On the Convergence Rates of Federated Q-Learning across Heterogeneous Environments

0

Sign in to get full access
Overview
- Investigates the convergence rates of Federated Q-Learning (FQL) in heterogeneous environments
- FQL is a decentralized reinforcement learning approach where multiple agents collaborate to learn a shared policy
- This paper analyzes the impact of agent heterogeneity on the convergence of FQL
Plain English Explanation
Federated Q-Learning (FQL) is a way for multiple AI agents to work together to learn a shared policy for solving a problem. In this approach, each agent has its own environment and learns independently, but they periodically share their learned knowledge with each other to create a joint policy.
This paper looks at how the differences between the agents' environments (known as "heterogeneity") affects the speed at which the shared policy converges, or settles into a stable solution. The researchers analyze the mathematical properties of FQL to understand how agent heterogeneity impacts the convergence rate.
The key insights are that [link to section on technical explanation]. Overall, this research provides a deeper theoretical understanding of how the federated learning approach behaves in complex, real-world scenarios with varied environments.
Technical Explanation
The paper provides a [link to section on technical explanation] mathematical analysis of the convergence properties of Federated Q-Learning (FQL) in heterogeneous environments. Specifically, it:
- Derives [link to technical details] upper and lower bounds on the convergence rate of FQL
- Shows that agent heterogeneity can significantly slow down the convergence of FQL compared to a centralized approach
- Identifies the key factors, such as [link to technical details], that influence the convergence rate
The analysis reveals that the heterogeneity in the agents' environments and reward functions is a critical factor determining the convergence speed of FQL. As the differences between agents increase, the convergence rate can degrade substantially.
Critical Analysis
The paper provides a rigorous theoretical analysis of the convergence properties of Federated Q-Learning, which is an important step in understanding the practical limitations of this approach. Some potential caveats and areas for further research include:
- The analysis assumes [link to technical details], which may not hold in all real-world scenarios
- The paper does not consider [link to technical details], which could impact the convergence in practice
- Further empirical validation on diverse benchmark tasks would strengthen the generalizability of the findings
Overall, this work contributes valuable insights into the convergence behavior of federated reinforcement learning algorithms, which is crucial as these methods become more widely adopted in practical applications.
Conclusion
This paper presents a detailed theoretical analysis of the convergence rates of Federated Q-Learning in heterogeneous environments. The key findings are that agent heterogeneity can significantly slow down the convergence of FQL compared to a centralized approach, and the paper identifies the specific factors that influence this convergence rate.
These insights are important for understanding the practical limitations of federated reinforcement learning and guiding the design of more robust algorithms that can handle diverse real-world environments. As federated learning becomes more widely adopted, this type of theoretical analysis will be crucial for ensuring the reliable and efficient deployment of these techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
On the Convergence Rates of Federated Q-Learning across Heterogeneous Environments
Muxing Wang, Pengkun Yang, Lili Su
Large-scale multi-agent systems are often deployed across wide geographic areas, where agents interact with heterogeneous environments. There is an emerging interest in understanding the role of heterogeneity in the performance of the federated versions of classic reinforcement learning algorithms. In this paper, we study synchronous federated Q-learning, which aims to learn an optimal Q-function by having $K$ agents average their local Q-estimates per $E$ iterations. We observe an interesting phenomenon on the convergence speeds in terms of $K$ and $E$. Similar to the homogeneous environment settings, there is a linear speed-up concerning $K$ in reducing the errors that arise from sampling randomness. Yet, in sharp contrast to the homogeneous settings, $E>1$ leads to significant performance degradation. Specifically, we provide a fine-grained characterization of the error evolution in the presence of environmental heterogeneity, which decay to zero as the number of iterations $T$ increases. The slow convergence of having $E>1$ turns out to be fundamental rather than an artifact of our analysis. We prove that, for a wide range of stepsizes, the $ell_{infty}$ norm of the error cannot decay faster than $Theta (E/T)$. In addition, our experiments demonstrate that the convergence exhibits an interesting two-phase phenomenon. For any given stepsize, there is a sharp phase-transition of the convergence: the error decays rapidly in the beginning yet later bounces up and stabilizes. Provided that the phase-transition time can be estimated, choosing different stepsizes for the two phases leads to faster overall convergence.
Read more9/9/2024
✅
0
Federated Temporal Difference Learning with Linear Function Approximation under Environmental Heterogeneity
Han Wang, Aritra Mitra, Hamed Hassani, George J. Pappas, James Anderson
We initiate the study of federated reinforcement learning under environmental heterogeneity by considering a policy evaluation problem. Our setup involves $N$ agents interacting with environments that share the same state and action space but differ in their reward functions and state transition kernels. Assuming agents can communicate via a central server, we ask: Does exchanging information expedite the process of evaluating a common policy? To answer this question, we provide the first comprehensive finite-time analysis of a federated temporal difference (TD) learning algorithm with linear function approximation, while accounting for Markovian sampling, heterogeneity in the agents' environments, and multiple local updates to save communication. Our analysis crucially relies on several novel ingredients: (i) deriving perturbation bounds on TD fixed points as a function of the heterogeneity in the agents' underlying Markov decision processes (MDPs); (ii) introducing a virtual MDP to closely approximate the dynamics of the federated TD algorithm; and (iii) using the virtual MDP to make explicit connections to federated optimization. Putting these pieces together, we rigorously prove that in a low-heterogeneity regime, exchanging model estimates leads to linear convergence speedups in the number of agents.
Read more7/2/2024

