Critic-CoT: Boosting the reasoning abilities of large language model via Chain-of-thoughts Critic

0
Sign in to get full access
Overview
- The paper introduces a novel approach called "Critic-CoT" that aims to improve the reasoning abilities of large language models.
- This method uses a "chain-of-thoughts" (CoT) critic to provide feedback and guidance to the language model during the reasoning process.
- The goal is to boost the model's ability to generate more coherent and logically sound responses, especially for complex reasoning tasks.
Plain English Explanation
The paper presents a technique called "Critic-CoT" that can help make large language models (LLMs) better at logical reasoning and problem-solving. LLMs are powerful AI systems that can understand and generate human-like text.
The key idea behind Critic-CoT is to add a "critic" to the language model. This critic analyzes the model's step-by-step reasoning process (the "chain-of-thoughts") and provides feedback to help the model improve its logic and reasoning. This is similar to how a human tutor might guide a student through a complex problem-solving task.
By incorporating this critic feedback, the language model can learn to generate more coherent and well-reasoned responses, especially for challenging tasks that require deeper logical thinking. This could make LLMs more reliable and effective for applications that demand strong reasoning abilities, such as answering complex questions or solving multi-step problems.
Technical Explanation
The paper introduces the Critic-CoT approach, which aims to enhance the reasoning capabilities of large language models. The key components of this method are:
-
Chain-of-Thoughts (CoT): The language model is prompted to generate a step-by-step reasoning process, known as a "chain-of-thoughts," for a given task or question.
-
Critic Model: A separate neural network model is trained to evaluate the quality and coherence of the language model's chain-of-thoughts. This critic provides feedback to the language model to help it improve its reasoning abilities.
-
Iterative Feedback Loop: The language model and critic model are trained in an iterative feedback loop. The language model generates a chain-of-thoughts, the critic evaluates it, and the language model uses this feedback to refine its reasoning process.
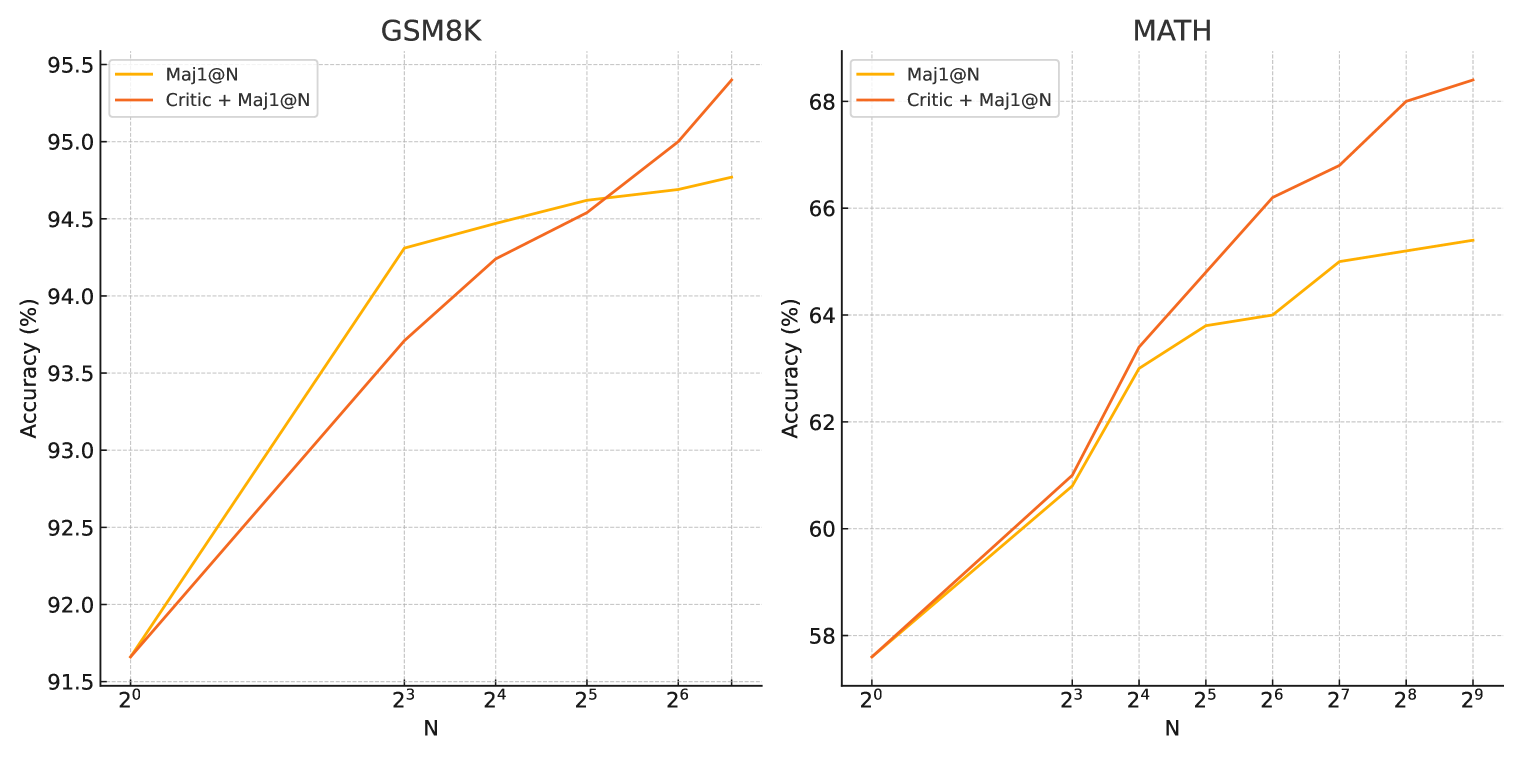
The authors evaluate the Critic-CoT approach on a range of reasoning-focused benchmarks, including multi-step math word problems and multi-task reasoning tasks. The results show that the Critic-CoT model outperforms standard language models on these tasks, demonstrating the potential of this approach to boost the reasoning capabilities of large language models.
Critical Analysis
