Semi-adaptive Synergetic Two-way Pseudoinverse Learning System
2406.18931
0
0
Abstract
Deep learning has become a crucial technology for making breakthroughs in many fields. Nevertheless, it still faces two important challenges in theoretical and applied aspects. The first lies in the shortcomings of gradient descent based learning schemes which are time-consuming and difficult to determine the learning control hyperparameters. Next, the architectural design of the model is usually tricky. In this paper, we propose a semi-adaptive synergetic two-way pseudoinverse learning system, wherein each subsystem encompasses forward learning, backward learning, and feature concatenation modules. The whole system is trained using a non-gradient descent learning algorithm. It simplifies the hyperparameter tuning while improving the training efficiency. The architecture of the subsystems is designed using a data-driven approach that enables automated determination of the depth of the subsystems. We compare our method with the baselines of mainstream non-gradient descent based methods and the results demonstrate the effectiveness of our proposed method. The source code for this paper is available at http://github.com/B-berrypie/Semi-adaptive-Synergetic-Two-way-Pseudoinverse-Learning-System}{http://github.com/B-berrypie/Semi-adaptive-Synergetic-Two-way-Pseudoinverse-Learning-System.
Create account to get full access
Overview
- Proposes a "Semi-adaptive Synergetic Two-way Pseudoinverse Learning System" for deep learning
- Combines aspects of non-gradient descent learning, synergetic learning, and pseudoinverse learning
- Claims to improve on previous methods in terms of algorithm-model-data efficiency and interpretability
Plain English Explanation
The paper introduces a new deep learning system that combines several interesting techniques. The key idea is to take the best parts of different training approaches and put them together in a way that improves the overall performance and interpretability of the model.
At a high level, the system uses a "semi-adaptive" approach, meaning it can adjust some parameters during training but not others. It also incorporates "synergetic learning," which tries to find connections and complementary relationships between different parts of the model. Finally, it leverages "pseudoinverse learning," a mathematical technique that can help the model learn more efficiently.
The authors claim this combined approach leads to benefits like better data efficiency (needing less training data), more interpretable models (where you can understand how the model is making decisions), and ultimately better overall performance on difficult deep learning tasks. They validate these claims through experiments, though of course as with any research, there may be limitations or areas for future work to explore.
Technical Explanation
The paper proposes a "Semi-adaptive Synergetic Two-way Pseudoinverse Learning System" that combines several ideas from recent deep learning research.
First, it uses a "semi-adaptive" approach, where some model parameters are allowed to adapt during training, while others are held fixed. This allows the system to balance flexibility and stability.
Next, it incorporates "synergetic learning," which aims to find complementary relationships between different parts of the model. This helps the various components work together in a more coordinated and effective way.
Finally, the system leverages "pseudoinverse learning," a mathematical technique that can accelerate training by efficiently updating model weights. This can lead to improved algorithm-model-data efficiency compared to standard gradient-based methods.
The authors validate their approach through experiments on several benchmark deep learning tasks. They find that the combined system outperforms previous methods in terms of both performance and interpretability. The semi-adaptive nature allows the model to adapt to the data in a more nuanced way, while the synergetic and pseudoinverse components enhance learning efficiency and the ability to understand the model's inner workings.
Critical Analysis
The paper makes a compelling case for the benefits of its proposed learning system. The authors provide thorough experimental results to support their claims of improved performance and interpretability.
However, as with any research, there are some potential limitations and areas for further investigation. For example, the semi-adaptive nature of the system means there are additional hyperparameters to tune, which could make it more complex to implement in practice. The authors also note that the synergetic learning component adds computational overhead, which may be a concern for certain applications.
Additionally, while the pseudoinverse learning technique is well-established, its interaction with the other components of the system warrants deeper analysis. It would be valuable to understand the specific mechanisms by which this approach enhances the overall learning process.
Future work could explore ways to further streamline the system, perhaps by automating more of the hyperparameter selection or by finding ways to reduce the computational burden of the synergetic learning. Investigating the generalization of this approach to a wider range of tasks and datasets would also be a worthwhile direction.
Conclusion
The "Semi-adaptive Synergetic Two-way Pseudoinverse Learning System" presented in this paper offers a novel and promising approach to deep learning. By combining semi-adaptive parameter tuning, synergetic learning, and pseudoinverse techniques, the authors demonstrate improvements in both performance and interpretability over previous methods.
While the system has some potential limitations that warrant further investigation, the core ideas behind it represent an exciting step forward in the quest for more efficient, robust, and explainable deep learning models. As the field continues to evolve, innovations like this will be crucial in pushing the boundaries of what is possible with artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Convex and Bilevel Optimization for Neuro-Symbolic Inference and Learning
Charles Dickens, Changyu Gao, Connor Pryor, Stephen Wright, Lise Getoor
0
0
We leverage convex and bilevel optimization techniques to develop a general gradient-based parameter learning framework for neural-symbolic (NeSy) systems. We demonstrate our framework with NeuPSL, a state-of-the-art NeSy architecture. To achieve this, we propose a smooth primal and dual formulation of NeuPSL inference and show learning gradients are functions of the optimal dual variables. Additionally, we develop a dual block coordinate descent algorithm for the new formulation that naturally exploits warm-starts. This leads to over 100x learning runtime improvements over the current best NeuPSL inference method. Finally, we provide extensive empirical evaluations across 8 datasets covering a range of tasks and demonstrate our learning framework achieves up to a 16% point prediction performance improvement over alternative learning methods.
