Convex and Bilevel Optimization for Neuro-Symbolic Inference and Learning
2401.09651
0
0
🛠️
Abstract
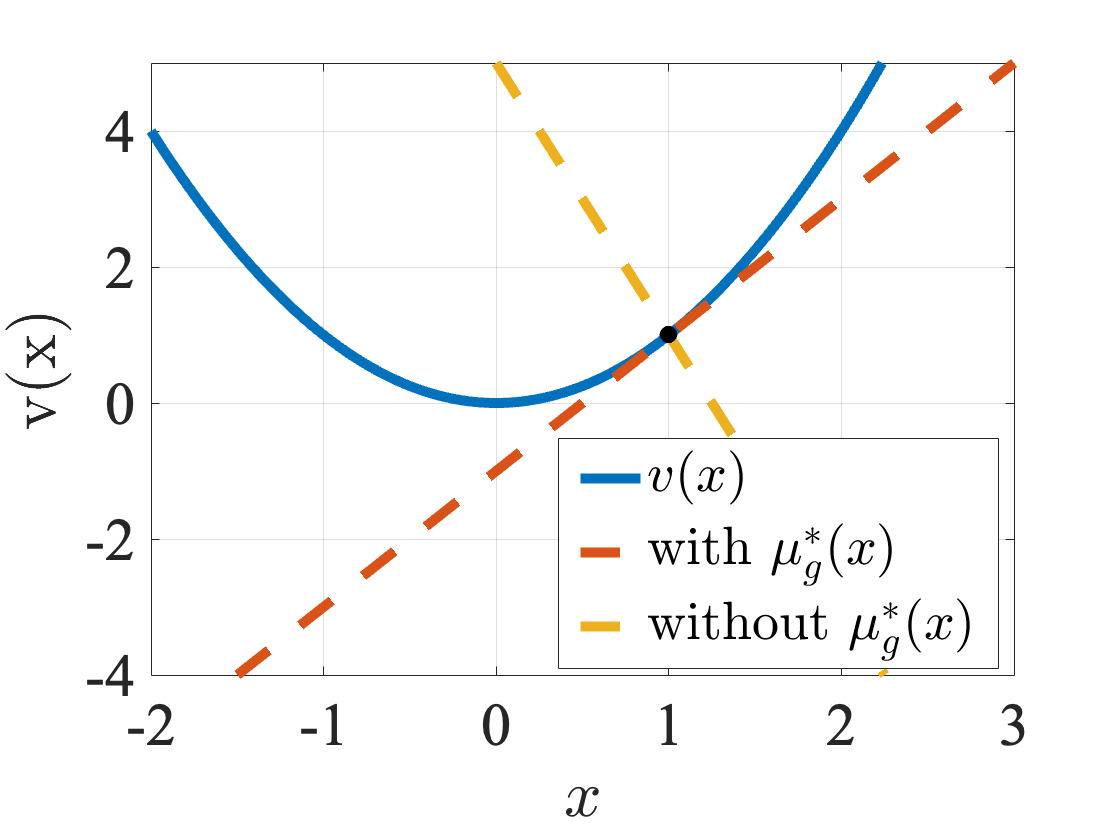
We leverage convex and bilevel optimization techniques to develop a general gradient-based parameter learning framework for neural-symbolic (NeSy) systems. We demonstrate our framework with NeuPSL, a state-of-the-art NeSy architecture. To achieve this, we propose a smooth primal and dual formulation of NeuPSL inference and show learning gradients are functions of the optimal dual variables. Additionally, we develop a dual block coordinate descent algorithm for the new formulation that naturally exploits warm-starts. This leads to over 100x learning runtime improvements over the current best NeuPSL inference method. Finally, we provide extensive empirical evaluations across 8 datasets covering a range of tasks and demonstrate our learning framework achieves up to a 16% point prediction performance improvement over alternative learning methods.
Create account to get full access
Overview
- The researchers develop a general gradient-based parameter learning framework for neural-symbolic (NeSy) systems, leveraging convex and bilevel optimization techniques.
- They demonstrate their framework with NeuPSL, a state-of-the-art NeSy architecture.
- They propose a smooth primal and dual formulation of NeuPSL inference and show that learning gradients are functions of the optimal dual variables.
- They also develop a dual block coordinate descent algorithm for the new formulation that exploits warm-starts, leading to over 100x learning runtime improvements.
- The framework is extensively evaluated across 8 datasets, demonstrating up to a 16% point prediction performance improvement over alternative learning methods.
Plain English Explanation
The researchers have created a new way to train neural-symbolic systems, which are a type of artificial intelligence that combines neural networks with symbolic logic. Their approach uses advanced optimization techniques, including convex optimization and bilevel optimization, to make the training process more efficient and effective.
They tested their framework on a specific neural-symbolic system called NeuPSL, which is one of the best-performing models of its kind. By reformulating the way NeuPSL does its computations, the researchers were able to develop a new training algorithm that is over 100 times faster than the previous method. This means the model can be trained much more quickly, which is important for real-world applications.
The researchers also conducted extensive experiments to evaluate their framework across a variety of tasks and datasets. They found that their approach can improve the model's prediction accuracy by up to 16 percentage points compared to other training methods. This is a significant improvement that could have a big impact in areas where neural-symbolic systems are used, such as natural language processing, knowledge representation, and automated reasoning.
Technical Explanation
The researchers develop a general gradient-based parameter learning framework for neural-symbolic (NeSy) systems. They demonstrate their framework with NeuPSL, a state-of-the-art NeSy architecture.
