Counterfactual Fairness by Combining Factual and Counterfactual Predictions

0

Sign in to get full access
Overview
- The paper proposes a method for achieving counterfactual fairness by combining factual and counterfactual predictions.
- Counterfactual fairness aims to ensure that the predictions made by a model would be the same for an individual, regardless of their protected attributes (e.g., race, gender).
- The method involves training two models: one to make factual predictions and another to make counterfactual predictions, then combining these predictions to achieve fair outcomes.
Plain English Explanation
Imagine you're applying for a loan, and the bank uses an AI model to decide whether to approve your application. The model might look at factors like your income, credit history, and other personal information. However, the model could also be influenced by protected attributes like your race or gender, leading to unfair decisions.
Counterfactual fairness aims to address this by ensuring the model's predictions would be the same, regardless of your protected attributes. The key idea is to train the model to make two types of predictions:
- Factual predictions: These are the model's regular predictions based on the actual information about you.
- Counterfactual predictions: These are predictions about what the outcome would be if you had different protected attributes, like a different race or gender.
By combining these factual and counterfactual predictions, the model can make fair decisions that are not influenced by your protected attributes. This helps ensure that the loan decisions are based on your true qualifications, not on factors you can't control.
Technical Explanation
The paper proposes a method for achieving counterfactual fairness by training two models: a factual model and a counterfactual model.
The factual model is trained to make predictions based on the actual input features, including any protected attributes. The counterfactual model, on the other hand, is trained to make predictions about what the outcome would be if the protected attributes were different.
To train the counterfactual model, the authors use a technique called adversarial debiasing. This involves adding an adversarial component to the training process that encourages the model to remove any influence of the protected attributes on the predictions.
Once the factual and counterfactual models are trained, the authors combine their outputs to make the final prediction. Specifically, they take a weighted average of the factual and counterfactual predictions, with the weights determined by the desired level of counterfactual fairness.
The authors evaluate their approach on several benchmark datasets and show that it can achieve high levels of counterfactual fairness while maintaining good predictive performance.
Critical Analysis
The paper presents a well-designed and technically sound approach for achieving counterfactual fairness. However, there are a few potential limitations and areas for further research:
-
Interpretability: The paper does not address the interpretability of the combined factual and counterfactual predictions. It may be important to understand how the final predictions are derived and how much weight is given to the factual and counterfactual components.
-
Robustness: The paper does not explore the robustness of the approach to different types of biases or dataset shifts. Further research could investigate the performance of the method in more diverse and challenging scenarios.
-
Real-world deployment: The paper focuses on benchmark datasets and does not discuss the challenges of deploying this approach in real-world settings, where data quality, feature engineering, and other practical considerations may play a significant role.
Overall, the paper presents a promising approach for achieving counterfactual fairness, but further research and validation would be needed to assess its practical applicability and limitations.
Conclusion
The paper proposes a novel method for achieving counterfactual fairness by combining factual and counterfactual predictions. This approach aims to ensure that model predictions are not influenced by protected attributes, such as race or gender, providing a more equitable decision-making process.
The key technical contribution is the training of two separate models: one for factual predictions and another for counterfactual predictions. By combining these outputs, the method can produce fair predictions that are robust to the influence of protected attributes.
While the paper demonstrates the effectiveness of this approach on benchmark datasets, further research is needed to address potential limitations, such as interpretability and real-world robustness. Nonetheless, the proposed method represents an important step towards developing fairer AI systems that can have a positive impact on society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Counterfactual Fairness by Combining Factual and Counterfactual Predictions
Zeyu Zhou, Tianci Liu, Ruqi Bai, Jing Gao, Murat Kocaoglu, David I. Inouye
In high-stake domains such as healthcare and hiring, the role of machine learning (ML) in decision-making raises significant fairness concerns. This work focuses on Counterfactual Fairness (CF), which posits that an ML model's outcome on any individual should remain unchanged if they had belonged to a different demographic group. Previous works have proposed methods that guarantee CF. Notwithstanding, their effects on the model's predictive performance remains largely unclear. To fill in this gap, we provide a theoretical study on the inherent trade-off between CF and predictive performance in a model-agnostic manner. We first propose a simple but effective method to cast an optimal but potentially unfair predictor into a fair one without losing the optimality. By analyzing its excess risk in order to achieve CF, we quantify this inherent trade-off. Further analysis on our method's performance with access to only incomplete causal knowledge is also conducted. Built upon it, we propose a performant algorithm that can be applied in such scenarios. Experiments on both synthetic and semi-synthetic datasets demonstrate the validity of our analysis and methods.
