Self-Play Ensemble Q-learning enabled Resource Allocation for Network Slicing

0
Sign in to get full access
Overview
- Self-Play Ensemble Q-Learning for Resource Allocation in Network Slicing
- Intelligent resource allocation using a self-play ensemble approach and Q-learning
- Addresses the challenge of efficiently allocating resources in network slicing scenarios
Plain English Explanation
In modern communication networks, the concept of "network slicing" allows for the creation of multiple virtual networks, each tailored to the specific needs of different services or applications. This paper proposes a novel approach to intelligently allocate resources in these network slicing scenarios.
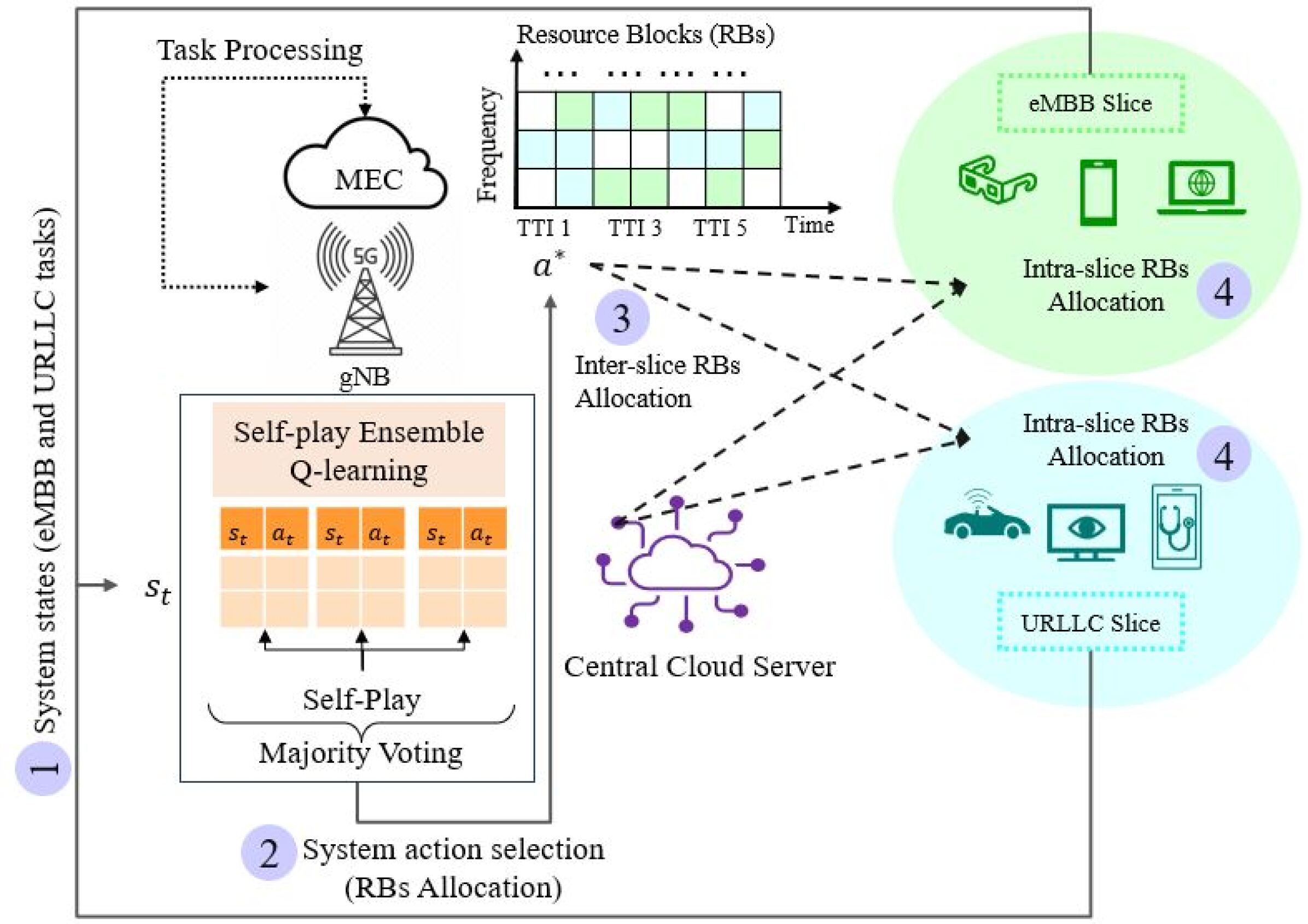
The key idea is to use a self-play ensemble of Q-learning agents to make resource allocation decisions. Q-learning is a type of reinforcement learning, where agents learn to make optimal decisions by interacting with their environment and receiving rewards or penalties. In this case, the agents are trained to learn the best way to allocate resources across the different network slices.
