and proving that the ODE will converge to the true data distribution as the model is trained.
Critical Analysis
The paper provides a strong theoretical foundation for the convergence of the probability flow ODE used in score-based generative models. The authors' mathematical analysis is rigorous and the proofs are well-constructed.
However, the paper does not address some practical considerations that may arise when applying these models in real-world scenarios. For example, the authors assume that the score function can be perfectly learned, but in practice, there may be challenges in accurately estimating the score function from finite data samples.
Additionally, the paper focuses solely on the theoretical convergence of the ODE, and does not discuss the potential limitations or failure modes of these models in practice. It would be valuable for future research to explore the robustness of score-based models to various types of data distributions, noise, and modeling assumptions.
Conclusion
The paper provides a rigorous convergence analysis of the probability flow ODE, which is a key component of score-based generative models. The authors prove that under certain assumptions, the ODE will reliably converge to the true data distribution as the model is trained.
This work lays an important theoretical foundation for understanding the behavior and properties of these powerful generative models. By establishing convergence guarantees, the paper helps to solidify the mathematical underpinnings of score-based models and paves the way for further advancements in this field.
While the paper does not address all practical considerations, it represents a significant step forward in the theoretical understanding of score-based generative models and their ability to generate realistic-looking data samples.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Evaluating the design space of diffusion-based generative models
Yuqing Wang, Ye He, Molei Tao
0
0
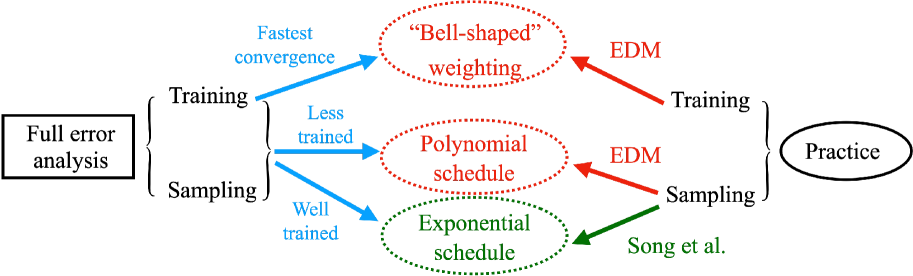
Most existing theoretical investigations of the accuracy of diffusion models, albeit significant, assume the score function has been approximated to a certain accuracy, and then use this a priori bound to control the error of generation. This article instead provides a first quantitative understanding of the whole generation process, i.e., both training and sampling. More precisely, it conducts a non-asymptotic convergence analysis of denoising score matching under gradient descent. In addition, a refined sampling error analysis for variance exploding models is also provided. The combination of these two results yields a full error analysis, which elucidates (again, but this time theoretically) how to design the training and sampling processes for effective generation. For instance, our theory implies a preference toward noise distribution and loss weighting that qualitatively agree with the ones used in [Karras et al. 2022]. It also provides some perspectives on why the time and variance schedule used in [Karras et al. 2022] could be better tuned than the pioneering version in [Song et al. 2020].
6/19/2024
💬
Improved Convergence of Score-Based Diffusion Models via Prediction-Correction
Francesco Pedrotti, Jan Maas, Marco Mondelli
0
0
Score-based generative models (SGMs) are powerful tools to sample from complex data distributions. Their underlying idea is to (i) run a forward process for time $T_1$ by adding noise to the data, (ii) estimate its score function, and (iii) use such estimate to run a reverse process. As the reverse process is initialized with the stationary distribution of the forward one, the existing analysis paradigm requires $T_1toinfty$. This is however problematic: from a theoretical viewpoint, for a given precision of the score approximation, the convergence guarantee fails as $T_1$ diverges; from a practical viewpoint, a large $T_1$ increases computational costs and leads to error propagation. This paper addresses the issue by considering a version of the popular predictor-corrector scheme: after running the forward process, we first estimate the final distribution via an inexact Langevin dynamics and then revert the process. Our key technical contribution is to provide convergence guarantees which require to run the forward process only for a fixed finite time $T_1$. Our bounds exhibit a mild logarithmic dependence on the input dimension and the subgaussian norm of the target distribution, have minimal assumptions on the data, and require only to control the $L^2$ loss on the score approximation, which is the quantity minimized in practice.
6/6/2024
Diffusion models for Gaussian distributions: Exact solutions and Wasserstein errors
Emile Pierret, Bruno Galerne
0
0
Diffusion or score-based models recently showed high performance in image generation. They rely on a forward and a backward stochastic differential equations (SDE). The sampling of a data distribution is achieved by solving numerically the backward SDE or its associated flow ODE. Studying the convergence of these models necessitates to control four different types of error: the initialization error, the truncation error, the discretization and the score approximation. In this paper, we study theoretically the behavior of diffusion models and their numerical implementation when the data distribution is Gaussian. In this restricted framework where the score function is a linear operator, we can derive the analytical solutions of the forward and backward SDEs as well as the associated flow ODE. This provides exact expressions for various Wasserstein errors which enable us to compare the influence of each error type for any sampling scheme, thus allowing to monitor convergence directly in the data space instead of relying on Inception features. Our experiments show that the recommended numerical schemes from the diffusion models literature are also the best sampling schemes for Gaussian distributions.
6/13/2024
🤔
Convergence of flow-based generative models via proximal gradient descent in Wasserstein space
Xiuyuan Cheng, Jianfeng Lu, Yixin Tan, Yao Xie
0
0
Flow-based generative models enjoy certain advantages in computing the data generation and the likelihood, and have recently shown competitive empirical performance. Compared to the accumulating theoretical studies on related score-based diffusion models, analysis of flow-based models, which are deterministic in both forward (data-to-noise) and reverse (noise-to-data) directions, remain sparse. In this paper, we provide a theoretical guarantee of generating data distribution by a progressive flow model, the so-called JKO flow model, which implements the Jordan-Kinderleherer-Otto (JKO) scheme in a normalizing flow network. Leveraging the exponential convergence of the proximal gradient descent (GD) in Wasserstein space, we prove the Kullback-Leibler (KL) guarantee of data generation by a JKO flow model to be $O(varepsilon^2)$ when using $N lesssim log (1/varepsilon)$ many JKO steps ($N$ Residual Blocks in the flow) where $varepsilon $ is the error in the per-step first-order condition. The assumption on data density is merely a finite second moment, and the theory extends to data distributions without density and when there are inversion errors in the reverse process where we obtain KL-$W_2$ mixed error guarantees. The non-asymptotic convergence rate of the JKO-type $W_2$-proximal GD is proved for a general class of convex objective functionals that includes the KL divergence as a special case, which can be of independent interest. The analysis framework can extend to other first-order Wasserstein optimization schemes applied to flow-based generative models.
5/20/2024