Coverage Analysis of Multi-Environment Q-Learning Algorithms for Wireless Network Optimization

0

Sign in to get full access
Overview
- This paper presents a coverage analysis of multi-environment Q-learning algorithms for wireless network optimization.
- The research was funded by several grants, including from the National Science Foundation (NSF), Army Research Office (ARO), Department of Energy (DOE), Swedish Research Council, and the USC + Amazon Center on Secure and Trusted Machine Learning.
- The goal is to analyze the performance of different reinforcement learning algorithms in optimizing wireless network parameters across diverse environments.
Plain English Explanation
The paper explores how different reinforcement learning algorithms can be used to optimize wireless network settings. Wireless networks need to be configured properly to work well, but the optimal settings can vary depending on factors like the number of users, interference, and environmental conditions.
The researchers tested several Q-learning algorithms, which are a type of reinforcement learning that learn how to make good decisions by trying different actions and seeing what works best. They ran these algorithms in computer simulations of wireless networks under a variety of conditions to see how well they could find the optimal network configurations.
The goal was to identify which Q-learning algorithms work best for optimizing wireless networks across different environments, so network operators can use the most effective techniques to set up their systems. This could help improve the performance and reliability of wireless networks in the real world.
Technical Explanation
The paper evaluates the performance of multiple Q-learning algorithms for optimizing wireless network parameters in diverse environments. The researchers designed computer simulations to test different Q-learning approaches, including:
- Standard Q-learning
- Multi-environment Q-learning, which learns across varying conditions
- Ensemble Q-learning, which combines multiple Q-learning policies
These algorithms were applied to optimize key wireless network parameters like transmit power, bandwidth allocation, and user association. The simulations modeled a variety of environmental factors that can impact network performance, such as user density, interference levels, and channel conditions.
The results show that the multi-environment and ensemble Q-learning approaches outperformed standard Q-learning in terms of finding optimal network configurations across the diverse test scenarios. The multi-environment approach was especially effective at discovering robust policies that work well in many different conditions.
The insights from this analysis can guide the development of reinforcement learning systems for automating wireless network optimization in real-world deployments. The researchers note that further work is needed to validate the findings in physical testbeds and address potential challenges like non-stationarity in dynamic wireless environments.
Critical Analysis
The paper provides a thorough evaluation of different Q-learning algorithms for wireless network optimization, which is an important problem with practical relevance. The simulation-based approach allows the researchers to systematically test the performance of these algorithms under a wide range of conditions.
One potential limitation is the reliance on simulations, which may not fully capture the complexity and dynamism of real-world wireless networks. Further validation through physical experiments or field trials would be valuable to confirm the generalizability of the findings.
Additionally, the paper does not delve into the specific mechanisms behind the superior performance of the multi-environment and ensemble Q-learning approaches. A deeper analysis of the learned policies and decision-making strategies could provide more insights into why these methods work better for wireless optimization.
It would also be interesting to see how the Q-learning algorithms compare to other reinforcement learning or optimization techniques, such as deep reinforcement learning or metaheuristic strategies. Expanding the scope of the comparison could further improve our understanding of the most effective approaches for this problem.
Conclusion
This paper presents a coverage analysis of multi-environment Q-learning algorithms for wireless network optimization. The results demonstrate that techniques like multi-environment and ensemble Q-learning can outperform standard Q-learning in finding optimal network configurations across diverse environmental conditions.
These insights have the potential to guide the development of more robust and adaptive reinforcement learning systems for automating wireless network management and optimization. Further validation and exploration of these algorithms in real-world scenarios could help unlock the full benefits of this approach for improving the performance and reliability of wireless networks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Coverage Analysis of Multi-Environment Q-Learning Algorithms for Wireless Network Optimization
Talha Bozkus, Urbashi Mitra
Q-learning is widely used to optimize wireless networks with unknown system dynamics. Recent advancements include ensemble multi-environment hybrid Q-learning algorithms, which utilize multiple Q-learning algorithms across structurally related but distinct Markovian environments and outperform existing Q-learning algorithms in terms of accuracy and complexity in large-scale wireless networks. We herein conduct a comprehensive coverage analysis to ensure optimal data coverage conditions for these algorithms. Initially, we establish upper bounds on the expectation and variance of different coverage coefficients. Leveraging these bounds, we present an algorithm for efficient initialization of these algorithms. We test our algorithm on two distinct real-world wireless networks. Numerical simulations show that our algorithm can achieve %50 less policy error and %40 less runtime complexity than state-of-the-art reinforcement learning algorithms. Furthermore, our algorithm exhibits robustness to changes in network settings and parameters. We also numerically validate our theoretical results.
