On the Convergence of a Federated Expectation-Maximization Algorithm

0
Sign in to get full access
Overview
- This paper analyzes the convergence of a federated expectation-maximization (EM) algorithm.
- The EM algorithm is a popular technique for learning parameters in statistical models with hidden variables.
- Federated learning allows training models on decentralized data without directly sharing the data.
Plain English Explanation
The paper examines a way to train statistical models using an expectation-maximization (EM) algorithm in a federated setting. The EM algorithm is a common technique for learning model parameters when there are hidden or unobserved variables in the data.
Federated learning is an approach that allows training models on data distributed across many devices or locations, without the data ever being directly shared. This can be useful for preserving privacy or working with data that cannot be centralized.
The researchers analyze the convergence properties of a federated EM algorithm, meaning they study how this approach behaves as the model is trained and improved over many iterations. Understanding the convergence behavior is important to ensure the algorithm reliably finds a good solution.
Technical Explanation
The paper provides a theoretical analysis of the convergence properties of a federated expectation-maximization (EM) algorithm. The EM algorithm is a widely-used technique for learning parameters in statistical models with latent or hidden variables.
The authors consider a federated learning setup, where the training data is distributed across multiple clients and the model is trained by iteratively aggregating updates from the clients. They derive conditions under which the federated EM algorithm is guaranteed to converge to a stationary point of the underlying optimization problem.
The key technical contributions include:
- Establishing the global convergence of the federated EM algorithm under certain assumptions on the local data distributions and the aggregation scheme.
- Characterizing the linear convergence rate of the algorithm in the strongly convex case.
- Demonstrating the algorithm's robustness to client dropout and data heterogeneity across clients.
Critical Analysis
The paper provides a rigorous theoretical analysis of the federated EM algorithm, but there are a few potential limitations worth considering:
-
The convergence analysis relies on several assumptions, such as bounded gradients and Lipschitz continuity of the objective function. These assumptions may not always hold in practical applications.
-
The paper focuses on the asymptotic convergence behavior, but does not provide guarantees on the finite-time performance of the algorithm. In many real-world scenarios, the number of iterations may be limited.
-
The analysis considers a specific aggregation scheme (weighted average of client updates), and it's unclear how the results would generalize to other aggregation methods that may be more suitable for heterogeneous data distributions.
-
The paper does not address the issue of client selection, which is an important practical consideration in federated learning systems with a large number of clients.
Overall, the theoretical insights provided in the paper are valuable, but further research may be needed to fully understand the practical implications and limitations of the federated EM algorithm.
Conclusion
This paper presents a theoretical analysis of the convergence properties of a federated expectation-maximization (EM) algorithm. The EM algorithm is a widely-used technique for learning statistical models with hidden variables, and the federated approach allows training these models on decentralized data while preserving privacy.
The key contributions of the paper include establishing global convergence guarantees for the federated EM algorithm, characterizing its linear convergence rate under certain conditions, and demonstrating its robustness to client dropout and data heterogeneity. These theoretical insights can help inform the design and deployment of federated learning systems that leverage the EM algorithm.
While the analysis relies on several technical assumptions, the paper provides a valuable foundation for further research on the practical applications and limitations of federated EM algorithms in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Convergence of a Federated Expectation-Maximization Algorithm
Zhixu Tao, Rajita Chandak, Sanjeev Kulkarni
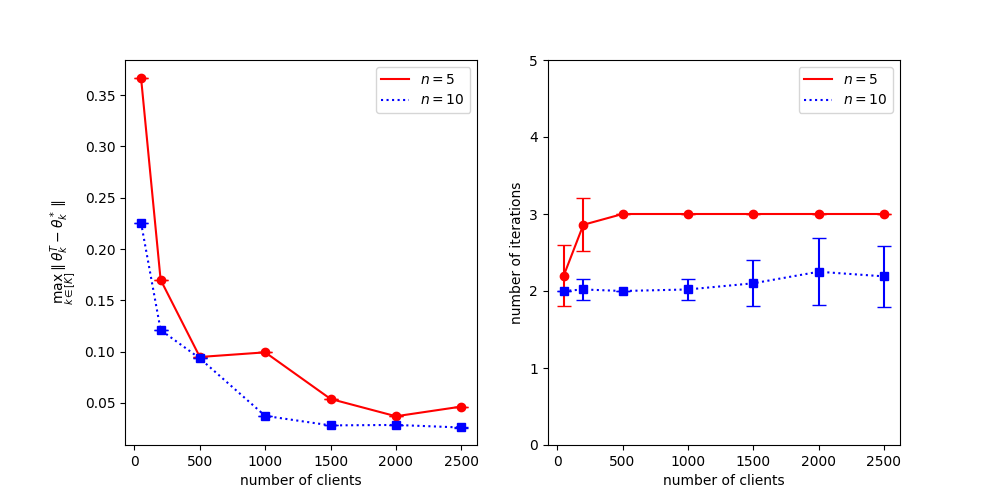
Data heterogeneity has been a long-standing bottleneck in studying the convergence rates of Federated Learning algorithms. In order to better understand the issue of data heterogeneity, we study the convergence rate of the Expectation-Maximization (EM) algorithm for the Federated Mixture of $K$ Linear Regressions model. We fully characterize the convergence rate of the EM algorithm under all regimes of $m/n$ where $m$ is the number of clients and $n$ is the number of data points per client. We show that with a signal-to-noise-ratio (SNR) of order $Omega(sqrt{K})$, the well-initialized EM algorithm converges within the minimax distance of the ground truth under each of the regimes. Interestingly, we identify that when $m$ grows exponentially in $n$, the EM algorithm only requires a constant number of iterations to converge. We perform experiments on synthetic datasets to illustrate our results. Surprisingly, the results show that rather than being a bottleneck, data heterogeneity can accelerate the convergence of federated learning algorithms.
Read more8/13/2024

