Cost-Sensitive Multi-Fidelity Bayesian Optimization with Transfer of Learning Curve Extrapolation
2405.17918
0
0
Abstract
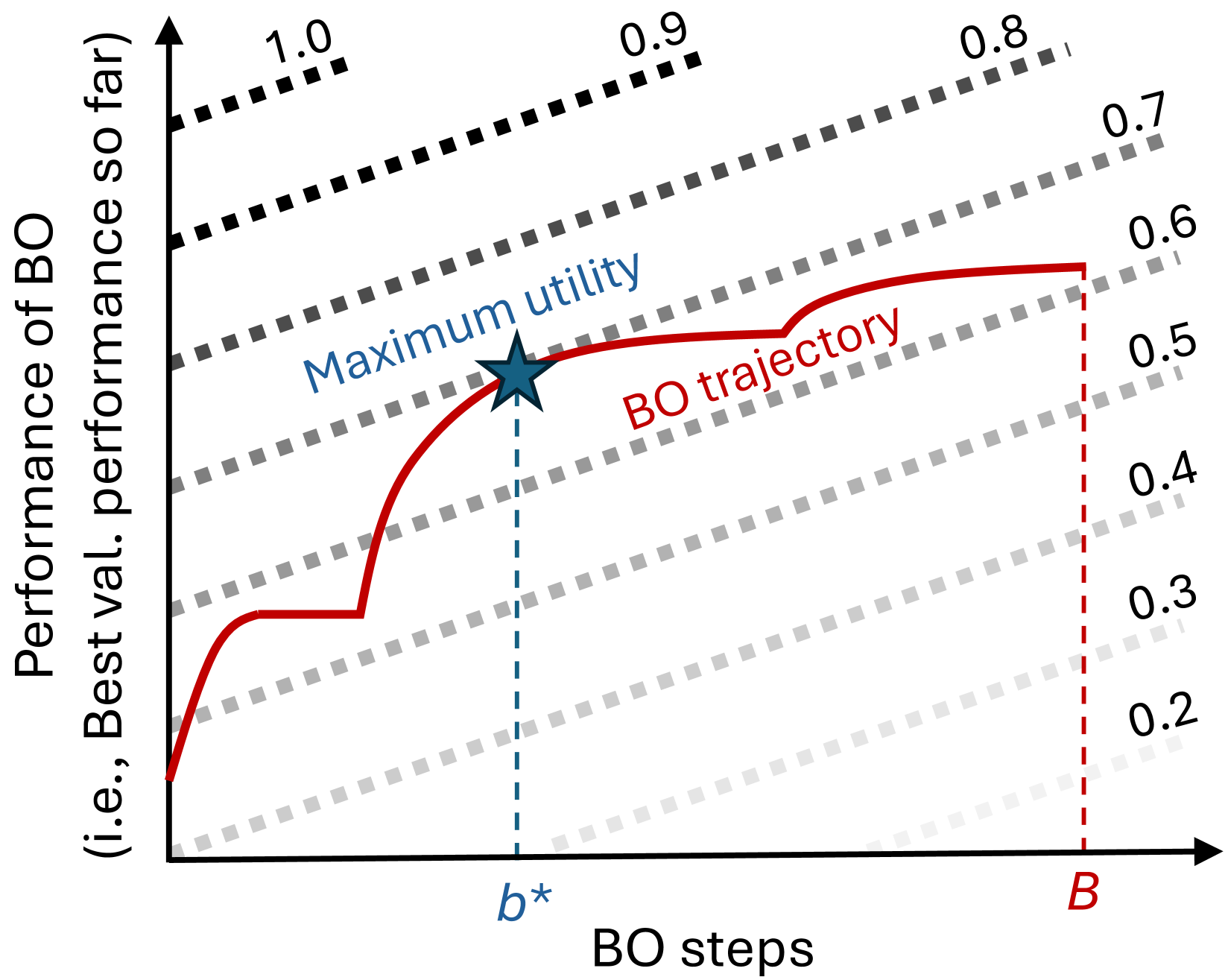
In this paper, we address the problem of cost-sensitive multi-fidelity Bayesian Optimization (BO) for efficient hyperparameter optimization (HPO). Specifically, we assume a scenario where users want to early-stop the BO when the performance improvement is not satisfactory with respect to the required computational cost. Motivated by this scenario, we introduce utility, which is a function predefined by each user and describes the trade-off between cost and performance of BO. This utility function, combined with our novel acquisition function and stopping criterion, allows us to dynamically choose for each BO step the best configuration that we expect to maximally improve the utility in future, and also automatically stop the BO around the maximum utility. Further, we improve the sample efficiency of existing learning curve (LC) extrapolation methods with transfer learning, while successfully capturing the correlations between different configurations to develop a sensible surrogate function for multi-fidelity BO. We validate our algorithm on various LC datasets and found it outperform all the previous multi-fidelity BO and transfer-BO baselines we consider, achieving significantly better trade-off between cost and performance of BO.
