Creative Text-to-Audio Generation via Synthesizer Programming

0

Sign in to get full access
Overview
- This paper presents a novel approach to generating creative text-to-audio content using a technique called "synthesizer programming."
- The method involves training a model to translate written text into low-level control parameters for a virtual audio synthesizer, allowing for the generation of unique and expressive audio from text inputs.
- The authors explore the potential of this approach for applications in music, sound design, and other creative audio domains.
Plain English Explanation
The paper describes a way to automatically generate audio content from written text. Rather than simply converting text to speech, the proposed method uses a neural network to translate text into the specific settings and parameters needed to control a virtual audio synthesizer. This allows the system to create unique and expressive audio that goes beyond simple speech, incorporating musical elements, sound effects, and other creative sonic qualities.
The key idea is to treat the process of audio synthesis as a form of "programming" that can be learned by a machine learning model. By training the model on examples of text paired with the corresponding synthesizer settings, it can learn to generate the low-level control signals needed to produce novel audio content from new text inputs. [This approach is similar to techniques like <a href="https://aimodels.fyi/papers/arxiv/leveraging-ai-to-generate-audio-user-generated" title="Leveraging AI to Generate Audio from User-Generated Text">leveraging AI to generate audio from user-generated text</a> and <a href="https://aimodels.fyi/papers/arxiv/fast-timing-conditioned-latent-audio-diffusion" title="Fast Timing-Conditioned Latent Audio Diffusion">fast timing-conditioned latent audio diffusion</a>, which also explore ways to generate audio content from text.]
The authors suggest this could enable a wide range of creative applications, from generative music composition to automated sound design for films, games, and other media. By bridging the gap between language and audio synthesis, the technique allows users to express their ideas in text and have them instantly transformed into rich, customized audio experiences.
Technical Explanation
The core of the proposed system is a neural network-based "synthesizer programming" model that takes text as input and generates the low-level control parameters needed to drive a virtual audio synthesizer. The model is trained on a dataset of text paired with the corresponding synthesizer settings used to produce the associated audio.
The authors experiment with different model architectures, including transformer-based language models and autoregressive decoders, to find the most effective approach for translating text to synthesizer parameters. They also investigate techniques for conditioning the model on additional factors like desired musical key, tempo, and instrument type to provide more control over the generated audio.
Through a series of experiments, the researchers demonstrate the model's ability to generate diverse and creative audio content from text prompts, spanning genres like ambient music, sound effects, and synthetic speech. They also show that the generated audio exhibits desirable properties like coherence, expressivity, and diversity compared to baseline text-to-speech approaches.
The authors acknowledge several limitations of the current system, such as the challenge of ensuring the generated audio aligns with the semantic meaning of the input text and the need for further research to improve the quality and consistency of the output. They also discuss potential future directions, including the integration of the text-to-audio generation model with interactive user interfaces and the exploration of more advanced synthesis techniques like <a href="https://aimodels.fyi/papers/arxiv/accented-text-to-speech-synthesis-conditional-variational" title="Accented Text-to-Speech Synthesis via Conditional Variational Autoencoder">accented text-to-speech synthesis</a> and <a href="https://aimodels.fyi/papers/arxiv/synthesizing-audio-from-silent-video-using-sequence" title="Synthesizing Audio from Silent Video Using Sequence-to-Sequence Visual-Audio Models">audio synthesis from silent video</a>.
Critical Analysis
The paper presents a compelling and innovative approach to creative text-to-audio generation, with the potential to significantly expand the capabilities of existing text-to-speech systems. By leveraging the flexibility and expressive power of audio synthesis, the proposed method opens up new possibilities for generating unique, customized audio content from text inputs.
One key strength of the approach is its ability to capture the nuanced relationship between language and audio, going beyond simplistic text-to-speech conversion. The model's capacity to translate text into the specific control parameters of a virtual synthesizer allows for the generation of audio that is not just intelligible, but also musically and sonically engaging.
However, the authors acknowledge several important limitations and challenges that will need to be addressed in future work. Ensuring the semantic coherence between the input text and the generated audio is a significant hurdle, as is improving the overall quality and consistency of the output. Additionally, the integration of the text-to-audio generation model with intuitive user interfaces and the exploration of more advanced synthesis techniques will be crucial for unlocking the full potential of this approach.
