CriticBench: Benchmarking LLMs for Critique-Correct Reasoning
2402.14809
0
0

Abstract
The ability of Large Language Models (LLMs) to critique and refine their reasoning is crucial for their application in evaluation, feedback provision, and self-improvement. This paper introduces CriticBench, a comprehensive benchmark designed to assess LLMs' abilities to critique and rectify their reasoning across a variety of tasks. CriticBench encompasses five reasoning domains: mathematical, commonsense, symbolic, coding, and algorithmic. It compiles 15 datasets and incorporates responses from three LLM families. Utilizing CriticBench, we evaluate and dissect the performance of 17 LLMs in generation, critique, and correction reasoning, i.e., GQC reasoning. Our findings reveal: (1) a linear relationship in GQC capabilities, with critique-focused training markedly enhancing performance; (2) a task-dependent variation in correction effectiveness, with logic-oriented tasks being more amenable to correction; (3) GQC knowledge inconsistencies that decrease as model size increases; and (4) an intriguing inter-model critiquing dynamic, where stronger models are better at critiquing weaker ones, while weaker models can surprisingly surpass stronger ones in their self-critique. We hope these insights into the nuanced critique-correct reasoning of LLMs will foster further research in LLM critique and self-improvement.
Create account to get full access
Overview
• This paper introduces CriticBench, a new benchmark for evaluating the critique-correction reasoning capabilities of large language models (LLMs).
• CriticBench assesses how well LLMs can detect and correct flaws in given arguments, a valuable skill for real-world applications like policy analysis and decision-making.
• The paper presents the benchmark's design, datasets, and evaluation metrics, and uses it to analyze the reasoning capabilities of several state-of-the-art LLMs.
Plain English Explanation
CriticBench is a new tool that helps researchers and developers assess how well large language models (LLMs) can identify and fix problems in arguments or statements. This is an important skill, as LLMs are increasingly being used for tasks like policy analysis and decision-making, where the ability to critically evaluate information is crucial.
The researchers who created CriticBench designed a set of test scenarios that challenge LLMs to detect flaws in arguments and then suggest improvements. For example, an LLM might be asked to identify logical fallacies or missing evidence in a given statement, and then propose ways to strengthen the argument.
By using CriticBench to test different LLMs, the researchers were able to compare the models' critique-correction capabilities. This provides valuable insights into the current strengths and limitations of LLM reasoning, which can help guide the development of more advanced and reliable language models for real-world applications.
Technical Explanation
The paper introduces CriticBench, a new benchmark for evaluating the critique-correction reasoning capabilities of large language models (LLMs). CriticBench: Benchmarking LLMs for Critique-Correct Reasoning
The benchmark is designed to assess how well LLMs can detect and correct flaws in arguments, a valuable skill for applications like policy analysis and decision-making. CriticBench presents LLMs with a range of test scenarios that challenge them to identify logical fallacies, missing evidence, and other weaknesses in given statements, and then propose ways to improve the arguments.
The paper describes the benchmark's dataset creation process, evaluation metrics, and the performance of several state-of-the-art LLMs on the CriticBench tasks. The results provide insights into the current strengths and limitations of LLM reasoning, which can inform the development of more advanced and reliable language models for real-world applications. Beyond Accuracy: Evaluating Reasoning Behavior in Large Language Models, Evaluating Consistency and Reasoning Capabilities of Large Language Models, and Evaluating Deductive Competence of Large Language Models are related papers that explore different approaches to evaluating the reasoning capabilities of LLMs.
Critical Analysis
The CriticBench paper provides a valuable contribution to the field of language model evaluation by introducing a novel benchmark focused on critique-correction reasoning. This is an important capability for many real-world applications of LLMs, and the benchmark offers a systematic way to assess it.
However, the paper acknowledges some limitations of the current CriticBench design, such as the potential for bias in the dataset creation process and the challenge of capturing the full complexity of critique-correction reasoning. Additionally, the evaluation metrics used may not fully capture all aspects of this skill, and there is room for further research to refine the benchmark and explore other evaluation approaches. Evaluating Interventional Reasoning Capabilities of Large Language Models is another related paper that discusses the importance of evaluating different types of reasoning in LLMs.
As the authors note, the CriticBench results highlight the current limitations of state-of-the-art LLMs in terms of critique-correction reasoning, suggesting that more work is needed to develop models with stronger reasoning capabilities. Addressing these limitations will be crucial for the safe and reliable deployment of LLMs in high-stakes applications.
Conclusion
The CriticBench paper introduces a novel benchmark for evaluating the critique-correction reasoning capabilities of large language models (LLMs), a valuable skill for real-world applications like policy analysis and decision-making. The benchmark's design, datasets, and evaluation results provide valuable insights into the current strengths and limitations of LLM reasoning, which can inform the development of more advanced and reliable language models.
