Conversation Disentanglement with Bi-Level Contrastive Learning

0
✅
Sign in to get full access
Overview
- Conversation disentanglement aims to group utterances into separate sessions within multi-party conversations.
- Existing methods have two main drawbacks:
- Overemphasis on pairwise utterance relations, with inadequate attention to utterance-to-context modeling.
- Requirement of a large amount of human-annotated training data, which is expensive to obtain.
Plain English Explanation
Conversation disentanglement is the process of organizing the different conversations happening within a larger multi-person discussion. Existing methods for this have struggled with two key problems:
-
They focus too much on how individual utterances (statements) are related to each other, without considering how each utterance relates to the overall context of the conversation. This makes it harder to accurately group the utterances into their proper conversation threads.
-
These methods require a lot of human-labeled training data, which can be very time-consuming and costly to obtain. This limits their practicality in real-world applications.
Technical Explanation
To address these issues, the researchers propose a new general disentanglement model based on a technique called "bi-level contrastive learning." This approach:
- Brings utterances from the same conversation session closer together in the representation space.
- Encourages each utterance to be near the "prototype" or central representation of its conversation session.
Importantly, this model can work in both supervised settings (with labeled training data) and unsupervised settings (without any labeled data). The researchers show that their method achieves new state-of-the-art performance on several public datasets, outperforming other recent approaches.
Critical Analysis
The paper does not delve into potential limitations or caveats of the proposed approach. One area for further research could be understanding how the model behaves on more noisy or complex real-world conversational data, beyond the curated public datasets used in the experiments.
Additionally, the paper does not provide much analysis on the interpretability or explainability of the learned representations and how they capture the underlying conversational structure. Examining these aspects could yield valuable insights.
Conclusion
This research presents an innovative bi-level contrastive learning approach to the important problem of conversation disentanglement. By better modeling the relationships between utterances and their broader conversational context, the proposed method achieves state-of-the-art performance in both supervised and unsupervised settings. As conversational AI systems become more ubiquitous, advances in this area could have significant implications for improving the quality and coherence of multi-party dialogues.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
Conversation Disentanglement with Bi-Level Contrastive Learning
Chengyu Huang, Zheng Zhang, Hao Fei, Lizi Liao
Conversation disentanglement aims to group utterances into detached sessions, which is a fundamental task in processing multi-party conversations. Existing methods have two main drawbacks. First, they overemphasize pairwise utterance relations but pay inadequate attention to the utterance-to-context relation modeling. Second, huge amount of human annotated data is required for training, which is expensive to obtain in practice. To address these issues, we propose a general disentangle model based on bi-level contrastive learning. It brings closer utterances in the same session while encourages each utterance to be near its clustered session prototypes in the representation space. Unlike existing approaches, our disentangle model works in both supervised setting with labeled data and unsupervised setting when no such data is available. The proposed method achieves new state-of-the-art performance on both settings across several public datasets.
Read more9/4/2024

