ViTGAN: Training GANs with Vision Transformers
2107.04589
0
0
🏋️
Abstract
Recently, Vision Transformers (ViTs) have shown competitive performance on image recognition while requiring less vision-specific inductive biases. In this paper, we investigate if such performance can be extended to image generation. To this end, we integrate the ViT architecture into generative adversarial networks (GANs). For ViT discriminators, we observe that existing regularization methods for GANs interact poorly with self-attention, causing serious instability during training. To resolve this issue, we introduce several novel regularization techniques for training GANs with ViTs. For ViT generators, we examine architectural choices for latent and pixel mapping layers to facilitate convergence. Empirically, our approach, named ViTGAN, achieves comparable performance to the leading CNN-based GAN models on three datasets: CIFAR-10, CelebA, and LSUN bedroom.
Create account to get full access
Overview
- Vision Transformers (ViTs) have shown promising performance on image recognition tasks, requiring less vision-specific inductive biases compared to traditional convolutional neural networks (CNNs).
- This paper investigates whether the performance advantages of ViTs can be extended to image generation tasks by integrating the ViT architecture into generative adversarial networks (GANs).
- The researchers identify and address key challenges in training ViT-based discriminators and generators within a GAN framework.
- Their approach, named ViTGAN, achieves comparable performance to leading CNN-based GAN models on several popular image datasets.
Plain English Explanation
The paper explores using Vision Transformers (ViTs) for generating images, instead of the more common convolutional neural networks (CNNs). ViTs have shown they can be good at recognizing images without needing as many pre-designed features compared to CNNs.
The researchers wanted to see if ViTs could also be effective at generating new images, not just recognizing them. To do this, they integrated ViTs into a generative adversarial network (GAN) - a type of AI model that pits a generator (which tries to create realistic-looking images) against a discriminator (which tries to identify real vs. fake images).
However, the researchers found that existing techniques for training GAN discriminators didn't work well with the self-attention mechanism in ViTs, causing instability during training. To fix this, they developed some new regularization techniques to make training ViT-based GANs more stable.
For the ViT generator part of the GAN, the researchers also had to carefully design the architectural choices to facilitate the model converging during training.
Ultimately, their ViTGAN approach was able to generate images that were comparable in quality to leading CNN-based GAN models on popular datasets like CIFAR-10, CelebA, and LSUN bedrooms.
Technical Explanation
The paper integrates the Vision Transformer (ViT) architecture into generative adversarial networks (GANs) to investigate whether ViT's performance advantages on image recognition can translate to image generation tasks.
For the ViT discriminator, the researchers found that existing GAN regularization methods like gradient penalty [1] and spectral normalization [2] interact poorly with the self-attention mechanism in ViTs, leading to severe training instability. To address this, they propose several novel regularization techniques:
- ViT-specific gradient penalty, which computes the gradient penalty based on the ViT's attention maps rather than raw pixel values.
- Sparsity-inducing regularization, which encourages the ViT discriminator to focus on a sparse set of relevant regions in the image.
- Orthogonal initialization and constrained optimization, which stabilize the training by controlling the spectral norm of the ViT layers.
For the ViT generator, the researchers examine different architectural choices for the latent and pixel mapping layers to facilitate convergence during training. This includes using a multi-layer perceptron for latent mapping and an efficient pixel-shuffle upsampling layer for the output.
Empirically, the proposed ViTGAN approach achieves comparable performance to leading CNN-based GAN models like StyleGAN2 [3] and SNGAN [4] on CIFAR-10, CelebA, and LSUN bedroom datasets.
Critical Analysis
The paper identifies and addresses important challenges in integrating ViTs into the GAN framework, which is a significant contribution to the field of generative modeling. The proposed regularization techniques for ViT discriminators and architectural choices for ViT generators appear well-justified and effectively resolve the training stability issues.
However, the paper does not provide detailed comparisons to other transformer-based GAN models, such as GVT or Channel-ViT. It would be helpful to understand how ViTGAN performs relative to these other approaches.
Additionally, the paper does not address potential issues around the compute-intensive nature of ViTs or their sensitivity to adversarial attacks, which are important considerations for real-world deployment. Further research could explore ways to improve the efficiency and robustness of ViT-based generative models.
Conclusion
This paper demonstrates that the performance advantages of Vision Transformers can be extended to image generation tasks through the ViTGAN framework. By addressing key challenges in training ViT-based discriminators and generators, the researchers have made significant progress in leveraging transformer architectures for high-quality image synthesis.
