When Context Leads but Parametric Memory Follows in Large Language Models

0
Sign in to get full access
Overview
- This paper investigates how large language models (LLMs) utilize context versus parametric memory when solving tasks.
- The authors find that context often leads while parametric memory follows, meaning LLMs rely more on the immediate context than their learned knowledge when making predictions.
- This has implications for how LLMs can be improved to better leverage their parametric memory and knowledge.
Plain English Explanation
The paper explores how large language models (LLMs) - powerful AI systems trained on vast amounts of text data - use different types of information when solving tasks. Specifically, it looks at how they balance using the immediate context they are given versus the knowledge they have stored in their internal parameters.
The researchers discovered that LLMs tend to prioritize the context over their own learned knowledge when making predictions. In other words, the current information provided to the model often has a stronger influence on its output than the information it has accumulated through training.
This finding is significant because it suggests that LLMs may not be fully taking advantage of their parametric memory - the knowledge encoded in their model parameters. By relying more heavily on context than their own knowledge, LLMs may be missing opportunities to draw on relevant information and apply it to the task at hand.
Understanding this dynamic between context and parametric memory is an important step in figuring out how to improve LLMs and help them better leverage their substantial knowledge bases. With further research and development, these models could become even more capable and effective at solving complex problems.
Technical Explanation
The paper investigates how large language models (LLMs) utilize context versus parametric memory when solving tasks. The authors introduce a framework to quantify the relative influence of these two information sources and apply it to several LLMs on a range of tasks.
Their experiments show that context often leads while parametric memory follows, meaning the immediate context provided to the model has a stronger effect on its predictions than the knowledge encoded in its parameters. This is true even when the parametric memory contains relevant information that could be useful for the task.
The authors hypothesize that this reliance on context over parametric memory may be due to the way LLMs are trained, which optimizes them to generate fluent text rather than leverage their full knowledge base. They discuss potential ways to address this and improve LLMs' ability to effectively utilize their parametric memory.
Critical Analysis
The paper provides valuable insights into the inner workings of large language models and how they balance different information sources. The authors' framework for quantifying context versus parametric memory is a useful tool for analyzing model behaviors.
However, the findings also raise some potential concerns. If LLMs are indeed over-relying on context at the expense of their parametric knowledge, this could lead to issues such as poor generalization, inconsistent behavior, and an inability to apply relevant knowledge to new situations.
Additionally, the paper does not delve into the potential biases or limitations that may be encoded in the parametric memory of these models, which could also impact their performance and reliability.
Further research is needed to better understand the complex interplay between context and parametric memory in large language models, as well as how to optimize their utilization of both information sources.
Conclusion
This paper offers valuable insights into the inner workings of large language models and how they leverage different types of information. By demonstrating that context often takes precedence over parametric memory, the authors highlight an important area for improvement in these powerful AI systems.
Addressing this tendency to prioritize context over knowledge could lead to LLMs that are better able to draw upon their substantial knowledge bases, resulting in more consistent, reliable, and generalizable performance. As the field of large language models continues to evolve, understanding and optimizing the balance between context and parametric memory will be a key focus for researchers and developers alike.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
When Context Leads but Parametric Memory Follows in Large Language Models
Yufei Tao, Adam Hiatt, Erik Haake, Antonie J. Jetter, Ameeta Agrawal
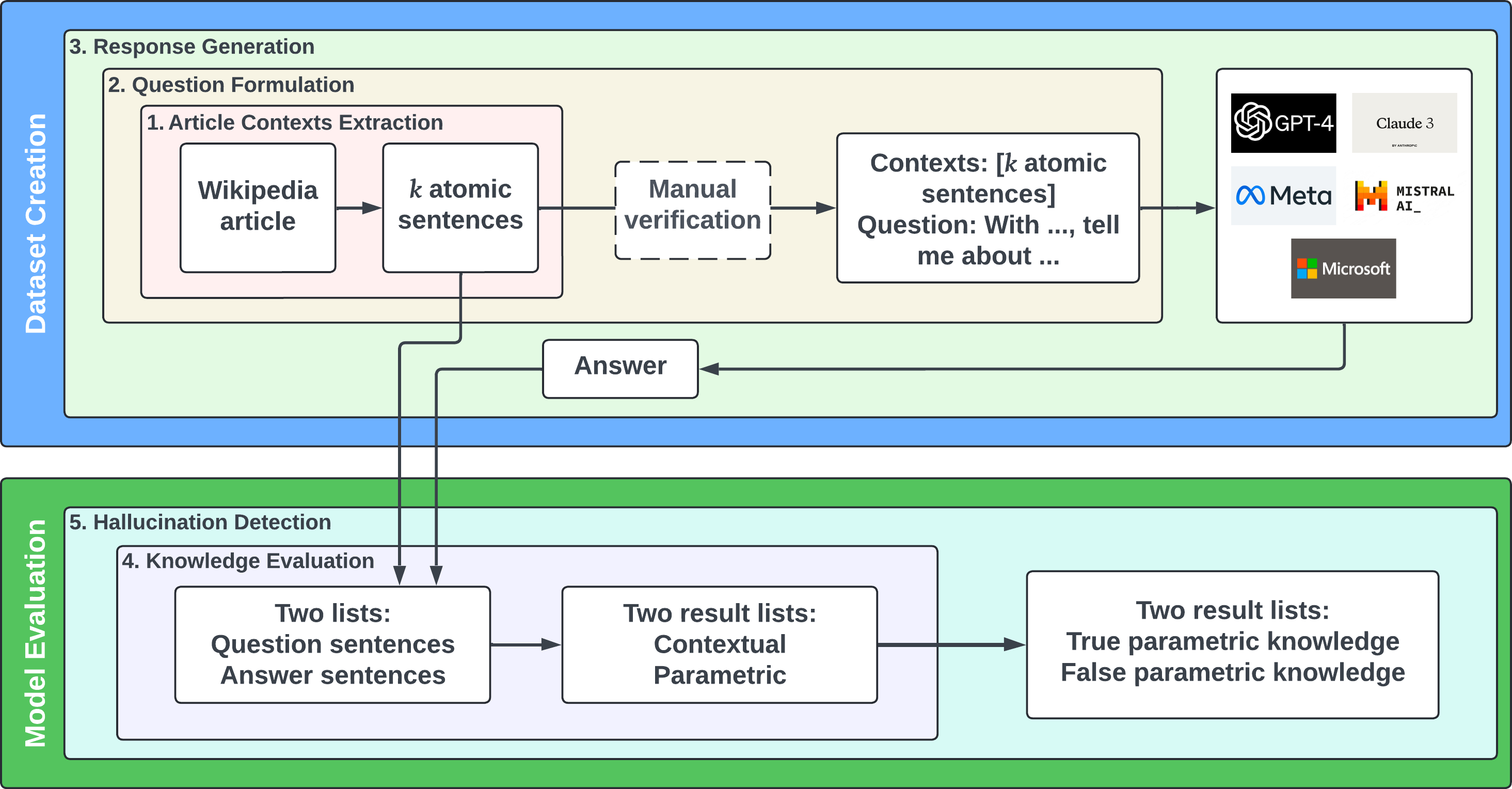
Large language models (LLMs) have demonstrated remarkable progress in leveraging diverse knowledge sources. This study investigates how nine widely used LLMs allocate knowledge between local context and global parameters when answering open-ended questions in knowledge-consistent scenarios. We introduce a novel dataset, WikiAtomic, and systematically vary context sizes to analyze how LLMs prioritize and utilize the provided information and their parametric knowledge in knowledge-consistent scenarios. Additionally, we also study their tendency to hallucinate under varying context sizes. Our findings reveal consistent patterns across models, including a consistent reliance on both contextual (around 70%) and parametric (around 30%) knowledge, and a decrease in hallucinations with increasing context. These insights highlight the importance of more effective context organization and developing models that use input more deterministically for robust performance.
Read more9/24/2024

