Counterfactual Reasoning for Multi-Label Image Classification via Patching-Based Training

0

Sign in to get full access
Overview
- This paper introduces a novel approach for multi-label image classification using "counterfactual reasoning" and "patching-based training".
- The key idea is to leverage counterfactual examples, where certain object patches are replaced, to improve the model's ability to reason about the presence or absence of different objects in an image.
- The proposed method is evaluated on several multi-label image classification benchmarks and shown to outperform existing approaches.
Plain English Explanation
In machine learning, multi-label image classification is the task of identifying all the different objects or concepts present in an image, rather than just a single dominant object. This is a challenging problem because real-world images often contain multiple, overlapping elements.
The authors of this paper present a new technique to address this challenge, called "counterfactual reasoning". The core idea is to generate "counterfactual examples" - modified versions of the original images where certain objects have been removed or replaced. By training the model to correctly classify these altered images, it learns to better understand the individual contributions of different objects to the overall classification.
The method works by "patching" the input images - carefully cutting out and replacing specific image regions. This allows the model to learn how the presence or absence of different visual elements impacts the final predictions. The authors show that this "patching-based training" approach leads to significant improvements in multi-label image classification accuracy compared to existing techniques.
Overall, this research advances the state-of-the-art in a important computer vision task, with potential applications in areas like autonomous driving, image search, and content moderation. By harnessing counterfactual reasoning, the model can better grasp the nuanced relationships between objects in complex scenes.
Technical Explanation
The key technical contributions of this paper are:
-
Counterfactual Reasoning: The authors propose a novel counterfactual reasoning framework for multi-label image classification. This involves generating counterfactual examples by [object Object] - selectively replacing or removing objects in the input images.
-
Patching-Based Training: The model is trained not only on the original images, but also on these counterfactual examples. This "patching-based training" approach allows the model to learn the individual importance of different visual elements for the final classification.
-
Multi-Label Evaluation: The proposed method is evaluated on several standard multi-label image classification benchmarks, including [object Object] and [object Object]. The results demonstrate significant improvements over existing state-of-the-art approaches.
The high-level architecture of the model involves a backbone CNN (e.g. ResNet) that encodes the input image, followed by a multi-label classification head. During training, the model is exposed to both the original images and the counterfactual examples generated via selective patching. This encourages the model to learn robust visual representations that capture the individual contributions of different objects.
The authors also introduce several technical innovations, such as a strategic patching strategy to generate the most informative counterfactual examples, and a multi-label loss function that accounts for label dependencies.
Critical Analysis
One key strength of this work is the innovative use of counterfactual reasoning to tackle the multi-label image classification problem. By forcing the model to reason about the impact of individual objects, the authors show it can learn more nuanced and effective visual representations.
However, the paper does acknowledge some limitations. The proposed patching strategy, while effective, is not guaranteed to generate the optimal counterfactual examples. There may be more sophisticated techniques to create even more informative altered images. Additionally, the computational overhead of generating and training on the counterfactual data could be non-trivial, especially for larger-scale applications.
Further research could explore ways to [object Object], potentially leveraging recent advancements in [object Object]. Additionally, the authors could investigate how their patching-based approach compares to other forms of [object Object] for multi-label classification.
Overall, this paper presents a promising and insightful step forward in the field of multi-label image recognition, with the clever use of counterfactual reasoning as a core technical innovation.
Conclusion
This paper introduces a novel "patching-based training" approach for multi-label image classification, leveraging counterfactual reasoning to improve model performance. By exposing the model to strategically altered images where specific objects have been removed or replaced, the authors show it can learn more robust and nuanced visual representations.
The proposed method outperforms existing state-of-the-art techniques on several benchmark datasets, demonstrating the power of this counterfactual reasoning framework. This work represents an important advance in multi-label classification, with potential applications in areas like autonomous systems, content moderation, and image understanding.
While the paper acknowledges some limitations, the core ideas introduced here open up promising avenues for future research, such as more sophisticated counterfactual example generation and further explorations of data augmentation techniques for this challenging computer vision task.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Counterfactual Reasoning for Multi-Label Image Classification via Patching-Based Training
Ming-Kun Xie, Jia-Hao Xiao, Pei Peng, Gang Niu, Masashi Sugiyama, Sheng-Jun Huang
The key to multi-label image classification (MLC) is to improve model performance by leveraging label correlations. Unfortunately, it has been shown that overemphasizing co-occurrence relationships can cause the overfitting issue of the model, ultimately leading to performance degradation. In this paper, we provide a causal inference framework to show that the correlative features caused by the target object and its co-occurring objects can be regarded as a mediator, which has both positive and negative impacts on model predictions. On the positive side, the mediator enhances the recognition performance of the model by capturing co-occurrence relationships; on the negative side, it has the harmful causal effect that causes the model to make an incorrect prediction for the target object, even when only co-occurring objects are present in an image. To address this problem, we propose a counterfactual reasoning method to measure the total direct effect, achieved by enhancing the direct effect caused only by the target object. Due to the unknown location of the target object, we propose patching-based training and inference to accomplish this goal, which divides an image into multiple patches and identifies the pivot patch that contains the target object. Experimental results on multiple benchmark datasets with diverse configurations validate that the proposed method can achieve state-of-the-art performance.