The self-play aspect means that the agents compete against each other during the training process, which can help them discover more effective strategies. By using an ensemble of these agents, the system can leverage the strengths of multiple approaches and make more robust decisions.
This approach aims to improve the efficiency and performance of network slicing by dynamically adjusting resource allocation based on the current demands and constraints of the different services or applications running on the network.
Technical Explanation
The paper introduces a self-play ensemble Q-learning method for intelligent resource allocation in network slicing scenarios. The system consists of multiple Q-learning agents that compete against each other in a self-play environment to learn the optimal resource allocation strategies.
The agents are trained using a modified Q-learning algorithm that incorporates the self-play aspect. During the training process, the agents compete to achieve the best performance on a given objective, such as maximizing the overall network throughput or minimizing the latency for critical services. This competition helps the agents explore a wider range of strategies and discover more effective solutions.
The authors also propose a smart sampling technique to improve the efficiency of the training process, as well as a constrained ensemble exploration method to ensure that the ensemble covers a diverse set of strategies.
The proposed approach is evaluated through simulations, comparing its performance to other resource allocation methods. The results demonstrate that the self-play ensemble Q-learning algorithm can achieve significantly better network performance in terms of throughput, latency, and other key metrics.
Critical Analysis
The paper presents a promising approach to intelligent resource allocation in network slicing scenarios. The use of self-play ensemble Q-learning is a novel and interesting technique that could potentially be applied to other resource allocation problems in communication networks and beyond.
However, the paper does not address some potential limitations of the proposed method. For example, the training process may be computationally intensive, especially as the number of network slices and agents increases. There could also be challenges in ensuring the stability and convergence of the Q-learning algorithm in a self-play environment.
Additionally, the paper does not discuss the potential impact of the resource allocation decisions on the fairness or prioritization of different services or applications running on the network. This could be an important consideration, especially in scenarios where certain services have strict quality-of-service requirements.
Further research and real-world testing would be needed to fully understand the practical implications and limitations of this approach. It would also be interesting to see how the self-play ensemble Q-learning method could be combined with other intelligent resource allocation techniques or dynamic resource scheduling algorithms to improve its performance and robustness.
Conclusion
This paper presents a novel self-play ensemble Q-learning approach for intelligent resource allocation in network slicing scenarios. The proposed method leverages the strengths of multiple Q-learning agents competing against each other to discover effective resource allocation strategies.
The results demonstrate the potential of this approach to improve the efficiency and performance of network slicing, which is a critical component of modern communication networks. While the paper highlights several promising aspects of the method, further research and real-world testing would be needed to fully understand its practical implications and limitations.
