Crafting In-context Examples according to LMs' Parametric Knowledge

0
📊
Sign in to get full access
Overview
- In-context learning can improve the performance of knowledge-rich tasks like question answering
- Language models (LMs) can surface information stored in their parameters when prompted with relevant examples
- The study examines how to construct effective in-context example sets based on the model's awareness of the examples
Plain English Explanation
Language models can draw upon the knowledge stored in their parameters to perform well on certain tasks, like answering questions. In-context learning is a technique that uses relevant examples to trigger this knowledge and improve the model's performance.
This study looks at how to construct the set of in-context examples to maximize the model's performance. The researchers identified two types of examples:
- Known examples - Examples the model can correctly answer based on its parametric knowledge
- Unknown examples - Examples the model cannot answer from its parametric knowledge
The experiments showed that using only "unknown" examples in the prompt can actually decrease performance, as it encourages the model to "hallucinate" rather than draw on its stored knowledge. The best approach was to use a mix of known and unknown examples, providing the model with both familiar information and new challenges.
The researchers also analyzed different strategies for ordering the answers within the multi-answer question sets, based on the model's knowledge of each answer. This provided additional insights into how to structure the in-context examples for optimal performance.
Overall, this study sheds light on the importance of understanding a language model's internal knowledge when crafting in-context learning prompts for knowledge-rich tasks.
Technical Explanation
The paper explores the role of in-context examples in improving the performance of knowledge-rich tasks, such as question answering. The researchers hypothesize that the effectiveness of in-context learning depends on whether the language model (LM) is aware of the examples provided.
They identify two types of in-context examples:
- Known examples - Examples the LM can correctly answer based on its parametric knowledge
- Unknown examples - Examples the LM cannot answer from its parametric knowledge
The experiments show that prompting with "unknown" examples can actually decrease performance, potentially because it encourages the LM to "hallucinate" rather than search its parametric knowledge. In contrast, using a mix of known and unknown examples performs the best across diverse settings.
The researchers also analyze three multi-answer question answering datasets to study answer set ordering strategies based on the LM's knowledge of each answer. This provides additional insights into how to construct effective in-context example sets for knowledge-rich tasks.
Critical Analysis
The paper provides valuable insights into the role of in-context examples and the importance of understanding a language model's internal knowledge. However, it does not address several potential limitations:
- The experiments are limited to question answering tasks, and the findings may not generalize to other knowledge-rich applications.
- The study does not explore the impact of the number or quality of in-context examples on performance, which could be an important factor.
- The analysis of answer set ordering strategies is specific to multi-answer question answering and may not apply to other types of knowledge-rich tasks.
Further research could investigate the generalizability of these findings, the optimal number and quality of in-context examples, and the applicability of the answer set ordering strategies to a wider range of knowledge-rich tasks.
Conclusion
This study sheds light on the importance of understanding a language model's internal knowledge when crafting in-context learning prompts for knowledge-rich tasks. The findings suggest that using a mix of known and unknown examples in the prompt can lead to the best performance, as it provides the model with both familiar information and new challenges.
The insights from this research could inform the development of more effective in-context learning techniques, which could in turn improve the performance of language models on a variety of knowledge-intensive applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Crafting In-context Examples according to LMs' Parametric Knowledge
Yoonsang Lee, Pranav Atreya, Xi Ye, Eunsol Choi
In-context learning can improve the performances of knowledge-rich tasks such as question answering. In such scenarios, in-context examples trigger a language model (LM) to surface information stored in its parametric knowledge. We study how to better construct in-context example sets, based on whether the model is aware of the in-context examples. We identify 'known' examples, where models can correctly answer from their parametric knowledge, and 'unknown' ones. Our experiments show that prompting with 'unknown' examples decreases the performance, potentially as it encourages hallucination rather than searching for its parametric knowledge. Constructing an in-context example set that presents both known and unknown information performs the best across diverse settings. We perform analysis on three multi-answer question answering datasets, which allows us to further study answer set ordering strategies based on the LM's knowledge of each answer. Together, our study sheds light on how to best construct in-context example sets for knowledge-rich tasks.
Read more4/5/2024