0
On the Convergence Rates of Federated Q-Learning across Heterogeneous Environments
Muxing Wang, Pengkun Yang, Lili Su
Large-scale multi-agent systems are often deployed across wide geographic areas, where agents interact with heterogeneous environments. There is an emerging interest in understanding the role of heterogeneity in the performance of the federated versions of classic reinforcement learning algorithms. In this paper, we study synchronous federated Q-learning, which aims to learn an optimal Q-function by having $K$ agents average their local Q-estimates per $E$ iterations. We observe an interesting phenomenon on the convergence speeds in terms of $K$ and $E$. Similar to the homogeneous environment settings, there is a linear speed-up concerning $K$ in reducing the errors that arise from sampling randomness. Yet, in sharp contrast to the homogeneous settings, $E>1$ leads to significant performance degradation. Specifically, we provide a fine-grained characterization of the error evolution in the presence of environmental heterogeneity, which decay to zero as the number of iterations $T$ increases. The slow convergence of having $E>1$ turns out to be fundamental rather than an artifact of our analysis. We prove that, for a wide range of stepsizes, the $ell_{infty}$ norm of the error cannot decay faster than $Theta (E/T)$. In addition, our experiments demonstrate that the convergence exhibits an interesting two-phase phenomenon. For any given stepsize, there is a sharp phase-transition of the convergence: the error decays rapidly in the beginning yet later bounces up and stabilizes. Provided that the phase-transition time can be estimated, choosing different stepsizes for the two phases leads to faster overall convergence.
Read more9/9/2024

0
Toward Global Convergence of Gradient EM for Over-Parameterized Gaussian Mixture Models
Weihang Xu, Maryam Fazel, Simon S. Du
We study the gradient Expectation-Maximization (EM) algorithm for Gaussian Mixture Models (GMM) in the over-parameterized setting, where a general GMM with $n>1$ components learns from data that are generated by a single ground truth Gaussian distribution. While results for the special case of 2-Gaussian mixtures are well-known, a general global convergence analysis for arbitrary $n$ remains unresolved and faces several new technical barriers since the convergence becomes sub-linear and non-monotonic. To address these challenges, we construct a novel likelihood-based convergence analysis framework and rigorously prove that gradient EM converges globally with a sublinear rate $O(1/sqrt{t})$. This is the first global convergence result for Gaussian mixtures with more than $2$ components. The sublinear convergence rate is due to the algorithmic nature of learning over-parameterized GMM with gradient EM. We also identify a new emerging technical challenge for learning general over-parameterized GMM: the existence of bad local regions that can trap gradient EM for an exponential number of steps.
Read more7/2/2024
📊
0
A New Theoretical Perspective on Data Heterogeneity in Federated Optimization
Jiayi Wang, Shiqiang Wang, Rong-Rong Chen, Mingyue Ji
In federated learning (FL), data heterogeneity is the main reason that existing theoretical analyses are pessimistic about the convergence rate. In particular, for many FL algorithms, the convergence rate grows dramatically when the number of local updates becomes large, especially when the product of the gradient divergence and local Lipschitz constant is large. However, empirical studies can show that more local updates can improve the convergence rate even when these two parameters are large, which is inconsistent with the theoretical findings. This paper aims to bridge this gap between theoretical understanding and practical performance by providing a theoretical analysis from a new perspective on data heterogeneity. In particular, we propose a new and weaker assumption compared to the local Lipschitz gradient assumption, named the heterogeneity-driven pseudo-Lipschitz assumption. We show that this and the gradient divergence assumptions can jointly characterize the effect of data heterogeneity. By deriving a convergence upper bound for FedAvg and its extensions, we show that, compared to the existing works, local Lipschitz constant is replaced by the much smaller heterogeneity-driven pseudo-Lipschitz constant and the corresponding convergence upper bound can be significantly reduced for the same number of local updates, although its order stays the same. In addition, when the local objective function is quadratic, more insights on the impact of data heterogeneity can be obtained using the heterogeneity-driven pseudo-Lipschitz constant. For example, we can identify a region where FedAvg can outperform mini-batch SGD even when the gradient divergence can be arbitrarily large. Our findings are validated using experiments.
Read more7/23/2024