The ViTGAN approach represents an important step forward in exploring the capabilities of transformer models beyond just recognition tasks. As transformer-based models continue to advance, and efficiently scalable ViT architectures emerge, the potential applications of ViT-powered generative models could expand significantly, with implications for fields like computer vision, digital art, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Convolutional Neural Networks and Vision Transformers for Fashion MNIST Classification: A Literature Review
Sonia Bbouzidi, Ghazala Hcini, Imen Jdey, Fadoua Drira
0
0
Our review explores the comparative analysis between Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) in the domain of image classification, with a particular focus on clothing classification within the e-commerce sector. Utilizing the Fashion MNIST dataset, we delve into the unique attributes of CNNs and ViTs. While CNNs have long been the cornerstone of image classification, ViTs introduce an innovative self-attention mechanism enabling nuanced weighting of different input data components. Historically, transformers have primarily been associated with Natural Language Processing (NLP) tasks. Through a comprehensive examination of existing literature, our aim is to unveil the distinctions between ViTs and CNNs in the context of image classification. Our analysis meticulously scrutinizes state-of-the-art methodologies employing both architectures, striving to identify the factors influencing their performance. These factors encompass dataset characteristics, image dimensions, the number of target classes, hardware infrastructure, and the specific architectures along with their respective top results. Our key goal is to determine the most appropriate architecture between ViT and CNN for classifying images in the Fashion MNIST dataset within the e-commerce industry, while taking into account specific conditions and needs. We highlight the importance of combining these two architectures with different forms to enhance overall performance. By uniting these architectures, we can take advantage of their unique strengths, which may lead to more precise and reliable models for e-commerce applications. CNNs are skilled at recognizing local patterns, while ViTs are effective at grasping overall context, making their combination a promising strategy for boosting image classification performance.
6/6/2024
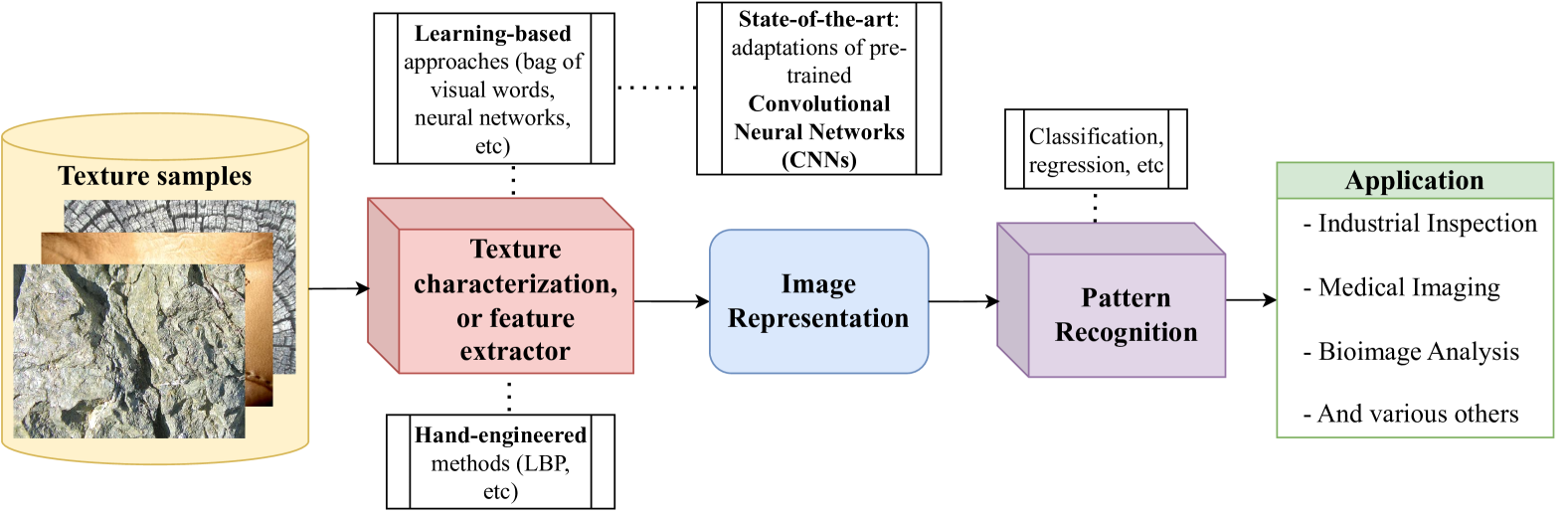
A Comparative Survey of Vision Transformers for Feature Extraction in Texture Analysis
Leonardo Scabini, Andre Sacilotti, Kallil M. Zielinski, Lucas C. Ribas, Bernard De Baets, Odemir M. Bruno
0
0
Texture, a significant visual attribute in images, has been extensively investigated across various image recognition applications. Convolutional Neural Networks (CNNs), which have been successful in many computer vision tasks, are currently among the best texture analysis approaches. On the other hand, Vision Transformers (ViTs) have been surpassing the performance of CNNs on tasks such as object recognition, causing a paradigm shift in the field. However, ViTs have so far not been scrutinized for texture recognition, hindering a proper appreciation of their potential in this specific setting. For this reason, this work explores various pre-trained ViT architectures when transferred to tasks that rely on textures. We review 21 different ViT variants and perform an extensive evaluation and comparison with CNNs and hand-engineered models on several tasks, such as assessing robustness to changes in texture rotation, scale, and illumination, and distinguishing color textures, material textures, and texture attributes. The goal is to understand the potential and differences among these models when directly applied to texture recognition, using pre-trained ViTs primarily for feature extraction and employing linear classifiers for evaluation. We also evaluate their efficiency, which is one of the main drawbacks in contrast to other methods. Our results show that ViTs generally outperform both CNNs and hand-engineered models, especially when using stronger pre-training and tasks involving in-the-wild textures (images from the internet). We highlight the following promising models: ViT-B with DINO pre-training, BeiTv2, and the Swin architecture, as well as the EfficientFormer as a low-cost alternative. In terms of efficiency, although having a higher number of GFLOPs and parameters, ViT-B and BeiT(v2) can achieve a lower feature extraction time on GPUs compared to ResNet50.