Read more6/14/2024
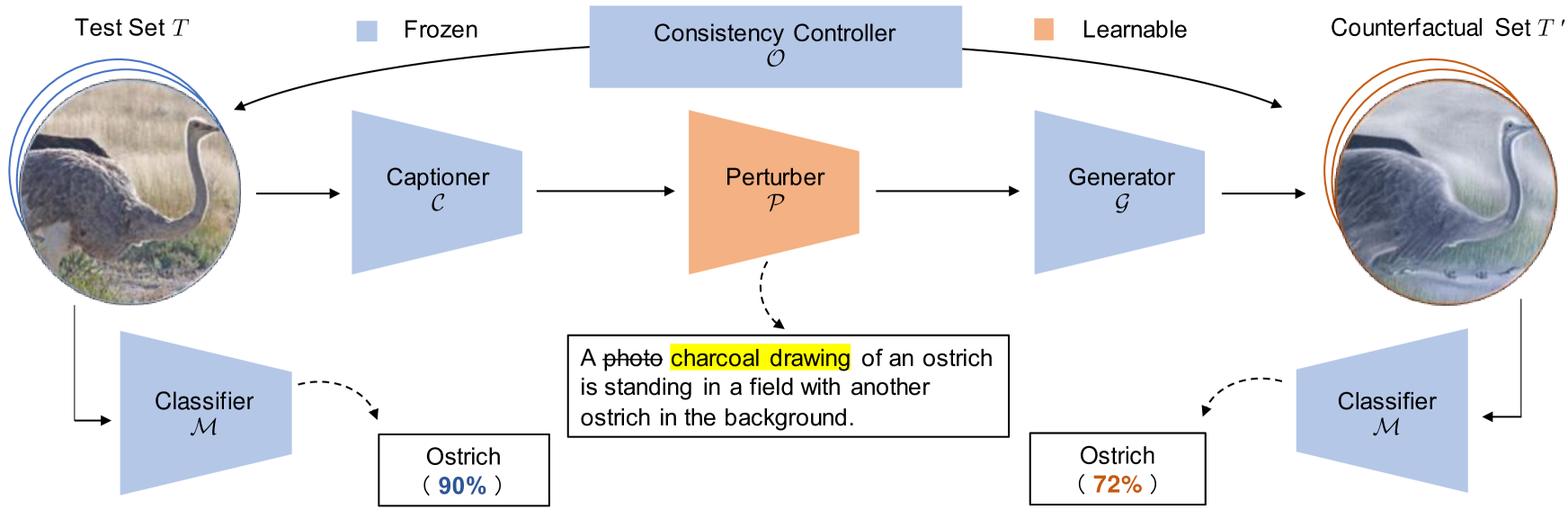
0
Reinforcing Pre-trained Models Using Counterfactual Images
Xiang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
This paper proposes a novel framework to reinforce classification models using language-guided generated counterfactual images. Deep learning classification models are often trained using datasets that mirror real-world scenarios. In this training process, because learning is based solely on correlations with labels, there is a risk that models may learn spurious relationships, such as an overreliance on features not central to the subject, like background elements in images. However, due to the black-box nature of the decision-making process in deep learning models, identifying and addressing these vulnerabilities has been particularly challenging. We introduce a novel framework for reinforcing the classification models, which consists of a two-stage process. First, we identify model weaknesses by testing the model using the counterfactual image dataset, which is generated by perturbed image captions. Subsequently, we employ the counterfactual images as an augmented dataset to fine-tune and reinforce the classification model. Through extensive experiments on several classification models across various datasets, we revealed that fine-tuning with a small set of counterfactual images effectively strengthens the model.
Read more6/21/2024

0
Learning to Rank Patches for Unbiased Image Redundancy Reduction
Yang Luo, Zhineng Chen, Peng Zhou, Zuxuan Wu, Xieping Gao, Yu-Gang Jiang
Images suffer from heavy spatial redundancy because pixels in neighboring regions are spatially correlated. Existing approaches strive to overcome this limitation by reducing less meaningful image regions. However, current leading methods rely on supervisory signals. They may compel models to preserve content that aligns with labeled categories and discard content belonging to unlabeled categories. This categorical inductive bias makes these methods less effective in real-world scenarios. To address this issue, we propose a self-supervised framework for image redundancy reduction called Learning to Rank Patches (LTRP). We observe that image reconstruction of masked image modeling models is sensitive to the removal of visible patches when the masking ratio is high (e.g., 90%). Building upon it, we implement LTRP via two steps: inferring the semantic density score of each patch by quantifying variation between reconstructions with and without this patch, and learning to rank the patches with the pseudo score. The entire process is self-supervised, thus getting out of the dilemma of categorical inductive bias. We design extensive experiments on different datasets and tasks. The results demonstrate that LTRP outperforms both supervised and other self-supervised methods due to the fair assessment of image content.