The Critic-CoT approach represents an interesting and promising direction for improving the reasoning abilities of large language models. By incorporating a dedicated critic model to provide feedback on the language model's reasoning process, the authors demonstrate that the model can learn to generate more logically sound and coherent responses.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the Critic-CoT approach. For example, it is unclear how the method would scale to more complex or open-ended reasoning tasks, or how sensitive the performance is to the quality and training of the critic model.
Additionally, the paper does not address potential ethical concerns around the use of such reasoning-enhanced language models, such as the potential for misuse or the need for robust safety and transparency measures.
Further research and analysis would be helpful to better understand the broader implications and limitations of the Critic-CoT approach, as well as how it compares to other techniques for improving the reasoning abilities of large language models.
Conclusion
The Critic-CoT paper introduces an innovative approach to enhance the reasoning capabilities of large language models. By incorporating a dedicated critic model to provide feedback on the language model's step-by-step reasoning process, the authors demonstrate a way to boost the model's ability to generate more coherent and logically sound responses, particularly for complex reasoning tasks.
This work represents an important step towards developing more reliable and effective language models that can be applied to a wider range of applications requiring strong logical reasoning skills. As the capabilities of large language models continue to grow, techniques like Critic-CoT will likely play an increasingly important role in ensuring these systems can be safely and effectively deployed.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Critic-CoT: Boosting the reasoning abilities of large language model via Chain-of-thoughts Critic
Xin Zheng, Jie Lou, Boxi Cao, Xueru Wen, Yuqiu Ji, Hongyu Lin, Yaojie Lu, Xianpei Han, Debing Zhang, Le Sun
Self-critic has become an important mechanism for enhancing the reasoning performance of LLMs. However, current approaches mainly involve basic prompts without further training, which tend to be over-simplified, leading to limited accuracy.Moreover, there is a lack of in-depth investigation of the relationship between LLM's ability to criticism and its task-solving performance.To address these issues, we propose Critic-CoT, a novel framework that pushes LLMs toward System-2-like critic capability, via step-wise CoT reasoning format and distant-supervision data construction, without the need for human annotation. Experiments on GSM8K and MATH show that via filtering out invalid solutions or iterative refinement, our enhanced model boosts task-solving performance, which demonstrates the effectiveness of our method. Further, we find that training on critique and refinement alone improves the generation. We hope our work could shed light on future research on improving the reasoning and critic ability of LLMs.