6/11/2024
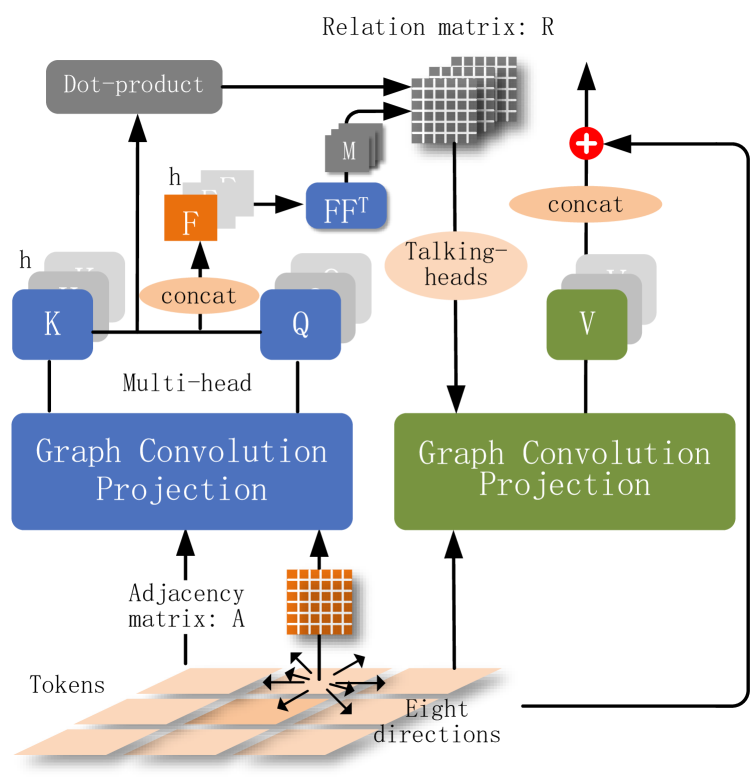
GvT: A Graph-based Vision Transformer with Talking-Heads Utilizing Sparsity, Trained from Scratch on Small Datasets
Dongjing Shan, guiqiang chen
0
0
Vision Transformers (ViTs) have achieved impressive results in large-scale image classification. However, when training from scratch on small datasets, there is still a significant performance gap between ViTs and Convolutional Neural Networks (CNNs), which is attributed to the lack of inductive bias. To address this issue, we propose a Graph-based Vision Transformer (GvT) that utilizes graph convolutional projection and graph-pooling. In each block, queries and keys are calculated through graph convolutional projection based on the spatial adjacency matrix, while dot-product attention is used in another graph convolution to generate values. When using more attention heads, the queries and keys become lower-dimensional, making their dot product an uninformative matching function. To overcome this low-rank bottleneck in attention heads, we employ talking-heads technology based on bilinear pooled features and sparse selection of attention tensors. This allows interaction among filtered attention scores and enables each attention mechanism to depend on all queries and keys. Additionally, we apply graph-pooling between two intermediate blocks to reduce the number of tokens and aggregate semantic information more effectively. Our experimental results show that GvT produces comparable or superior outcomes to deep convolutional networks and surpasses vision transformers without pre-training on large datasets. The code for our proposed model is publicly available on the website.
4/9/2024
👀
Vision Transformers Need Registers
Timoth'ee Darcet, Maxime Oquab, Julien Mairal, Piotr Bojanowski
0
0
Transformers have recently emerged as a powerful tool for learning visual representations. In this paper, we identify and characterize artifacts in feature maps of both supervised and self-supervised ViT networks. The artifacts correspond to high-norm tokens appearing during inference primarily in low-informative background areas of images, that are repurposed for internal computations. We propose a simple yet effective solution based on providing additional tokens to the input sequence of the Vision Transformer to fill that role. We show that this solution fixes that problem entirely for both supervised and self-supervised models, sets a new state of the art for self-supervised visual models on dense visual prediction tasks, enables object discovery methods with larger models, and most importantly leads to smoother feature maps and attention maps for downstream visual processing.
4/15/2024