Read more4/26/2024
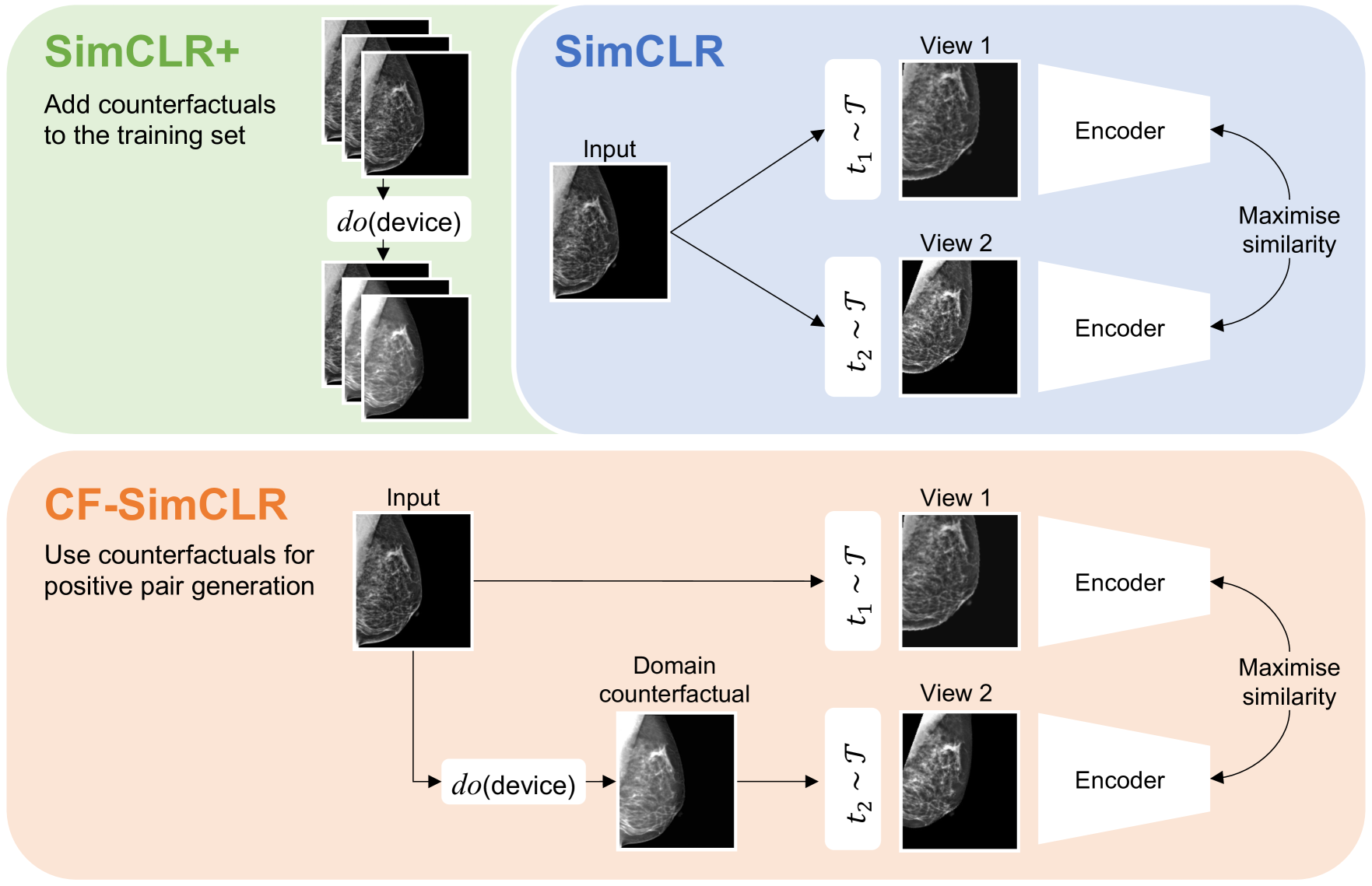
0
Counterfactual contrastive learning: robust representations via causal image synthesis
Melanie Roschewitz, Fabio De Sousa Ribeiro, Tian Xia, Galvin Khara, Ben Glocker
Contrastive pretraining is well-known to improve downstream task performance and model generalisation, especially in limited label settings. However, it is sensitive to the choice of augmentation pipeline. Positive pairs should preserve semantic information while destroying domain-specific information. Standard augmentation pipelines emulate domain-specific changes with pre-defined photometric transformations, but what if we could simulate realistic domain changes instead? In this work, we show how to utilise recent progress in counterfactual image generation to this effect. We propose CF-SimCLR, a counterfactual contrastive learning approach which leverages approximate counterfactual inference for positive pair creation. Comprehensive evaluation across five datasets, on chest radiography and mammography, demonstrates that CF-SimCLR substantially improves robustness to acquisition shift with higher downstream performance on both in- and out-of-distribution data, particularly for domains which are under-represented during training.
Read more9/18/2024