Read more9/2/2024

0
A Multi-Agent Multi-Environment Mixed Q-Learning for Partially Decentralized Wireless Network Optimization
Talha Bozkus, Urbashi Mitra
Q-learning is a powerful tool for network control and policy optimization in wireless networks, but it struggles with large state spaces. Recent advancements, like multi-environment mixed Q-learning (MEMQ), improves performance and reduces complexity by integrating multiple Q-learning algorithms across multiple related environments so-called digital cousins. However, MEMQ is designed for centralized single-agent networks and is not suitable for decentralized or multi-agent networks. To address this challenge, we propose a novel multi-agent MEMQ algorithm for partially decentralized wireless networks with multiple mobile transmitters (TXs) and base stations (BSs), where TXs do not have access to each other's states and actions. In uncoordinated states, TXs act independently to minimize their individual costs. In coordinated states, TXs use a Bayesian approach to estimate the joint state based on local observations and share limited information with leader TX to minimize joint cost. The cost of information sharing scales linearly with the number of TXs and is independent of the joint state-action space size. The proposed scheme is 50% faster than centralized MEMQ with only a 20% increase in average policy error (APE) and is 25% faster than several advanced decentralized Q-learning algorithms with 40% less APE. The convergence of the algorithm is also demonstrated.
Read more9/26/2024

0
Coverage-aware and Reinforcement Learning Using Multi-agent Approach for HD Map QoS in a Realistic Environment
Jeffrey Redondo, Zhenhui Yuan, Nauman Aslam, Juan Zhang
One effective way to optimize the offloading process is by minimizing the transmission time. This is particularly true in a Vehicular Adhoc Network (VANET) where vehicles frequently download and upload High-definition (HD) map data which requires constant updates. This implies that latency and throughput requirements must be guaranteed by the wireless system. To achieve this, adjustable contention windows (CW) allocation strategies in the standard IEEE802.11p have been explored by numerous researchers. Nevertheless, their implementations demand alterations to the existing standard which is not always desirable. To address this issue, we proposed a Q-Learning