Overall, this work contributes to the ongoing efforts to develop more intelligent and adaptive resource management techniques for communication networks, which will be increasingly important as the demand for diverse and high-quality services continues to grow.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Play Ensemble Q-learning enabled Resource Allocation for Network Slicing
Shavbo Salehi, Pedro Enrique Iturria-Rivera, Medhat Elsayed, Majid Bavand, Raimundas Gaigalas, Yigit Ozcan, Melike Erol-Kantarci
In 5G networks, network slicing has emerged as a pivotal paradigm to address diverse user demands and service requirements. To meet the requirements, reinforcement learning (RL) algorithms have been utilized widely, but this method has the problem of overestimation and exploration-exploitation trade-offs. To tackle these problems, this paper explores the application of self-play ensemble Q-learning, an extended version of the RL-based technique. Self-play ensemble Q-learning utilizes multiple Q-tables with various exploration-exploitation rates leading to different observations for choosing the most suitable action for each state. Moreover, through self-play, each model endeavors to enhance its performance compared to its previous iterations, boosting system efficiency, and decreasing the effect of overestimation. For performance evaluation, we consider three RL-based algorithms; self-play ensemble Q-learning, double Q-learning, and Q-learning, and compare their performance under different network traffic. Through simulations, we demonstrate the effectiveness of self-play ensemble Q-learning in meeting the diverse demands within 21.92% in latency, 24.22% in throughput, and 23.63% in packet drop rate in comparison with the baseline methods. Furthermore, we evaluate the robustness of self-play ensemble Q-learning and double Q-learning in situations where one of the Q-tables is affected by a malicious user. Our results depicted that the self-play ensemble Q-learning method is more robust against adversarial users and prevents a noticeable drop in system performance, mitigating the impact of users manipulating policies.
Read more8/21/2024

0
A Survey on Self-play Methods in Reinforcement Learning
Ruize Zhang, Zelai Xu, Chengdong Ma, Chao Yu, Wei-Wei Tu, Shiyu Huang, Deheng Ye, Wenbo Ding, Yaodong Yang, Yu Wang
Self-play, characterized by agents' interactions with copies or past versions of itself, has recently gained prominence in reinforcement learning. This paper first clarifies the preliminaries of self-play, including the multi-agent reinforcement learning framework and basic game theory concepts. Then it provides a unified framework and classifies existing self-play algorithms within this framework. Moreover, the paper bridges the gap between the algorithms and their practical implications by illustrating the role of self-play in different scenarios. Finally, the survey highlights open challenges and future research directions in self-play. This paper is an essential guide map for understanding the multifaceted landscape of self-play in RL.
Read more8/6/2024
🔄
0
Smart Sampling: Self-Attention and Bootstrapping for Improved Ensembled Q-Learning
Muhammad Junaid Khan, Syed Hammad Ahmed, Gita Sukthankar
We present a novel method aimed at enhancing the sample efficiency of ensemble Q learning. Our proposed approach integrates multi-head self-attention into the ensembled Q networks while bootstrapping the state-action pairs ingested by the ensemble. This not only results in performance improvements over the original REDQ (Chen et al. 2021) and its variant DroQ (Hi-raoka et al. 2022), thereby enhancing Q predictions, but also effectively reduces both the average normalized bias and standard deviation of normalized bias within Q-function ensembles. Importantly, our method also performs well even in scenarios with a low update-to-data (UTD) ratio. Notably, the implementation of our proposed method is straightforward, requiring minimal modifications to the base model.
Read more5/15/2024

0
Semi-Supervised Learning Approach for Efficient Resource Allocation with Network Slicing in O-RAN
Salar Nouri, Mojdeh Karbalaee Motalleb, Vahid Shah-Mansouri, Seyed Pooya Shariatpanahi
This paper introduces an innovative approach to the resource allocation problem, aiming to coordinate multiple independent x-applications (xAPPs) for network slicing and resource allocation in the Open Radio Access Network (O-RAN). Our approach maximizes the weighted throughput among user equipment (UE) and allocates physical resource blocks (PRBs). We prioritize two service types: enhanced Mobile Broadband and Ultra-Reliable Low-Latency Communication. Two xAPPs have been designed to achieve this: a power control xAPP for each UE and a PRB allocation xAPP. The method consists of a two-part training phase. The first part uses supervised learning with a Variational Autoencoder trained to regress the power transmission, UE association, and PRB allocation decisions, and the second part uses unsupervised learning with a contrastive loss approach to improve the generalization and robustness of the model. We evaluate the performance by comparing its results to those obtained from an exhaustive search and deep Q-network algorithms and reporting performance metrics for the regression task. The results demonstrate the superior efficiency of this approach in different scenarios among the service types, reaffirming its status as a more efficient and effective solution for network slicing problems compared to state-of-the-art methods. This innovative approach not only sets our research apart but also paves the way for exciting future advancements in resource allocation in O-RAN.
Read more9/26/2024