A Framework for Synthetic Audio Conversations Generation using Large Language Models

0
Sign in to get full access
Overview
- This paper proposes a framework for generating synthetic audio conversations using large language models (LLMs).
- The goal is to create realistic multi-speaker audio conversations from text inputs, which could have applications in areas like virtual assistants, video game characters, and educational tools.
- The framework combines LLMs for text generation with text-to-speech (TTS) models to produce the final audio output.
Plain English Explanation
The researchers have developed a system that can take written text and turn it into a realistic-sounding conversation between multiple people. This is done by first using a large language model to generate the actual dialogue, and then passing that text to a text-to-speech model that can convert it into audio.
The idea is that this could be very useful for things like virtual assistants that need to have natural-sounding conversations, or for creating characters in video games or educational software that can speak. Instead of having to record all the dialogue manually, the system can automatically generate it.
Of course, getting the audio to sound truly natural and human-like is a significant challenge. The researchers describe ways they tried to improve the text-to-speech models and make the overall system more robust. But there's still a lot of room for improvement before this kind of synthetic audio can be indistinguishable from real human voices.
Technical Explanation
The core of the proposed framework is the combination of a large language model (LLM) for text generation and a text-to-speech (TTS) model for audio synthesis.
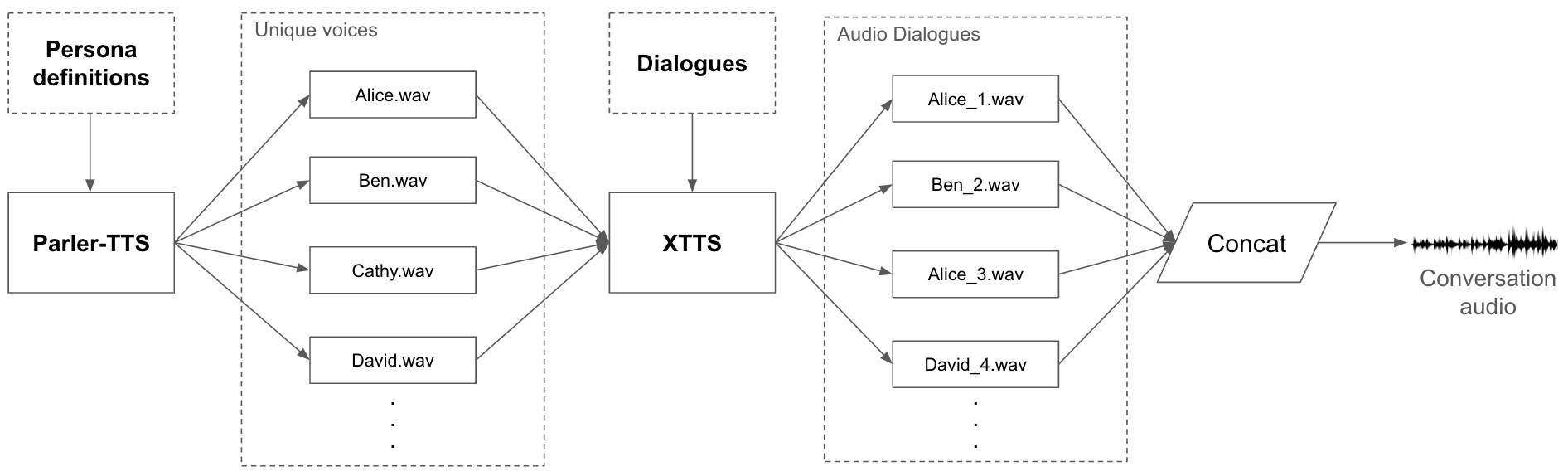
The LLM is used to generate the actual dialogue, with the researchers experimenting with different prompting techniques to improve the quality and coherence of the generated text. This includes using persona-based prompting to give each speaker a distinct voice and personality.
The TTS model then takes the generated text and converts it into audio, with the researchers exploring ways to make the synthetic voices more natural and expressive. This includes incorporating techniques like prosody modeling and voice cloning.
The researchers evaluate their framework through both objective metrics (e.g. speech quality, intelligibility) and subjective human evaluations. The results show that the synthetic audio conversations are generally rated as sounding natural and coherent, though there is still room for improvement, especially when it comes to conveying emotion and personality.
Critical Analysis
One key limitation of the current framework is that it relies on pre-trained TTS models, which can introduce biases and lack the flexibility to truly capture the nuance of each speaker's voice. The researchers acknowledge this and suggest that further work is needed to develop more customizable TTS capabilities.
Additionally, the experiments were conducted on a relatively small dataset of conversation transcripts, which may not be representative of the full diversity of real-world conversations. Scaling the framework to handle larger, more complex dialogues could present additional challenges.
Another potential concern is the ethical implications of being able to generate highly realistic synthetic voices. While the researchers focus on positive use cases, there is always the risk of this technology being misused for deception or other malicious purposes. Careful consideration of these issues will be important as the field progresses.
