Critical Influence of Overparameterization on Sharpness-aware Minimization

0
Sign in to get full access
Overview
• This paper examines the effects of overparameterization on sharpness-aware minimization (SAM), a technique used in machine learning to train models that are less sensitive to small changes in the input data.
• The researchers conduct both empirical and theoretical analyses to understand how the degree of overparameterization (having more parameters than needed to fit the training data) impacts the performance and behavior of SAM.
Plain English Explanation
• Overparameterization is a common phenomenon in machine learning where models have more parameters (numbers that can be adjusted to improve performance) than are strictly necessary to fit the training data.
• Sharpness-aware minimization is a technique that aims to train models that are not only accurate on the training data, but also robust to small changes in the input. This can help the model generalize better to new, unseen data.
• The researchers in this paper wanted to understand how the degree of overparameterization affects the performance and behavior of sharpness-aware minimization. They used both experimental methods and mathematical analysis to study this relationship.
Technical Explanation
• The paper presents both empirical and theoretical analyses of how overparameterization impacts sharpness-aware minimization (SAM).
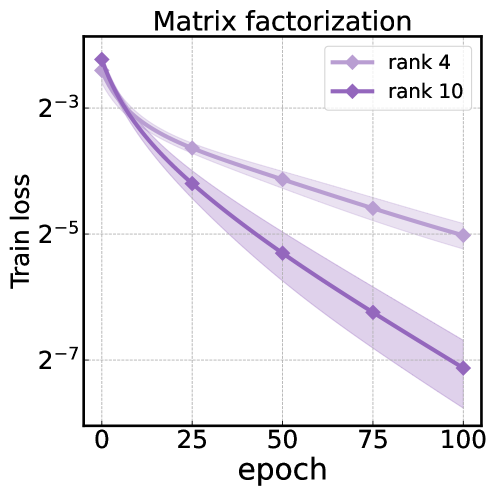
• Empirically, the researchers train neural network models with varying degrees of overparameterization and evaluate their performance on standard benchmark tasks using SAM. They find that increased overparameterization can improve the performance of SAM, but only up to a certain point.
• Theoretically, the paper provides an analysis of how overparameterization affects the optimization landscape that SAM navigates. The researchers show that overparameterization can create "flat" regions in the landscape that are beneficial for SAM, but excessive overparameterization can also introduce undesirable "sharp" regions that can hurt performance.
• The theoretical analysis also reveals how the choice of hyperparameters in SAM, such as the sharpness regularization strength, interacts with the degree of overparameterization to impact the final model performance.
Critical Analysis
• The paper provides a nuanced and systematic investigation of the interplay between overparameterization and sharpness-aware minimization, which is an important practical and theoretical question in machine learning.
• The combination of empirical and theoretical analyses helps to build a more comprehensive understanding of this phenomenon, though the theoretical analysis relies on some simplifying assumptions that may not fully capture the complexities of real-world neural network training.
• It would be interesting to see how these insights extend to other sharpness-aware optimization methods, such as those discussed in related papers (Universal Class Sharpness-Aware Minimization Algorithms, Sharpness-Aware Minimization for Efficiently Improving Generalization in Genetic Programming, Forget Sharpness, Perturbed Forgetting Helps Model Biases Within, Agnostic Sharpness-Aware Minimization).
Conclusion
• This paper provides valuable insights into how the degree of overparameterization affects the performance and behavior of sharpness-aware minimization, a key technique for training robust machine learning models.
• The findings suggest that there is an optimal level of overparameterization that can enhance the benefits of sharpness-aware minimization, but excessive overparameterization can also introduce challenges.
• These insights can help machine learning practitioners make more informed choices when applying sharpness-aware minimization and understand the tradeoffs involved in model design and optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Critical Influence of Overparameterization on Sharpness-aware Minimization
Sungbin Shin, Dongyeop Lee, Maksym Andriushchenko, Namhoon Lee
Training an overparameterized neural network can yield minimizers of different generalization capabilities despite the same level of training loss. Meanwhile, with evidence that suggests a strong correlation between the sharpness of minima and their generalization errors, increasing efforts have been made to develop optimization methods to explicitly find flat minima as more generalizable solutions. Despite its contemporary relevance to overparameterization, however, this sharpness-aware minimization (SAM) strategy has not been studied much yet as to exactly how it is affected by overparameterization. Hence, in this work, we analyze SAM under overparameterization of varying degrees and present both empirical and theoretical results that indicate a critical influence of overparameterization on SAM. At first, we conduct extensive numerical experiments across vision, language, graph, and reinforcement learning domains and show that SAM consistently improves with overparameterization. Next, we attribute this phenomenon to the interplay between the enlarged solution space and increased implicit bias from overparameterization. Further, we prove multiple theoretical benefits of overparameterization for SAM to attain (i) minima with more uniform Hessian moments compared to SGD, (ii) much faster convergence at a linear rate, and (iii) lower test error for two-layer networks. Last but not least, we discover that the effect of overparameterization is more significantly pronounced in practical settings of label noise and sparsity, and yet, sufficient regularization is necessary.
Read more6/21/2024