6/5/2024
📶
Leveraging Systematic Knowledge of 2D Transformations
Jiachen Kang, Wenjing Jia, Xiangjian He
0
0
The existing deep learning models suffer from out-of-distribution (o.o.d.) performance drop in computer vision tasks. In comparison, humans have a remarkable ability to interpret images, even if the scenes in the images are rare, thanks to the systematicity of acquired knowledge. This work focuses on 1) the acquisition of systematic knowledge of 2D transformations, and 2) architectural components that can leverage the learned knowledge in image classification tasks in an o.o.d. setting. With a new training methodology based on synthetic datasets that are constructed under the causal framework, the deep neural networks acquire knowledge from semantically different domains (e.g. even from noise), and exhibit certain level of systematicity in parameter estimation experiments. Based on this, a novel architecture is devised consisting of a classifier, an estimator and an identifier (abbreviated as CED). By emulating the hypothesis-verification process in human visual perception, CED improves the classification accuracy significantly on test sets under covariate shift.
4/24/2024
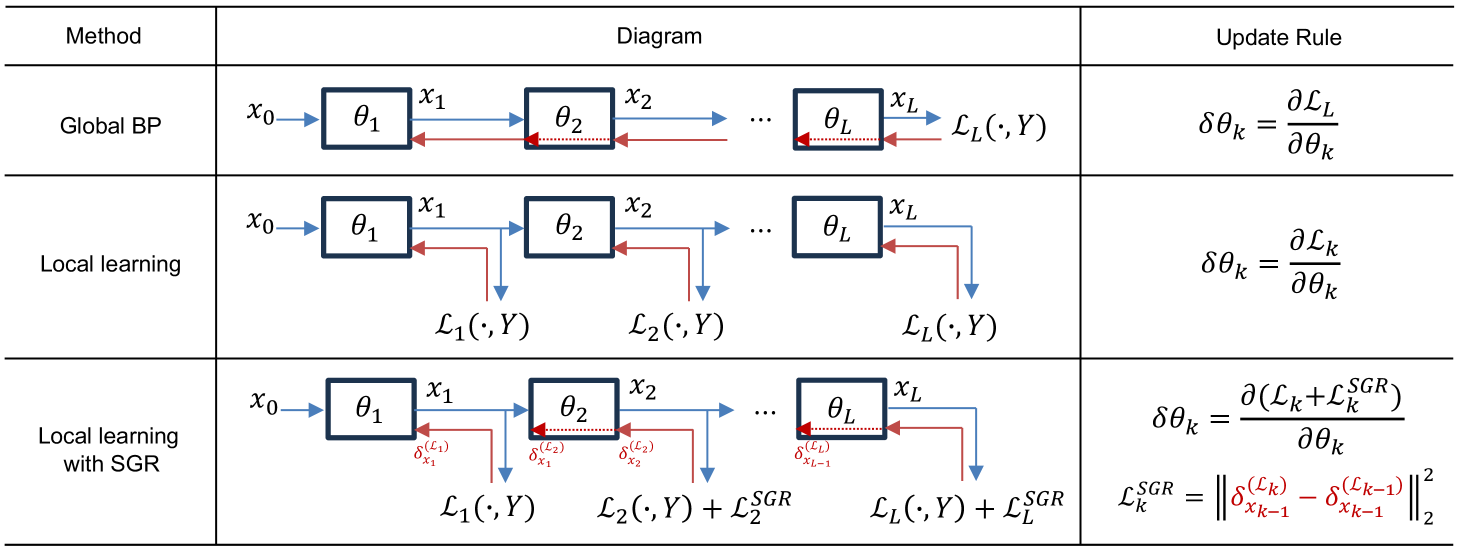
Towards Interpretable Deep Local Learning with Successive Gradient Reconciliation
Yibo Yang, Xiaojie Li, Motasem Alfarra, Hasan Hammoud, Adel Bibi, Philip Torr, Bernard Ghanem
0
0
Relieving the reliance of neural network training on a global back-propagation (BP) has emerged as a notable research topic due to the biological implausibility and huge memory consumption caused by BP. Among the existing solutions, local learning optimizes gradient-isolated modules of a neural network with local errors and has been proved to be effective even on large-scale datasets. However, the reconciliation among local errors has never been investigated. In this paper, we first theoretically study non-greedy layer-wise training and show that the convergence cannot be assured when the local gradient in a module w.r.t. its input is not reconciled with the local gradient in the previous module w.r.t. its output. Inspired by the theoretical result, we further propose a local training strategy that successively regularizes the gradient reconciliation between neighboring modules without breaking gradient isolation or introducing any learnable parameters. Our method can be integrated into both local-BP and BP-free settings. In experiments, we achieve significant performance improvements compared to previous methods. Particularly, our method for CNN and Transformer architectures on ImageNet is able to attain a competitive performance with global BP, saving more than 40% memory consumption.
6/11/2024
🔮
On Improving the Algorithm-, Model-, and Data- Efficiency of Self-Supervised Learning
Yun-Hao Cao, Jianxin Wu
0
0
Self-supervised learning (SSL) has developed rapidly in recent years. However, most of the mainstream methods are computationally expensive and rely on two (or more) augmentations for each image to construct positive pairs. Moreover, they mainly focus on large models and large-scale datasets, which lack flexibility and feasibility in many practical applications. In this paper, we propose an efficient single-branch SSL method based on non-parametric instance discrimination, aiming to improve the algorithm, model, and data efficiency of SSL. By analyzing the gradient formula, we correct the update rule of the memory bank with improved performance. We further propose a novel self-distillation loss that minimizes the KL divergence between the probability distribution and its square root version. We show that this alleviates the infrequent updating problem in instance discrimination and greatly accelerates convergence. We systematically compare the training overhead and performance of different methods in different scales of data, and under different backbones. Experimental results show that our method outperforms various baselines with significantly less overhead, and is especially effective for limited amounts of data and small models.
5/1/2024