0
Evaluating the External and Parametric Knowledge Fusion of Large Language Models
Hao Zhang, Yuyang Zhang, Xiaoguang Li, Wenxuan Shi, Haonan Xu, Huanshuo Liu, Yasheng Wang, Lifeng Shang, Qun Liu, Yong Liu, Ruiming Tang
Integrating external knowledge into large language models (LLMs) presents a promising solution to overcome the limitations imposed by their antiquated and static parametric memory. Prior studies, however, have tended to over-reliance on external knowledge, underestimating the valuable contributions of an LLMs' intrinsic parametric knowledge. The efficacy of LLMs in blending external and parametric knowledge remains largely unexplored, especially in cases where external knowledge is incomplete and necessitates supplementation by their parametric knowledge. We propose to deconstruct knowledge fusion into four distinct scenarios, offering the first thorough investigation of LLM behavior across each. We develop a systematic pipeline for data construction and knowledge infusion to simulate these fusion scenarios, facilitating a series of controlled experiments. Our investigation reveals that enhancing parametric knowledge within LLMs can significantly bolster their capability for knowledge integration. Nonetheless, we identify persistent challenges in memorizing and eliciting parametric knowledge, and determining parametric knowledge boundaries. Our findings aim to steer future explorations on harmonizing external and parametric knowledge within LLMs.
Read more5/30/2024

0
Knowledge Conflicts for LLMs: A Survey
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, Wei Xu
This survey provides an in-depth analysis of knowledge conflicts for large language models (LLMs), highlighting the complex challenges they encounter when blending contextual and parametric knowledge. Our focus is on three categories of knowledge conflicts: context-memory, inter-context, and intra-memory conflict. These conflicts can significantly impact the trustworthiness and performance of LLMs, especially in real-world applications where noise and misinformation are common. By categorizing these conflicts, exploring the causes, examining the behaviors of LLMs under such conflicts, and reviewing available solutions, this survey aims to shed light on strategies for improving the robustness of LLMs, thereby serving as a valuable resource for advancing research in this evolving area.
Read more6/26/2024

0
LLMs' Reading Comprehension Is Affected by Parametric Knowledge and Struggles with Hypothetical Statements
Victoria Basmov, Yoav Goldberg, Reut Tsarfaty
The task of reading comprehension (RC), often implemented as context-based question answering (QA), provides a primary means to assess language models' natural language understanding (NLU) capabilities. Yet, when applied to large language models (LLMs) with extensive built-in world knowledge, this method can be deceptive. If the context aligns with the LLMs' internal knowledge, it is hard to discern whether the models' answers stem from context comprehension or from LLMs' internal information. Conversely, using data that conflicts with the models' knowledge creates erroneous trends which distort the results. To address this issue, we suggest to use RC on imaginary data, based on fictitious facts and entities. This task is entirely independent of the models' world knowledge, enabling us to evaluate LLMs' linguistic abilities without the interference of parametric knowledge. Testing ChatGPT, GPT-4, LLaMA 2 and Mixtral on such imaginary data, we uncover a class of linguistic phenomena posing a challenge to current LLMs, involving thinking in terms of alternative, hypothetical scenarios. While all the models handle simple affirmative and negative contexts with high accuracy, they are much more prone to error when dealing with modal and conditional contexts. Crucially, these phenomena also trigger the LLMs' vulnerability to knowledge-conflicts again. In particular, while some models prove virtually unaffected by knowledge conflicts in affirmative and negative contexts, when faced with more semantically involved modal and conditional environments, they often fail to separate the text from their internal knowledge.
Read more4/10/2024