Read more8/30/2024
🌿
65
Chain-of-Thought Reasoning Without Prompting
Xuezhi Wang, Denny Zhou
In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) prompting. These methods, while effective, often involve manually intensive prompt engineering. Our study takes a novel approach by asking: Can LLMs reason effectively without prompting? Our findings reveal that, intriguingly, CoT reasoning paths can be elicited from pre-trained LLMs by simply altering the textit{decoding} process. Rather than conventional greedy decoding, we investigate the top-$k$ alternative tokens, uncovering that CoT paths are frequently inherent in these sequences. This approach not only bypasses the confounders of prompting but also allows us to assess the LLMs' textit{intrinsic} reasoning abilities. Moreover, we observe that the presence of a CoT in the decoding path correlates with a higher confidence in the model's decoded answer. This confidence metric effectively differentiates between CoT and non-CoT paths. Extensive empirical studies on various reasoning benchmarks show that the proposed CoT-decoding effectively elicits reasoning capabilities from language models, which were previously obscured by standard greedy decoding.
Read more5/27/2024

0
CriticBench: Benchmarking LLMs for Critique-Correct Reasoning
Zicheng Lin, Zhibin Gou, Tian Liang, Ruilin Luo, Haowei Liu, Yujiu Yang
The ability of Large Language Models (LLMs) to critique and refine their reasoning is crucial for their application in evaluation, feedback provision, and self-improvement. This paper introduces CriticBench, a comprehensive benchmark designed to assess LLMs' abilities to critique and rectify their reasoning across a variety of tasks. CriticBench encompasses five reasoning domains: mathematical, commonsense, symbolic, coding, and algorithmic. It compiles 15 datasets and incorporates responses from three LLM families. Utilizing CriticBench, we evaluate and dissect the performance of 17 LLMs in generation, critique, and correction reasoning, i.e., GQC reasoning. Our findings reveal: (1) a linear relationship in GQC capabilities, with critique-focused training markedly enhancing performance; (2) a task-dependent variation in correction effectiveness, with logic-oriented tasks being more amenable to correction; (3) GQC knowledge inconsistencies that decrease as model size increases; and (4) an intriguing inter-model critiquing dynamic, where stronger models are better at critiquing weaker ones, while weaker models can surprisingly surpass stronger ones in their self-critique. We hope these insights into the nuanced critique-correct reasoning of LLMs will foster further research in LLM critique and self-improvement.
Read more6/4/2024

0
CoT Rerailer: Enhancing the Reliability of Large Language Models in Complex Reasoning Tasks through Error Detection and Correction
Guangya Wan, Yuqi Wu, Jie Chen, Sheng Li
Chain-of-Thought (CoT) prompting enhances Large Language Models (LLMs) complex reasoning abilities by generating intermediate steps. However, these steps can introduce hallucinations and accumulate errors. We propose the CoT Rerailer to address these challenges, employing self-consistency and multi-agent debate systems to identify and rectify errors in the reasoning process. The CoT Rerailer first selects the most logically correct Reasoning Path (RP) using consistency checks and critical evaluation by automated agents. It then engages a multi-agent debate system to propose and validate corrections to ensure the generation of an error-free intermediate logical path. The corrected steps are then used to generate a revised reasoning chain to further reduce hallucinations and enhance answer quality. We demonstrate the effectiveness of our approach across diverse question-answering datasets in various knowledge domains. The CoT Rerailer enhances the reliability of LLM-generated reasoning, contributing to more trustworthy AI driven decision-making processes.
Read more8/27/2024