0
Sharpness-Aware Minimization Enhances Feature Quality via Balanced Learning
Jacob Mitchell Springer, Vaishnavh Nagarajan, Aditi Raghunathan
Sharpness-Aware Minimization (SAM) has emerged as a promising alternative optimizer to stochastic gradient descent (SGD). The originally-proposed motivation behind SAM was to bias neural networks towards flatter minima that are believed to generalize better. However, recent studies have shown conflicting evidence on the relationship between flatness and generalization, suggesting that flatness does fully explain SAM's success. Sidestepping this debate, we identify an orthogonal effect of SAM that is beneficial out-of-distribution: we argue that SAM implicitly balances the quality of diverse features. SAM achieves this effect by adaptively suppressing well-learned features which gives remaining features opportunity to be learned. We show that this mechanism is beneficial in datasets that contain redundant or spurious features where SGD falls for the simplicity bias and would not otherwise learn all available features. Our insights are supported by experiments on real data: we demonstrate that SAM improves the quality of features in datasets containing redundant or spurious features, including CelebA, Waterbirds, CIFAR-MNIST, and DomainBed.
Read more6/3/2024

0
A Universal Class of Sharpness-Aware Minimization Algorithms
Behrooz Tahmasebi, Ashkan Soleymani, Dara Bahri, Stefanie Jegelka, Patrick Jaillet
Recently, there has been a surge in interest in developing optimization algorithms for overparameterized models as achieving generalization is believed to require algorithms with suitable biases. This interest centers on minimizing sharpness of the original loss function; the Sharpness-Aware Minimization (SAM) algorithm has proven effective. However, most literature only considers a few sharpness measures, such as the maximum eigenvalue or trace of the training loss Hessian, which may not yield meaningful insights for non-convex optimization scenarios like neural networks. Additionally, many sharpness measures are sensitive to parameter invariances in neural networks, magnifying significantly under rescaling parameters. Motivated by these challenges, we introduce a new class of sharpness measures in this paper, leading to new sharpness-aware objective functions. We prove that these measures are textit{universally expressive}, allowing any function of the training loss Hessian matrix to be represented by appropriate hyperparameters. Furthermore, we show that the proposed objective functions explicitly bias towards minimizing their corresponding sharpness measures, and how they allow meaningful applications to models with parameter invariances (such as scale-invariances). Finally, as instances of our proposed general framework, we present textit{Frob-SAM} and textit{Det-SAM}, which are specifically designed to minimize the Frobenius norm and the determinant of the Hessian of the training loss, respectively. We also demonstrate the advantages of our general framework through extensive experiments.
Read more6/11/2024
🖼️
0
Do Sharpness-based Optimizers Improve Generalization in Medical Image Analysis?
Mohamed Hassan, Aleksandar Vakanski, Min Xian
Effective clinical deployment of deep learning models in healthcare demands high generalization performance to ensure accurate diagnosis and treatment planning. In recent years, significant research has focused on improving the generalization of deep learning models by regularizing the sharpness of the loss landscape. Among the optimization approaches that explicitly minimize sharpness, Sharpness-Aware Minimization (SAM) has shown potential in enhancing generalization performance on general domain image datasets. This success has led to the development of several advanced sharpness-based algorithms aimed at addressing the limitations of SAM, such as Adaptive SAM, surrogate-Gap SAM, Weighted SAM, and Curvature Regularized SAM. These sharpness-based optimizers have shown improvements in model generalization compared to conventional stochastic gradient descent optimizers and their variants on general domain image datasets, but they have not been thoroughly evaluated on medical images. This work provides a review of recent sharpness-based methods for improving the generalization of deep learning networks and evaluates the methods performance on medical breast ultrasound images. Our findings indicate that the initial SAM method successfully enhances the generalization of various deep learning models. While Adaptive SAM improves generalization of convolutional neural networks, it fails to do so for vision transformers. Other sharpness-based optimizers, however, do not demonstrate consistent results. The results reveal that, contrary to findings in the non-medical domain, SAM is the only recommended sharpness-based optimizer that consistently improves generalization in medical image analysis, and further research is necessary to refine the variants of SAM to enhance generalization performance in this field
Read more8/13/2024