Conclusion
Overall, this paper presents a promising framework for leveraging large language models and text-to-speech technology to generate synthetic audio conversations. While the current results are encouraging, there is still significant work to be done to improve the naturalness and expressiveness of the generated audio.
If these challenges can be overcome, this technology could enable a wide range of applications, from more engaging virtual assistants to interactive educational experiences. However, the ethical implications will need to be thoroughly explored to ensure this powerful capability is used responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Framework for Synthetic Audio Conversations Generation using Large Language Models
Kaung Myat Kyaw, Jonathan Hoyin Chan
In this paper, we introduce ConversaSynth, a framework designed to generate synthetic conversation audio using large language models (LLMs) with multiple persona settings. The framework first creates diverse and coherent text-based dialogues across various topics, which are then converted into audio using text-to-speech (TTS) systems. Our experiments demonstrate that ConversaSynth effectively generates highquality synthetic audio datasets, which can significantly enhance the training and evaluation of models for audio tagging, audio classification, and multi-speaker speech recognition. The results indicate that the synthetic datasets generated by ConversaSynth exhibit substantial diversity and realism, making them suitable for developing robust, adaptable audio-based AI systems.
Read more9/4/2024
0
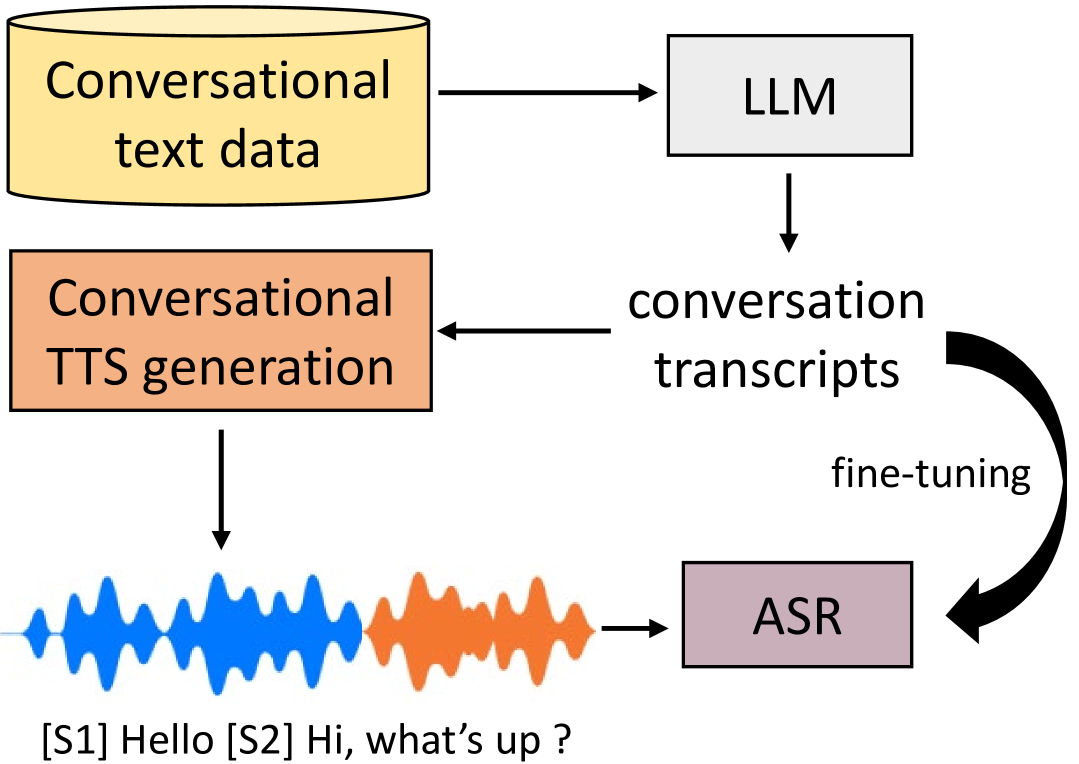
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024

0
Can Synthetic Audio From Generative Foundation Models Assist Audio Recognition and Speech Modeling?
Tiantian Feng, Dimitrios Dimitriadis, Shrikanth Narayanan
Recent advances in foundation models have enabled audio-generative models that produce high-fidelity sounds associated with music, events, and human actions. Despite the success achieved in modern audio-generative models, the conventional approach to assessing the quality of the audio generation relies heavily on distance metrics like Frechet Audio Distance. In contrast, we aim to evaluate the quality of audio generation by examining the effectiveness of using them as training data. Specifically, we conduct studies to explore the use of synthetic audio for audio recognition. Moreover, we investigate whether synthetic audio can serve as a resource for data augmentation in speech-related modeling. Our comprehensive experiments demonstrate the potential of using synthetic audio for audio recognition and speech-related modeling. Our code is available at https://github.com/usc-sail/SynthAudio.
Read more8/30/2024
🤯
0
Improving Text-To-Audio Models with Synthetic Captions
Zhifeng Kong, Sang-gil Lee, Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Rafael Valle, Soujanya Poria, Bryan Catanzaro
It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new textit{state-of-the-art}.
Read more7/10/2024