Create account to get full access
Overview
- This paper presents a framework for trajectory-based multi-objective hyperparameter optimization (TMHO) for machine learning models.
- The approach combines Bayesian optimization (BO) and evolutionary algorithms to efficiently explore the hyperparameter space and find optimal configurations that balance multiple competing objectives.
- The authors demonstrate the effectiveness of TMHO on several benchmark problems and real-world applications, showing improvements over traditional single-objective BO methods.
Plain English Explanation
The paper discusses a technique called Trajectory-Based Multi-Objective Hyperparameter Optimization (TMHO). This is a way to find the best settings, or hyperparameters, for machine learning models when there are multiple important factors to consider, like accuracy and speed.
Traditionally, hyperparameter optimization has focused on optimizing a single objective, like minimizing error. However, in many real-world applications, there are trade-offs between different goals that need to be balanced. TMHO addresses this by combining two powerful optimization approaches - Bayesian optimization and evolutionary algorithms.
The key idea is to efficiently explore the space of possible hyperparameter settings, comparing how well each one does on the multiple objectives of interest. This allows the method to identify a set of high-performing configurations that represent the best trade-offs. For example, in training a machine learning model, TMHO can find settings that deliver both high accuracy and fast inference times.
Technical Explanation
The Trajectory-Based Multi-Objective Hyperparameter Optimization (TMHO) framework combines Bayesian optimization (BO) and evolutionary algorithms to efficiently search the hyperparameter space and identify optimal configurations that balance multiple competing objectives.
The core steps of TMHO are:
- Initialize the search by sampling a set of hyperparameter configurations.
- Evaluate each configuration on the multiple objectives of interest.
- Use BO to build a surrogate model that approximates the objective functions.
- Apply an evolutionary algorithm to generate new candidate configurations by mutation and crossover of the current population.
- Evaluate the new candidates and update the BO model.
- Repeat steps 3-5, using the BO model to guide the evolutionary search towards the Pareto-optimal front.
By interleaving BO and evolutionary optimization, TMHO is able to efficiently explore the hyperparameter space and converge to a diverse set of high-performing configurations that represent different trade-offs between the objectives.
The authors validate TMHO on several benchmark multi-objective optimization problems, as well as real-world applications in neural architecture search and multi-task learning. The results demonstrate that TMHO outperforms traditional single-objective BO methods, as well as other multi-objective optimization techniques.
Critical Analysis
The Trajectory-Based Multi-Objective Hyperparameter Optimization (TMHO) framework provides a compelling approach for addressing the common challenge of balancing multiple, often competing objectives in hyperparameter optimization.
One potential limitation is the computational cost of the method, as it requires repeatedly evaluating candidate configurations on the multiple objectives. The authors note that efficient data-driven prior learning and adaptive approaches to Bayesian optimization could help mitigate this issue.
Additionally, the paper focuses on static optimization problems, but many real-world applications involve dynamic or evolving objectives. An interesting direction for future research would be to extend TMHO to handle such time-varying multi-objective scenarios.
Overall, the TMHO framework represents a valuable contribution to the field of hyperparameter optimization, providing a principled approach to balancing multiple competing goals. The results demonstrate its potential to improve the performance and efficiency of complex machine learning models in a wide range of applications.
Conclusion
The Trajectory-Based Multi-Objective Hyperparameter Optimization (TMHO) framework addresses an important challenge in machine learning by enabling the optimization of multiple, often competing objectives when tuning hyperparameters.