0
Learning vs Retrieval: The Role of In-Context Examples in Regression with LLMs
Aliakbar Nafar, Kristen Brent Venable, Parisa Kordjamshidi
Generative Large Language Models (LLMs) are capable of being in-context learners. However, the underlying mechanism of in-context learning (ICL) is still a major research question, and experimental research results about how models exploit ICL are not always consistent. In this work, we propose a framework for evaluating in-context learning mechanisms, which we claim are a combination of retrieving internal knowledge and learning from in-context examples by focusing on regression tasks. First, we show that LLMs can perform regression on real-world datasets and then design experiments to measure the extent to which the LLM retrieves its internal knowledge versus learning from in-context examples. We argue that this process lies on a spectrum between these two extremes. We provide an in-depth analysis of the degrees to which these mechanisms are triggered depending on various factors, such as prior knowledge about the tasks and the type and richness of the information provided by the in-context examples. We employ three LLMs and utilize multiple datasets to corroborate the robustness of our findings. Our results shed light on how to engineer prompts to leverage meta-learning from in-context examples and foster knowledge retrieval depending on the problem being addressed.
Read more9/9/2024
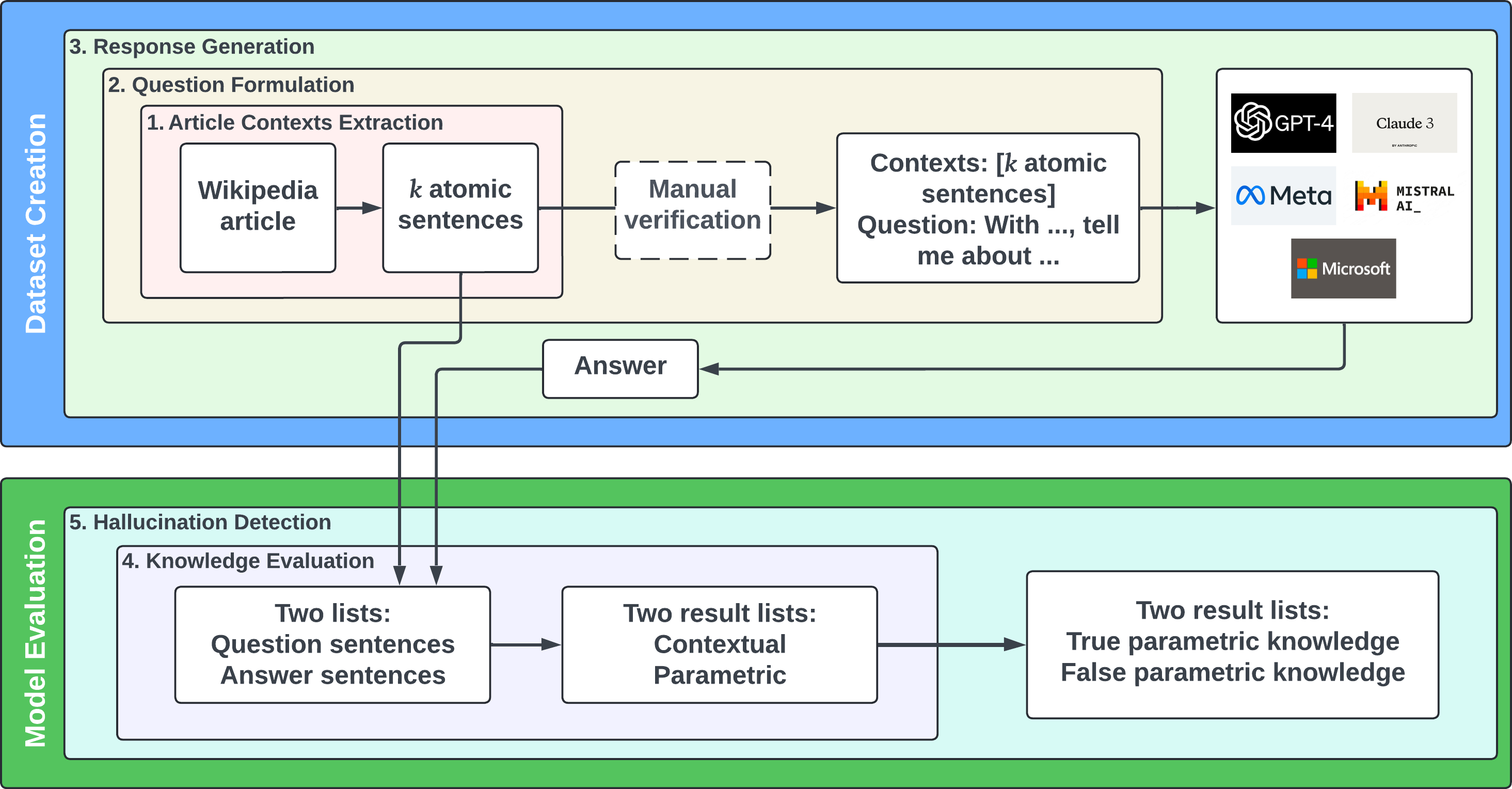
0
When Context Leads but Parametric Memory Follows in Large Language Models
Yufei Tao, Adam Hiatt, Erik Haake, Antonie J. Jetter, Ameeta Agrawal
Large language models (LLMs) have demonstrated remarkable progress in leveraging diverse knowledge sources. This study investigates how nine widely used LLMs allocate knowledge between local context and global parameters when answering open-ended questions in knowledge-consistent scenarios. We introduce a novel dataset, WikiAtomic, and systematically vary context sizes to analyze how LLMs prioritize and utilize the provided information and their parametric knowledge in knowledge-consistent scenarios. Additionally, we also study their tendency to hallucinate under varying context sizes. Our findings reveal consistent patterns across models, including a consistent reliance on both contextual (around 70%) and parametric (around 30%) knowledge, and a decrease in hallucinations with increasing context. These insights highlight the importance of more effective context organization and developing models that use input more deterministically for robust performance.
Read more9/24/2024

0
Large Language Models Know What Makes Exemplary Contexts
Quanyu Long, Jianda Chen, Wenya Wang, Sinno Jialin Pan
In-context learning (ICL) has proven to be a significant capability with the advancement of Large Language models (LLMs). By instructing LLMs using few-shot demonstrative examples, ICL enables them to perform a wide range of tasks without needing to update millions of parameters. This paper presents a unified framework for LLMs that allows them to self-select influential in-context examples to compose their contexts; self-rank candidates with different demonstration compositions; self-optimize the demonstration selection and ordering through reinforcement learning. Specifically, our method designs a parameter-efficient retrieval head that generates the optimized demonstration after training with rewards from LLM's own preference. Experimental results validate the proposed method's effectiveness in enhancing ICL performance. Additionally, our approach effectively identifies and selects the most representative examples for the current task, and includes more diversity in retrieval.
Read more8/21/2024