To achieve this, the researchers propose a smooth primal and dual formulation of NeuPSL inference. They show that the learning gradients are functions of the optimal dual variables. Additionally, they develop a dual block coordinate descent algorithm for the new formulation that naturally exploits warm-starts. This leads to over 100x learning runtime improvements over the current best NeuPSL inference method.
The researchers provide extensive empirical evaluations across 8 datasets covering a range of tasks. They demonstrate that their learning framework achieves up to a 16% point prediction performance improvement over alternative learning methods, such as learning to optimize with convergence guarantees and finding small hypergradients in bilevel optimization.
Critical Analysis
The researchers acknowledge that their framework is limited to NeSy systems and may not generalize to other types of machine learning models. They also note that the performance improvements are highly dependent on the specific task and dataset, and that further research is needed to understand the broader applicability of their approach.
Additionally, the researchers do not address the potential interpretability and explainability challenges associated with neural-symbolic systems. As these models combine neural networks with symbolic logic, understanding the underlying reasoning process can be complex and difficult to interpret.
Furthermore, the researchers do not discuss the computational and memory requirements of their framework, which could be a limiting factor for practical applications, especially when dealing with large-scale datasets or models.
Conclusion
The researchers have developed a novel gradient-based parameter learning framework for neural-symbolic systems that leverages advanced optimization techniques. Their approach demonstrates significant performance improvements over alternative methods, particularly in terms of training runtime and prediction accuracy.
This work advances the state-of-the-art in neural-symbolic learning and could have important implications for a wide range of applications, such as natural language processing, knowledge representation, and automated reasoning. However, further research is needed to address the potential limitations and expand the generalizability of the framework.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Functional Bilevel Optimization for Machine Learning
Ieva Petrulionyte, Julien Mairal, Michael Arbel
0
0
In this paper, we introduce a new functional point of view on bilevel optimization problems for machine learning, where the inner objective is minimized over a function space. These types of problems are most often solved by using methods developed in the parametric setting, where the inner objective is strongly convex with respect to the parameters of the prediction function. The functional point of view does not rely on this assumption and notably allows using over-parameterized neural networks as the inner prediction function. We propose scalable and efficient algorithms for the functional bilevel optimization problem and illustrate the benefits of our approach on instrumental regression and reinforcement learning tasks.
6/14/2024

Bilevel reinforcement learning via the development of hyper-gradient without lower-level convexity
Yan Yang, Bin Gao, Ya-xiang Yuan
0
0
Bilevel reinforcement learning (RL), which features intertwined two-level problems, has attracted growing interest recently. The inherent non-convexity of the lower-level RL problem is, however, to be an impediment to developing bilevel optimization methods. By employing the fixed point equation associated with the regularized RL, we characterize the hyper-gradient via fully first-order information, thus circumventing the assumption of lower-level convexity. This, remarkably, distinguishes our development of hyper-gradient from the general AID-based bilevel frameworks since we take advantage of the specific structure of RL problems. Moreover, we propose both model-based and model-free bilevel reinforcement learning algorithms, facilitated by access to the fully first-order hyper-gradient. Both algorithms are provable to enjoy the convergence rate $mathcal{O}(epsilon^{-1})$. To the best of our knowledge, this is the first time that AID-based bilevel RL gets rid of additional assumptions on the lower-level problem. In addition, numerical experiments demonstrate that the hyper-gradient indeed serves as an integration of exploitation and exploration.
5/31/2024
A Primal-Dual-Assisted Penalty Approach to Bilevel Optimization with Coupled Constraints
Liuyuan Jiang, Quan Xiao, Victor M. Tenorio, Fernando Real-Rojas, Antonio Marques, Tianyi Chen
0
0
Interest in bilevel optimization has grown in recent years, partially due to its applications to tackle challenging machine-learning problems. Several exciting recent works have been centered around developing efficient gradient-based algorithms that can solve bilevel optimization problems with provable guarantees. However, the existing literature mainly focuses on bilevel problems either without constraints, or featuring only simple constraints that do not couple variables across the upper and lower levels, excluding a range of complex applications. Our paper studies this challenging but less explored scenario and develops a (fully) first-order algorithm, which we term BLOCC, to tackle BiLevel Optimization problems with Coupled Constraints. We establish rigorous convergence theory for the proposed algorithm and demonstrate its effectiveness on two well-known real-world applications - hyperparameter selection in support vector machine (SVM) and infrastructure planning in transportation networks using the real data from the city of Seville.
6/18/2024
Semi-adaptive Synergetic Two-way Pseudoinverse Learning System
Binghong Liu, Ziqi Zhao, Shupan Li, Ke Wang
0
0
Deep learning has become a crucial technology for making breakthroughs in many fields. Nevertheless, it still faces two important challenges in theoretical and applied aspects. The first lies in the shortcomings of gradient descent based learning schemes which are time-consuming and difficult to determine the learning control hyperparameters. Next, the architectural design of the model is usually tricky. In this paper, we propose a semi-adaptive synergetic two-way pseudoinverse learning system, wherein each subsystem encompasses forward learning, backward learning, and feature concatenation modules. The whole system is trained using a non-gradient descent learning algorithm. It simplifies the hyperparameter tuning while improving the training efficiency. The architecture of the subsystems is designed using a data-driven approach that enables automated determination of the depth of the subsystems. We compare our method with the baselines of mainstream non-gradient descent based methods and the results demonstrate the effectiveness of our proposed method. The source code for this paper is available at http://github.com/B-berrypie/Semi-adaptive-Synergetic-Two-way-Pseudoinverse-Learning-System}{http://github.com/B-berrypie/Semi-adaptive-Synergetic-Two-way-Pseudoinverse-Learning-System.
6/28/2024