By combining Bayesian optimization and evolutionary algorithms, TMHO can efficiently explore the hyperparameter space and identify a diverse set of high-performing configurations that represent the best trade-offs between the objectives of interest. The authors demonstrate the effectiveness of TMHO on several benchmark problems and real-world applications, showing improvements over traditional single-objective optimization methods.
This work has significant implications for the development of more robust and versatile machine learning models, as it allows researchers and practitioners to balance critical factors like accuracy, speed, fairness, and resource efficiency when training their models. As machine learning continues to be applied to an ever-widening range of domains, tools like TMHO will become increasingly important for unlocking the full potential of these powerful techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
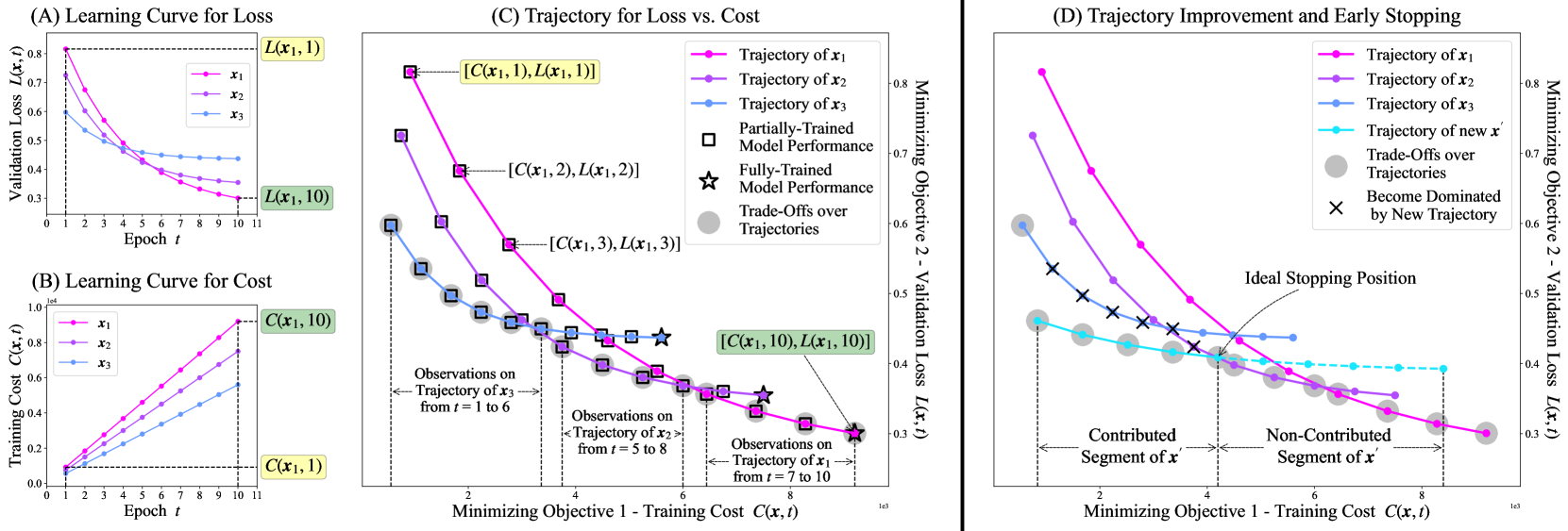
Trajectory-Based Multi-Objective Hyperparameter Optimization for Model Retraining
Wenyu Wang, Zheyi Fan, Szu Hui Ng
0
0
Training machine learning models inherently involves a resource-intensive and noisy iterative learning procedure that allows epoch-wise monitoring of the model performance. However, in multi-objective hyperparameter optimization scenarios, the insights gained from the iterative learning procedure typically remain underutilized. We notice that tracking the model performance across multiple epochs under a hyperparameter setting creates a trajectory in the objective space and that trade-offs along the trajectories are often overlooked despite their potential to offer valuable insights to decision-making for model retraining. Therefore, in this study, we propose to enhance the multi-objective hyperparameter optimization problem by having training epochs as an additional decision variable to incorporate trajectory information. Correspondingly, we present a novel trajectory-based multi-objective Bayesian optimization algorithm characterized by two features: 1) an acquisition function that captures the improvement made by the predictive trajectory of any hyperparameter setting and 2) a multi-objective early stopping mechanism that determines when to terminate the trajectory to maximize epoch efficiency. Numerical experiments on diverse synthetic simulations and hyperparameter tuning benchmarks indicate that our algorithm outperforms the state-of-the-art multi-objective optimizers in both locating better trade-offs and tuning efficiency.