0
Contrastive Disentangling: Fine-grained representation learning through multi-level contrastive learning without class priors
Houwang Jiang, Zhuxian Liu, Guodong Liu, Xiaolong Liu, Shihua Zhan
Recent advances in unsupervised representation learning often rely on knowing the number of classes to improve feature extraction and clustering. However, this assumption raises an important question: is the number of classes always necessary, and do class labels fully capture the fine-grained features within the data? In this paper, we propose Contrastive Disentangling (CD), a framework designed to learn representations without relying on class priors. CD leverages a multi-level contrastive learning strategy, integrating instance-level and feature-level contrastive losses with a normalized entropy loss to capture semantically rich and fine-grained representations. Specifically, (1) the instance-level contrastive loss separates feature representations across samples; (2) the feature-level contrastive loss promotes independence among feature heads; and (3) the normalized entropy loss ensures feature diversity and prevents feature collapse. Extensive experiments on CIFAR-10, CIFAR-100, STL-10, and ImageNet-10 demonstrate that CD outperforms existing methods in scenarios where class information is unavailable or ambiguous. The code is available at https://github.com/Hoper-J/Contrastive-Disentangling.
Read more9/24/2024
0
Towards the Next Frontier in Speech Representation Learning Using Disentanglement
Varun Krishna, Sriram Ganapathy
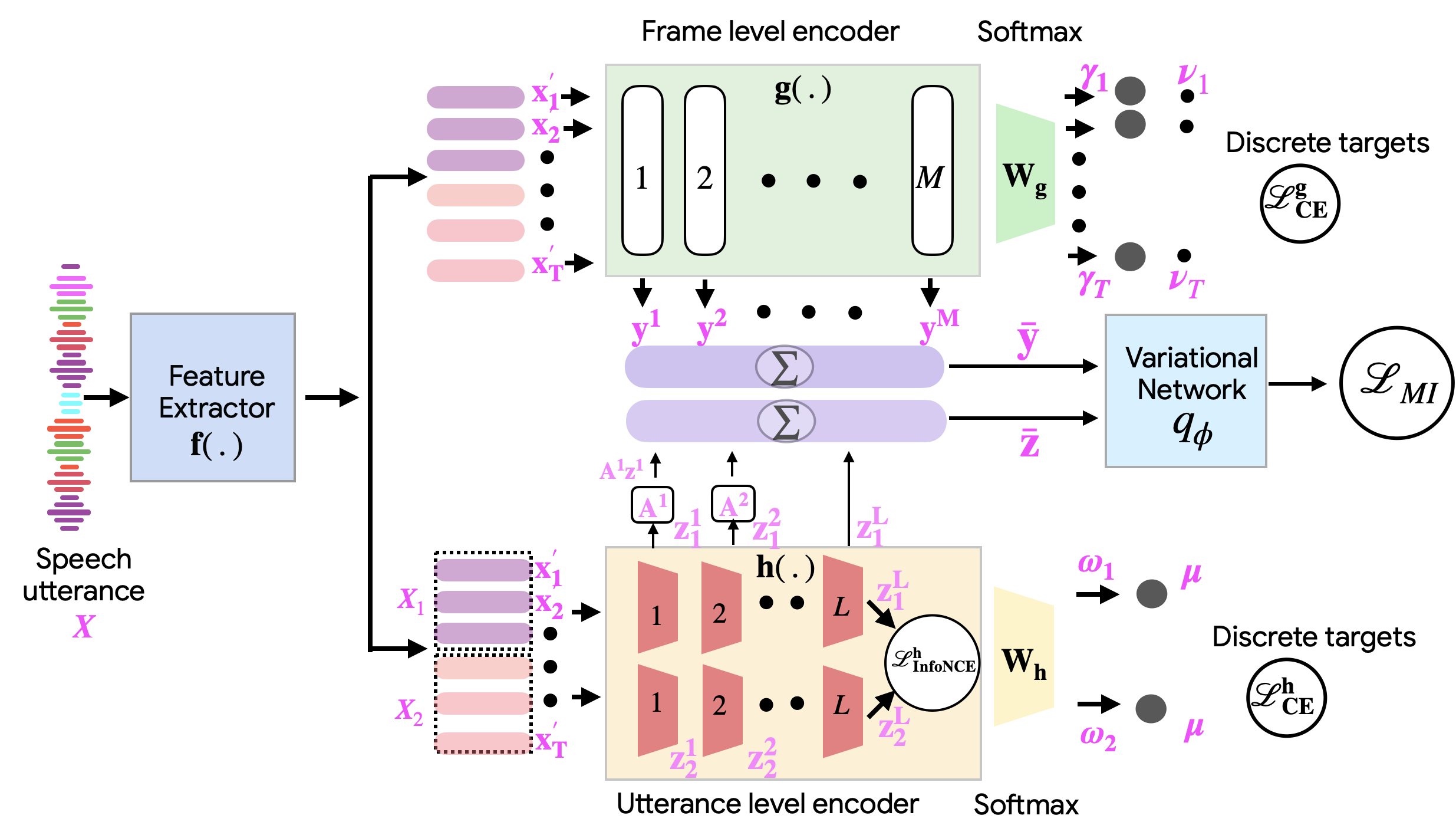
The popular frameworks for self-supervised learning of speech representations have largely focused on frame-level masked prediction of speech regions. While this has shown promising downstream task performance for speech recognition and related tasks, this has largely ignored factors of speech that are encoded at coarser level, like characteristics of the speaker or channel that remain consistent through-out a speech utterance. In this work, we propose a framework for Learning Disentangled Self Supervised (termed as Learn2Diss) representations of speech, which consists of frame-level and an utterance-level encoder modules. The two encoders are initially learned independently, where the frame-level model is largely inspired by existing self supervision techniques, thereby learning pseudo-phonemic representations, while the utterance-level encoder is inspired by constrastive learning of pooled embeddings, thereby learning pseudo-speaker representations. The joint learning of these two modules consists of disentangling the two encoders using a mutual information based criterion. With several downstream evaluation experiments, we show that the proposed Learn2Diss achieves state-of-the-art results on a variety of tasks, with the frame-level encoder representations improving semantic tasks, while the utterance-level representations improve non-semantic tasks.
Read more7/4/2024

0
Constrained Multi-Layer Contrastive Learning for Implicit Discourse Relationship Recognition
Yiheng Wu, Junhui Li, Muhua Zhu
Previous approaches to the task of implicit discourse relation recognition (IDRR) generally view it as a classification task. Even with pre-trained language models, like BERT and RoBERTa, IDRR still relies on complicated neural networks with multiple intermediate layers to proper capture the interaction between two discourse units. As a result, the outputs of these intermediate layers may have different capability in discriminating instances of different classes. To this end, we propose to adapt a supervised contrastive learning (CL) method, label- and instance-centered CL, to enhance representation learning. Moreover, we propose a novel constrained multi-layer CL approach to properly impose a constraint that the contrastive loss of higher layers should be smaller than that of lower layers. Experimental results on PDTB 2.0 and PDTB 3.0 show that our approach can significantly improve the performance on both multi-class classification and binary classification.
Read more9/24/2024