algorithm that operates at the application layer. Moreover, it could be deployed in any wireless network thereby mitigating the compatibility issues. The solution has demonstrated a better network performance with relatively fewer optimization requirements as compared to the Deep Q Network (DQN) and Actor-Critic algorithms. The same is observed while evaluating the model in a multi-agent setup showing higher performance compared to the single-agent setup.
Read more8/9/2024
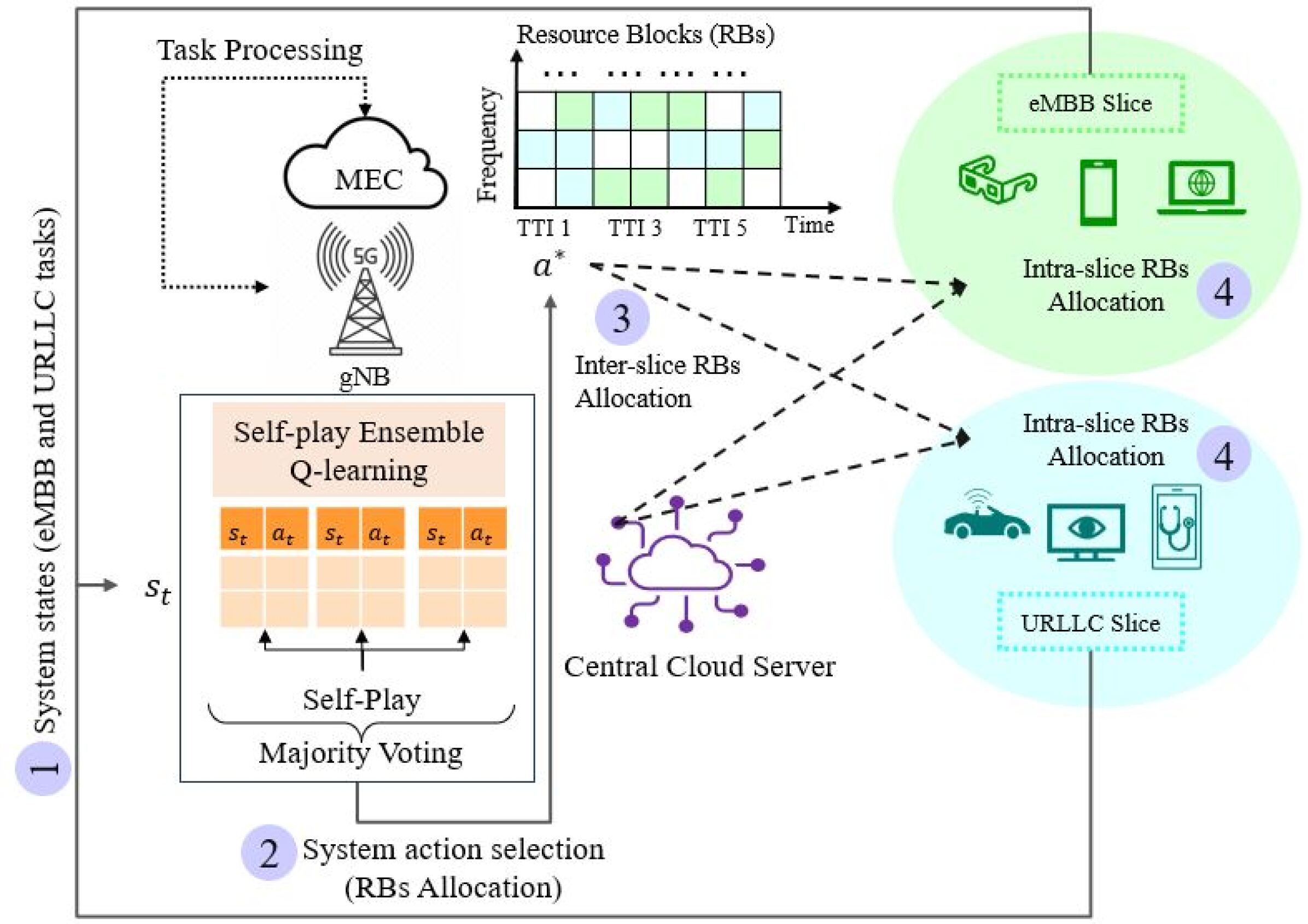
0
Self-Play Ensemble Q-learning enabled Resource Allocation for Network Slicing
Shavbo Salehi, Pedro Enrique Iturria-Rivera, Medhat Elsayed, Majid Bavand, Raimundas Gaigalas, Yigit Ozcan, Melike Erol-Kantarci
In 5G networks, network slicing has emerged as a pivotal paradigm to address diverse user demands and service requirements. To meet the requirements, reinforcement learning (RL) algorithms have been utilized widely, but this method has the problem of overestimation and exploration-exploitation trade-offs. To tackle these problems, this paper explores the application of self-play ensemble Q-learning, an extended version of the RL-based technique. Self-play ensemble Q-learning utilizes multiple Q-tables with various exploration-exploitation rates leading to different observations for choosing the most suitable action for each state. Moreover, through self-play, each model endeavors to enhance its performance compared to its previous iterations, boosting system efficiency, and decreasing the effect of overestimation. For performance evaluation, we consider three RL-based algorithms; self-play ensemble Q-learning, double Q-learning, and Q-learning, and compare their performance under different network traffic. Through simulations, we demonstrate the effectiveness of self-play ensemble Q-learning in meeting the diverse demands within 21.92% in latency, 24.22% in throughput, and 23.63% in packet drop rate in comparison with the baseline methods. Furthermore, we evaluate the robustness of self-play ensemble Q-learning and double Q-learning in situations where one of the Q-tables is affected by a malicious user. Our results depicted that the self-play ensemble Q-learning method is more robust against adversarial users and prevents a noticeable drop in system performance, mitigating the impact of users manipulating policies.
Read more8/21/2024