While CriticBench represents an important step forward in LLM evaluation, the paper acknowledges some limitations and areas for further research. Continued efforts to develop robust and comprehensive evaluation frameworks for LLM reasoning will be crucial as these models become more widely deployed in high-stakes domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, Chitta Baral
0
0
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
6/7/2024

New!Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Navonil Majumder, Deepanway Ghosal, Somak Aditya, Rada Mihalcea, Soujanya Poria
0
0
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
6/28/2024
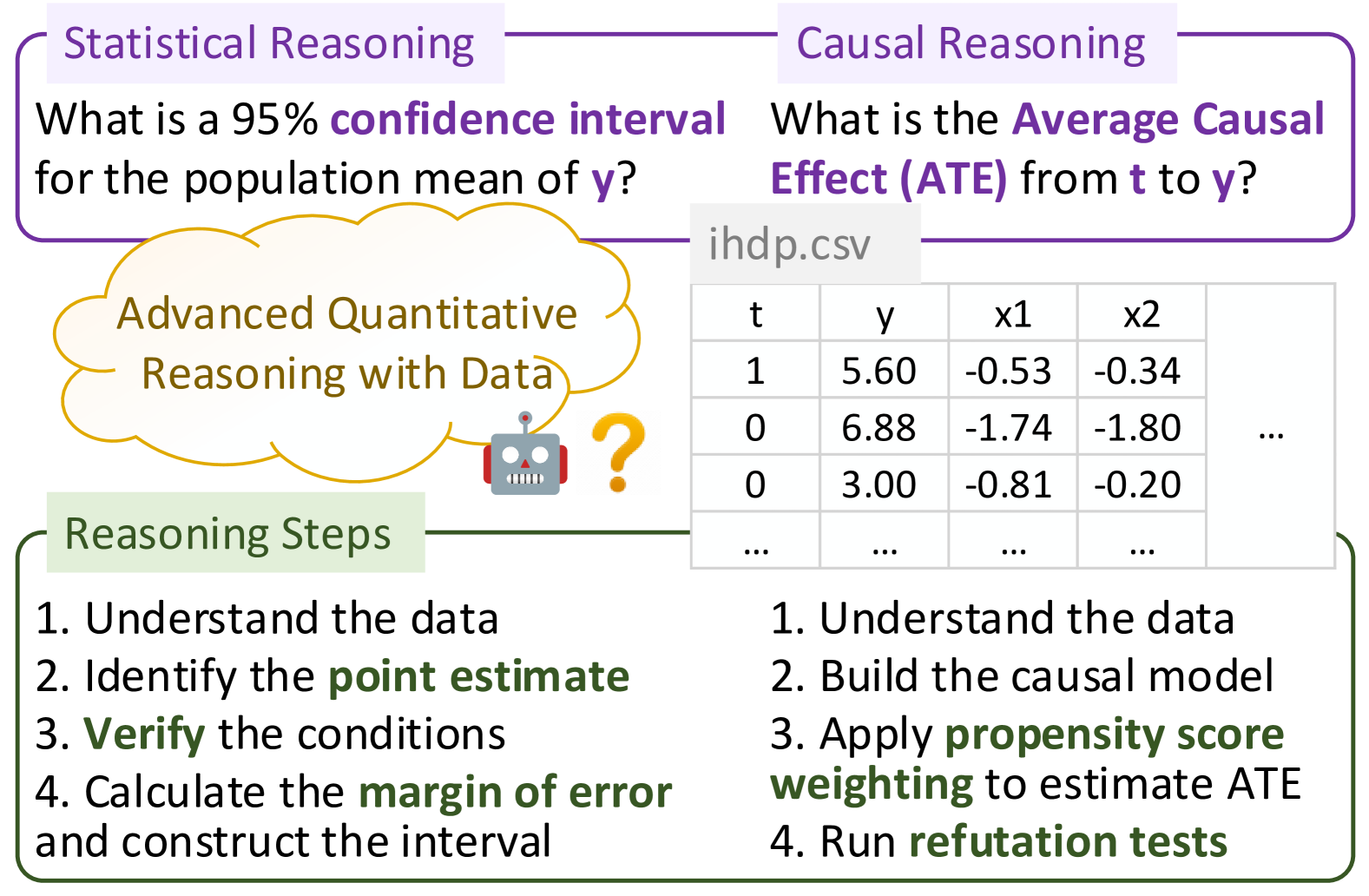
Are LLMs Capable of Data-based Statistical and Causal Reasoning? Benchmarking Advanced Quantitative Reasoning with Data
Xiao Liu, Zirui Wu, Xueqing Wu, Pan Lu, Kai-Wei Chang, Yansong Feng
0
0
Quantitative reasoning is a critical skill to analyze data, yet the assessment of such ability remains limited. To address this gap, we introduce the Quantitative Reasoning with Data (QRData) benchmark, aiming to evaluate Large Language Models' capability in statistical and causal reasoning with real-world data. The benchmark comprises a carefully constructed dataset of 411 questions accompanied by data sheets from textbooks, online learning materials, and academic papers. To compare models' quantitative reasoning abilities on data and text, we enrich the benchmark with an auxiliary set of 290 text-only questions, namely QRText. We evaluate natural language reasoning, program-based reasoning, and agent reasoning methods including Chain-of-Thought, Program-of-Thoughts, ReAct, and code interpreter assistants on diverse models. The strongest model GPT-4 achieves an accuracy of 58%, which has much room for improvement. Among open-source models, Deepseek-coder-instruct, a code LLM pretrained on 2T tokens, gets the highest accuracy of 37%. Analysis reveals that models encounter difficulties in data analysis and causal reasoning, and struggle in using causal knowledge and provided data simultaneously. Code and data are in https://github.com/xxxiaol/QRData.