5/27/2024

MALIBO: Meta-learning for Likelihood-free Bayesian Optimization
Jiarong Pan, Stefan Falkner, Felix Berkenkamp, Joaquin Vanschoren
0
0
Bayesian optimization (BO) is a popular method to optimize costly black-box functions. While traditional BO optimizes each new target task from scratch, meta-learning has emerged as a way to leverage knowledge from related tasks to optimize new tasks faster. However, existing meta-learning BO methods rely on surrogate models that suffer from scalability issues and are sensitive to observations with different scales and noise types across tasks. Moreover, they often overlook the uncertainty associated with task similarity. This leads to unreliable task adaptation when only limited observations are obtained or when the new tasks differ significantly from the related tasks. To address these limitations, we propose a novel meta-learning BO approach that bypasses the surrogate model and directly learns the utility of queries across tasks. Our method explicitly models task uncertainty and includes an auxiliary model to enable robust adaptation to new tasks. Extensive experiments show that our method demonstrates strong anytime performance and outperforms state-of-the-art meta-learning BO methods in various benchmarks.
7/1/2024
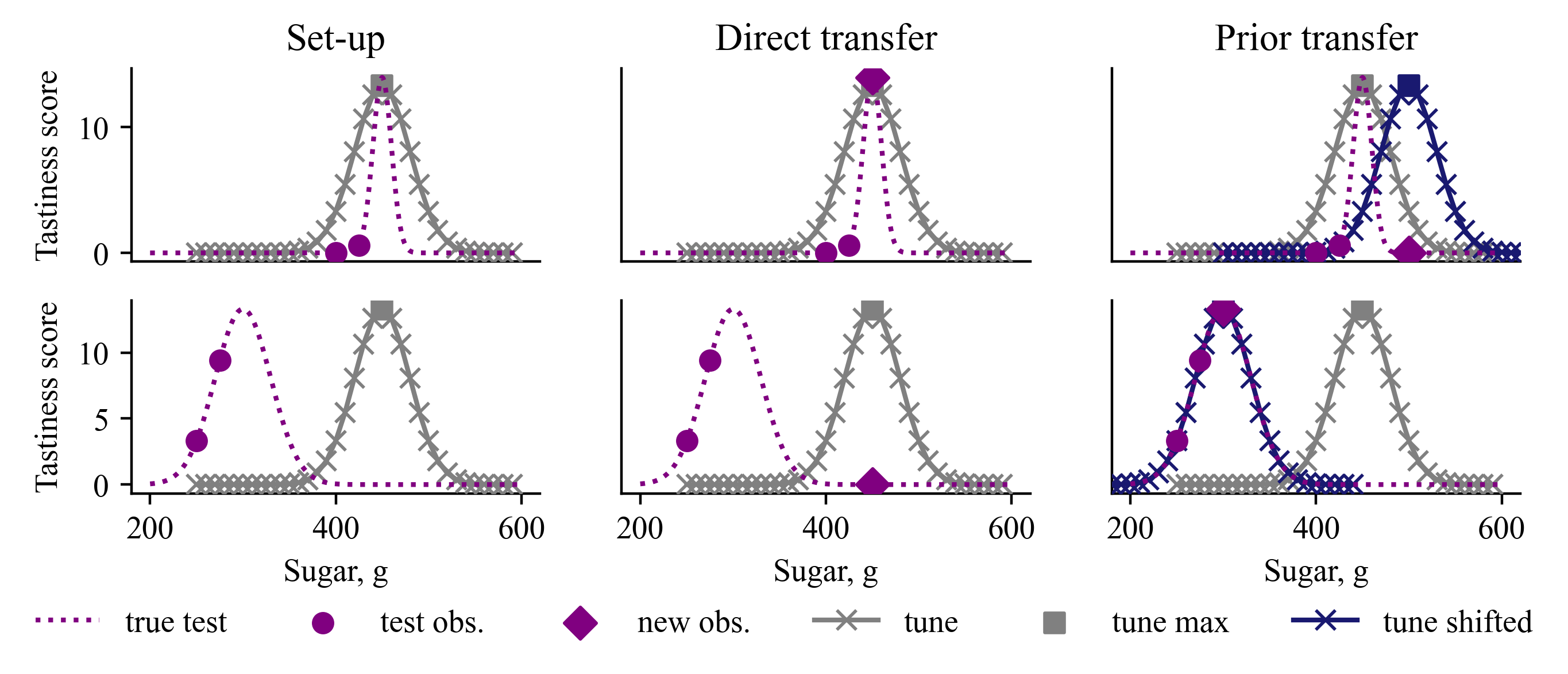
Data-driven Prior Learning for Bayesian Optimisation
Sigrid Passano Hellan, Christopher G. Lucas, Nigel H. Goddard
0
0
Transfer learning for Bayesian optimisation has generally assumed a strong similarity between optimisation tasks, with at least a subset having similar optimal inputs. This assumption can reduce computational costs, but it is violated in a wide range of optimisation problems where transfer learning may nonetheless be useful. We replace this assumption with a weaker one only requiring the shape of the optimisation landscape to be similar, and analyse the recent method Prior