Overall, the research presented in this paper represents an exciting step forward in the field of creative text-to-audio generation. By bridging the gap between language and audio synthesis, it opens up new avenues for artistic expression and the development of novel audio-based applications. As the authors continue to refine and expand upon their work, it will be interesting to see how this approach evolves and how it might be leveraged to <a href="https://aimodels.fyi/papers/arxiv/visual-echoes-simple-unified-transformer-audio-visual" title="Visual Echoes: A Simple Unified Transformer for Audio-Visual Tasks">integrate audio and visual modalities</a> in creative and meaningful ways.
Conclusion
This paper presents a novel approach to creative text-to-audio generation using a technique called "synthesizer programming." The key idea is to train a neural network model to translate written text into the low-level control parameters needed to drive a virtual audio synthesizer, allowing for the generation of unique and expressive audio content from text inputs.
The authors demonstrate the potential of this approach through a series of experiments, showcasing the model's ability to generate diverse audio across various genres and applications. While the current system faces some limitations, such as ensuring semantic coherence between text and audio, the research represents an exciting step forward in bridging the gap between language and audio synthesis.
As the authors continue to refine and expand upon their work, the implications of this approach could be far-reaching, enabling new creative applications in music, sound design, and beyond. By empowering users to express their ideas in text and instantly transform them into rich, customized audio experiences, the "synthesizer programming" technique holds promise for unlocking new frontiers in the world of generative audio.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Creative Text-to-Audio Generation via Synthesizer Programming
Manuel Cherep, Nikhil Singh, Jessica Shand
Neural audio synthesis methods now allow specifying ideas in natural language. However, these methods produce results that cannot be easily tweaked, as they are based on large latent spaces and up to billions of uninterpretable parameters. We propose a text-to-audio generation method that leverages a virtual modular sound synthesizer with only 78 parameters. Synthesizers have long been used by skilled sound designers for media like music and film due to their flexibility and intuitive controls. Our method, CTAG, iteratively updates a synthesizer's parameters to produce high-quality audio renderings of text prompts that can be easily inspected and tweaked. Sounds produced this way are also more abstract, capturing essential conceptual features over fine-grained acoustic details, akin to how simple sketches can vividly convey visual concepts. Our results show how CTAG produces sounds that are distinctive, perceived as artistic, and yet similarly identifiable to recent neural audio synthesis models, positioning it as a valuable and complementary tool.
Read more6/4/2024
0
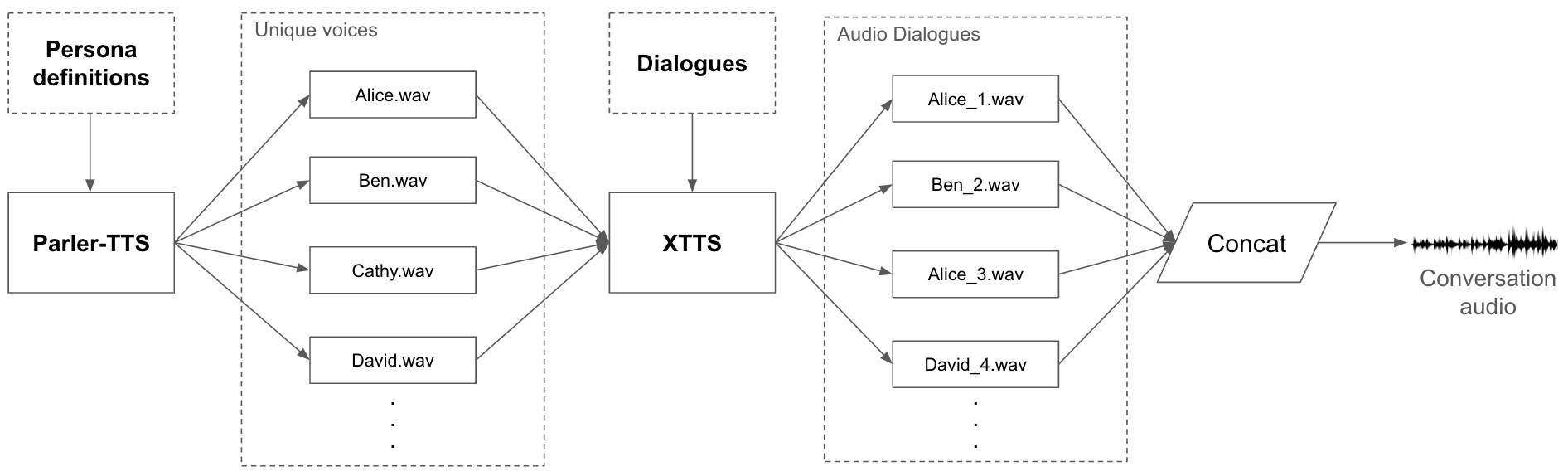
A Framework for Synthetic Audio Conversations Generation using Large Language Models
Kaung Myat Kyaw, Jonathan Hoyin Chan
In this paper, we introduce ConversaSynth, a framework designed to generate synthetic conversation audio using large language models (LLMs) with multiple persona settings. The framework first creates diverse and coherent text-based dialogues across various topics, which are then converted into audio using text-to-speech (TTS) systems. Our experiments demonstrate that ConversaSynth effectively generates highquality synthetic audio datasets, which can significantly enhance the training and evaluation of models for audio tagging, audio classification, and multi-speaker speech recognition. The results indicate that the synthetic datasets generated by ConversaSynth exhibit substantial diversity and realism, making them suitable for developing robust, adaptable audio-based AI systems.
Read more9/4/2024
🤯
0
Improving Text-To-Audio Models with Synthetic Captions
Zhifeng Kong, Sang-gil Lee, Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Rafael Valle, Soujanya Poria, Bryan Catanzaro
It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new textit{state-of-the-art}.
Read more7/10/2024

0
Leveraging AI to Generate Audio for User-generated Content in Video Games
Thomas Marrinan, Pakeeza Akram, Oli Gurmessa, Anthony Shishkin
In video game design, audio (both environmental background music and object sound effects) play a critical role. Sounds are typically pre-created assets designed for specific locations or objects in a game. However, user-generated content is becoming increasingly popular in modern games (e.g. building custom environments or crafting unique objects). Since the possibilities are virtually limitless, it is impossible for game creators to pre-create audio for user-generated content. We explore the use of generative artificial intelligence to create music and sound effects on-the-fly based on user-generated content. We investigate two avenues for audio generation: 1) text-to-audio: using a text description of user-generated content as input to the audio generator, and 2) image-to-audio: using a rendering of the created environment or object as input to an image-to-text generator, then piping the resulting text description into the audio generator. In this paper we discuss ethical implications of using generative artificial intelligence for user-generated content and highlight two prototype games where audio is generated for user-created environments and objects.
Read more4/29/2024