Read more9/4/2024
0
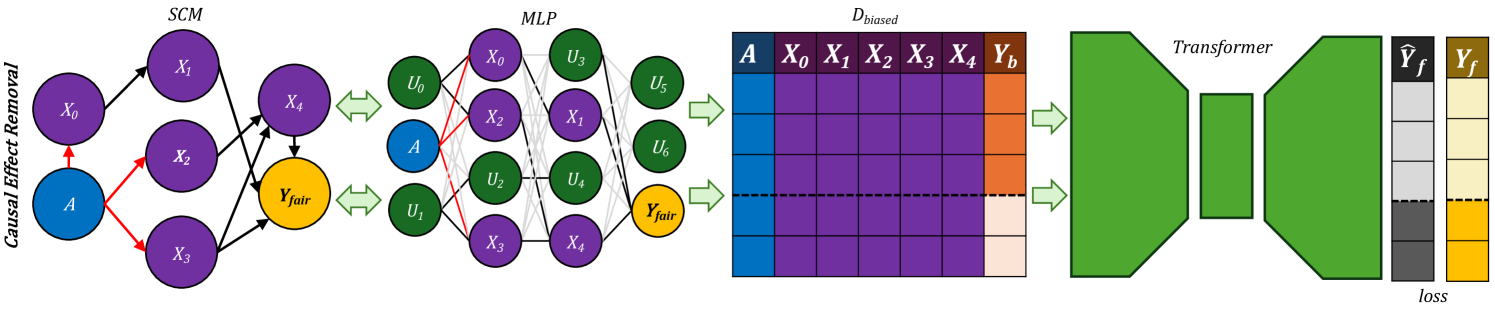
FairPFN: Transformers Can do Counterfactual Fairness
Jake Robertson, Noah Hollmann, Noor Awad, Frank Hutter
Machine Learning systems are increasingly prevalent across healthcare, law enforcement, and finance but often operate on historical data, which may carry biases against certain demographic groups. Causal and counterfactual fairness provides an intuitive way to define fairness that closely aligns with legal standards. Despite its theoretical benefits, counterfactual fairness comes with several practical limitations, largely related to the reliance on domain knowledge and approximate causal discovery techniques in constructing a causal model. In this study, we take a fresh perspective on counterfactually fair prediction, building upon recent work in in context learning (ICL) and prior fitted networks (PFNs) to learn a transformer called FairPFN. This model is pretrained using synthetic fairness data to eliminate the causal effects of protected attributes directly from observational data, removing the requirement of access to the correct causal model in practice. In our experiments, we thoroughly assess the effectiveness of FairPFN in eliminating the causal impact of protected attributes on a series of synthetic case studies and real world datasets. Our findings pave the way for a new and promising research area: transformers for causal and counterfactual fairness.
Read more7/9/2024
🤿
0
Ensuring Equitable Financial Decisions: Leveraging Counterfactual Fairness and Deep Learning for Bias
Saish Shinde
Concerns regarding fairness and bias have been raised in recent years due to the growing use of machine learning models in crucial decision-making processes, especially when it comes to delicate characteristics like gender. In order to address biases in machine learning models, this research paper investigates advanced bias mitigation techniques, with a particular focus on counterfactual fairness in conjunction with data augmentation. The study looks into how these integrated approaches can lessen gender bias in the financial industry, specifically in loan approval procedures. We show that these approaches are effective in achieving more equitable results through thorough testing and assessment on a skewed financial dataset. The findings emphasize how crucial it is to use fairness-aware techniques when creating machine learning models in order to guarantee morally righteous and impartial decision-making.
Read more8/30/2024
0
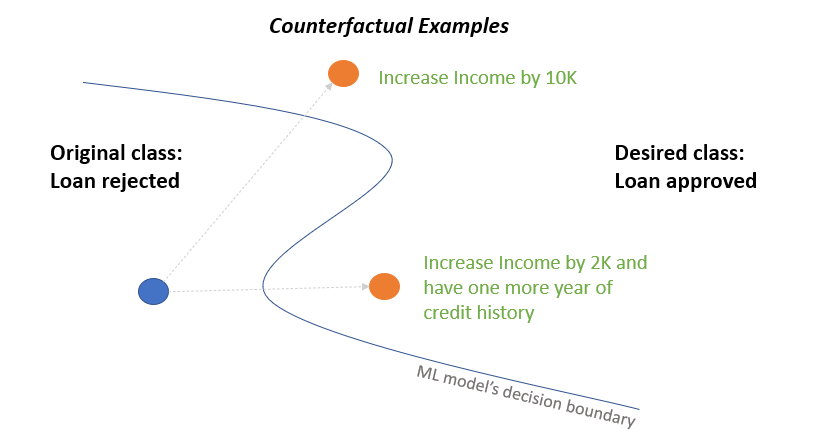
A Framework for Feasible Counterfactual Exploration incorporating Causality, Sparsity and Density
Kleopatra Markou, Dimitrios Tomaras, Vana Kalogeraki, Dimitrios Gunopulos
The imminent need to interpret the output of a Machine Learning model with counterfactual (CF) explanations - via small perturbations to the input - has been notable in the research community. Although the variety of CF examples is important, the aspect of them being feasible at the same time, does not necessarily apply in their entirety. This work uses different benchmark datasets to examine through the preservation of the logical causal relations of their attributes, whether CF examples can be generated after a small amount of changes to the original input, be feasible and actually useful to the end-user in a real-world case. To achieve this, we used a black box model as a classifier, to distinguish the desired from the input class and a Variational Autoencoder (VAE) to generate feasible CF examples. As an extension, we also extracted two-dimensional manifolds (one for each dataset) that located the majority of the feasible examples, a representation that adequately distinguished them from infeasible ones. For our experimentation we used three commonly used datasets and we managed to generate feasible and at the same time sparse, CF examples that satisfy all possible predefined causal constraints, by confirming their importance with the attributes in a dataset.
Read more4/23/2024