6/11/2024
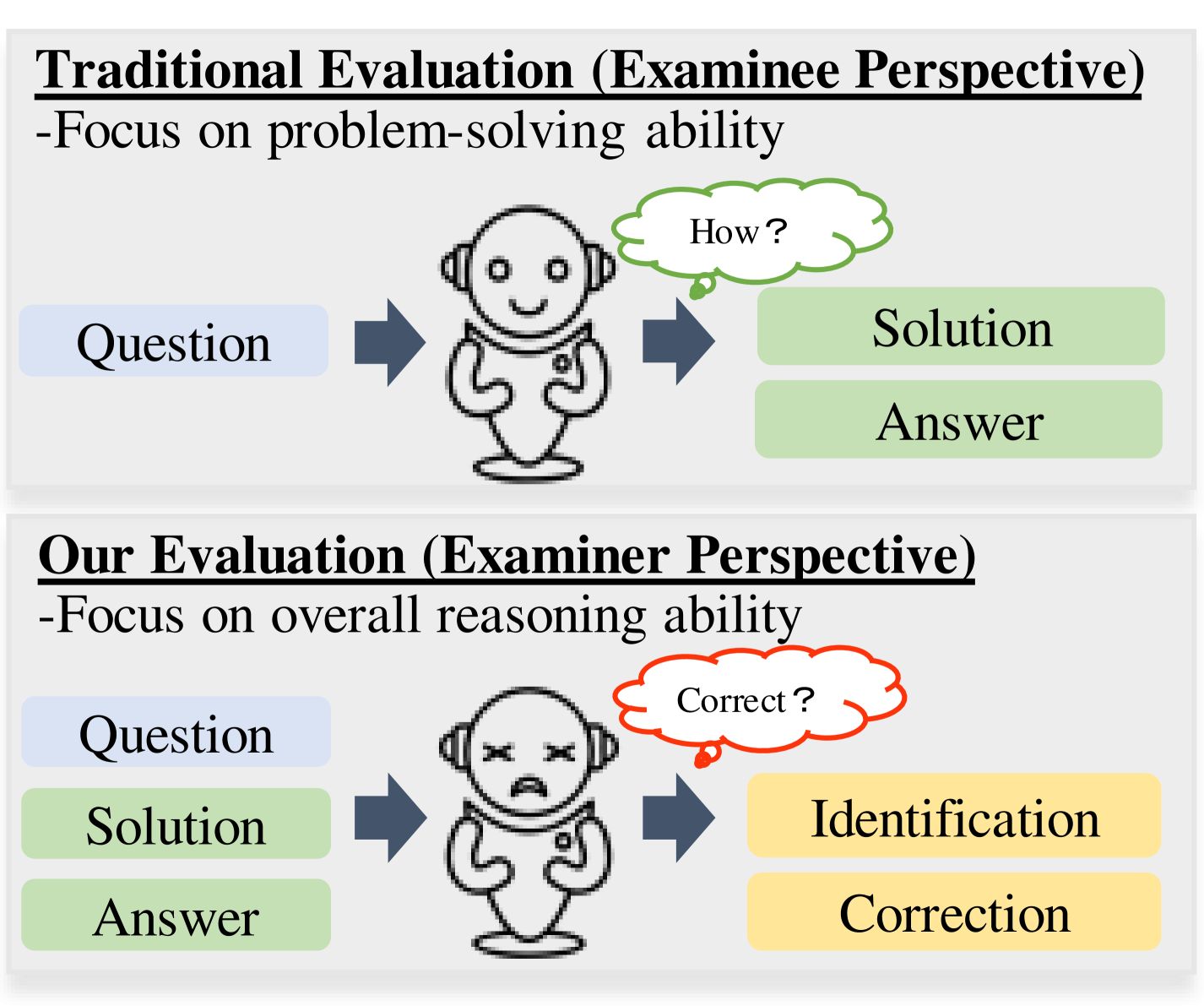
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
0
0
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
6/4/2024