Learning for Bayesian Optimisation - PLeBO - in this setting. By learning priors for the hyperparameters of the Gaussian process surrogate model we can better approximate the underlying function, especially for few function evaluations. We validate the learned priors and compare to a breadth of transfer learning approaches, using synthetic data and a recent air pollution optimisation problem as benchmarks. We show that PLeBO and prior transfer find good inputs in fewer evaluations.
4/22/2024
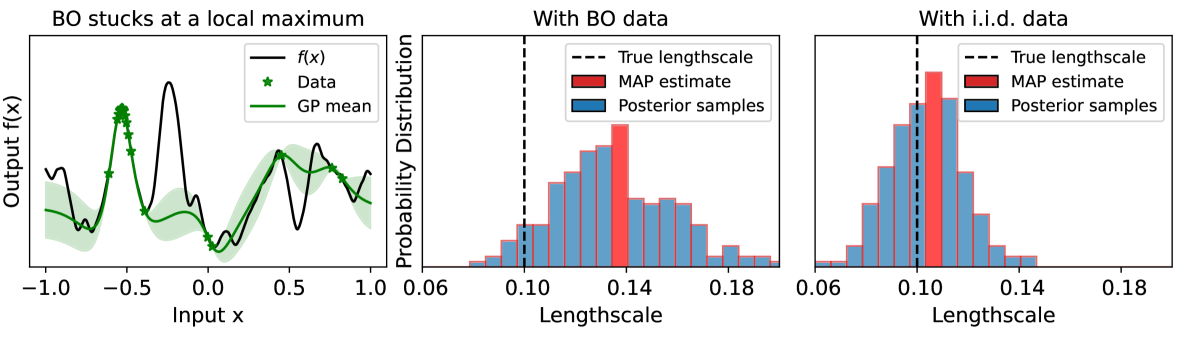
Provably Efficient Bayesian Optimization with Unbiased Gaussian Process Hyperparameter Estimation
Huong Ha, Vu Nguyen, Hung Tran-The, Hongyu Zhang, Xiuzhen Zhang, Anton van den Hengel
0
0
Gaussian process (GP) based Bayesian optimization (BO) is a powerful method for optimizing black-box functions efficiently. The practical performance and theoretical guarantees of this approach depend on having the correct GP hyperparameter values, which are usually unknown in advance and need to be estimated from the observed data. However, in practice, these estimations could be incorrect due to biased data sampling strategies used in BO. This can lead to degraded performance and break the sub-linear global convergence guarantee of BO. To address this issue, we propose a new BO method that can sub-linearly converge to the objective function's global optimum even when the true GP hyperparameters are unknown in advance and need to be estimated from the observed data. Our method uses a multi-armed bandit technique (EXP3) to add random data points to the BO process, and employs a novel training loss function for the GP hyperparameter estimation process that ensures consistent estimation. We further provide theoretical analysis of our proposed method. Finally, we demonstrate empirically that our method outperforms existing approaches on various synthetic and real-world problems.
6/7/2024