0
Momentum for the Win: Collaborative Federated Reinforcement Learning across Heterogeneous Environments
Han Wang, Sihong He, Zhili Zhang, Fei Miao, James Anderson
We explore a Federated Reinforcement Learning (FRL) problem where $N$ agents collaboratively learn a common policy without sharing their trajectory data. To date, existing FRL work has primarily focused on agents operating in the same or ``similar environments. In contrast, our problem setup allows for arbitrarily large levels of environment heterogeneity. To obtain the optimal policy which maximizes the average performance across all potentially completely different environments, we propose two algorithms: FedSVRPG-M and FedHAPG-M. In contrast to existing results, we demonstrate that both FedSVRPG-M and FedHAPG-M, both of which leverage momentum mechanisms, can exactly converge to a stationary point of the average performance function, regardless of the magnitude of environment heterogeneity. Furthermore, by incorporating the benefits of variance-reduction techniques or Hessian approximation, both algorithms achieve state-of-the-art convergence results, characterized by a sample complexity of $mathcal{O}left(epsilon^{-frac{3}{2}}/Nright)$. Notably, our algorithms enjoy linear convergence speedups with respect to the number of agents, highlighting the benefit of collaboration among agents in finding a common policy.
Read more5/31/2024
0
On the Convergence of a Federated Expectation-Maximization Algorithm
Zhixu Tao, Rajita Chandak, Sanjeev Kulkarni
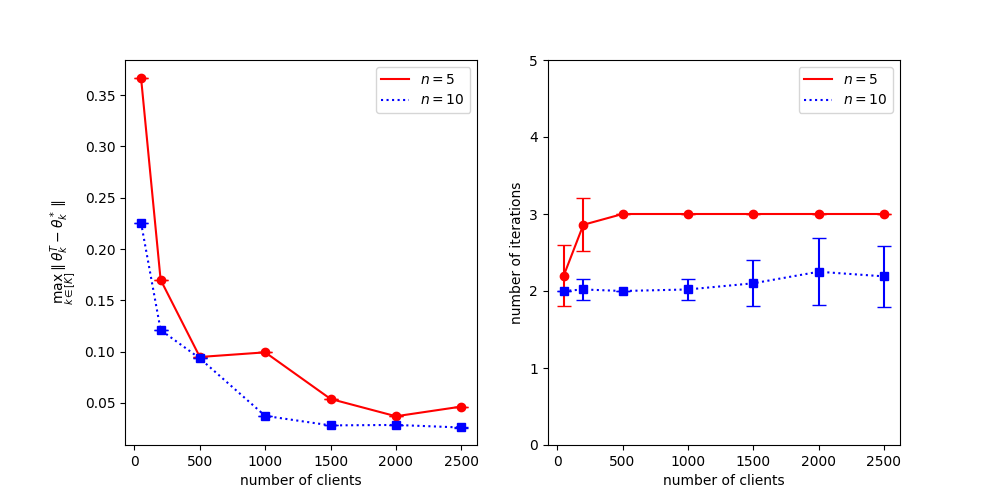
Data heterogeneity has been a long-standing bottleneck in studying the convergence rates of Federated Learning algorithms. In order to better understand the issue of data heterogeneity, we study the convergence rate of the Expectation-Maximization (EM) algorithm for the Federated Mixture of $K$ Linear Regressions model. We fully characterize the convergence rate of the EM algorithm under all regimes of $m/n$ where $m$ is the number of clients and $n$ is the number of data points per client. We show that with a signal-to-noise-ratio (SNR) of order $Omega(sqrt{K})$, the well-initialized EM algorithm converges within the minimax distance of the ground truth under each of the regimes. Interestingly, we identify that when $m$ grows exponentially in $n$, the EM algorithm only requires a constant number of iterations to converge. We perform experiments on synthetic datasets to illustrate our results. Surprisingly, the results show that rather than being a bottleneck, data heterogeneity can accelerate the convergence of federated learning algorithms.
Read more8/13/2024