Criticality and Safety Margins for Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- Reinforcement learning (RL) agents sometimes encounter unsafe situations that could lead to poor performance or even catastrophic failure.
- Identifying these critical situations is important for both post-hoc analysis and real-time monitoring during deployment.
- Current methods to gauge criticality have limitations, including lack of ground truth and unclear interpretability for end-users.
- This paper introduces a framework to define and measure "true criticality" and "proxy criticality" to address these issues.
Plain English Explanation
The paper discusses a key challenge in reinforcement learning (RL) - the ability to identify when an RL agent is in a critical or unsafe situation. RL agents, which learn to make decisions through trial-and-error, can sometimes end up in situations where their decisions could lead to very bad outcomes, like causing damage or failing at their task.
Being able to recognize these critical moments is important for a few reasons. First, it allows researchers to analyze the agent's behavior after the fact and understand what went wrong. Second, and more importantly, it could allow the RL system to call for help from a human overseer during deployment, before the agent makes a disastrous decision.
However, the researchers argue that current methods for measuring criticality have limitations. They may not have a clear "ground truth" to compare against, and the results are not always easy for non-experts to interpret.
To address this, the paper introduces two new concepts - "true criticality" and "proxy criticality." True criticality is defined as the expected drop in reward if the agent were to suddenly start taking random actions for a period of time, rather than following its learned policy. Proxy criticality is a simpler, faster metric that is statistically related to true criticality.
By defining these criticality measures and introducing "safety margins" (the number of random actions the agent can take before performance drops unacceptably), the researchers provide a framework that can both quantify criticality and make it interpretable for end-users. They demonstrate this approach in an Atari game environment, showing that by monitoring just the 5% of moments with the lowest safety margins, they could potentially prevent around half of the agent's errors.
The key insight is that this criticality framework allows RL systems to detect dangerous situations even before they occur, enabling more effective oversight and debugging of autonomous agents.
Technical Explanation
The paper introduces a framework to quantify the "criticality" of different states encountered by a reinforcement learning (RL) agent. True criticality is defined as the expected drop in reward when an agent deviates from its learned policy and starts taking n consecutive random actions. This provides a quantifiable ground truth for assessing how dangerous a particular state is.
The researchers also introduce the concept of proxy criticality, which is a computationally cheaper metric that has a statistically monotonic relationship with true criticality. Proxy criticality can be calculated more efficiently, making it more feasible to monitor in real-time.
To make these criticality measures interpretable, the paper defines safety margins - the number of random actions an agent can take before its performance is expected to drop below a certain tolerance level with high confidence. These safety margins provide a clear, user-friendly way to understand the potential risks at different points in time.
The approach is evaluated in the Atari Beamrider environment, using an A3C agent. The results show that the lowest 5% of safety margins contained 47% of the agent's losses. This indicates that by only monitoring a small fraction of the most critical moments, the system could potentially prevent around half of the agent's errors.
The key innovation is the ability to quantify criticality in a way that is both grounded in a clear performance-based definition (true criticality) and can be efficiently approximated (proxy criticality). This allows the system to warn of potentially dangerous situations even before they occur, enabling more effective debugging and oversight of autonomous RL agents.
Critical Analysis
The paper presents a novel and promising framework for identifying critical situations in reinforcement learning agents. The authors' definition of "true criticality" as the expected performance drop when deviating from the policy provides a clear, quantifiable ground truth. And the introduction of "proxy criticality" as a computationally efficient approximation is an important practical contribution.
One limitation, as acknowledged by the authors, is the lack of a "true ground truth" for criticality. While the performance drop metric is intuitive, it may not capture all nuances of what constitutes a truly critical situation. There could be other factors, like safety or robustness, that are not directly reflected in reward.
Additionally, the paper only evaluates the approach in a single Atari environment. More testing is needed to understand how well the criticality framework generalizes to other domains, especially more complex real-world settings where RL agents may encounter a wider range of critical situations.
Further research could also explore ways to integrate the criticality measures more tightly into the RL training process, rather than just using them for post-hoc analysis or real-time monitoring. This could help RL agents learn policies that are more robust to critical states.
Overall, this work represents an important step towards safer and more reliable reinforcement learning systems. The criticality framework provides a principled way to identify and mitigate potentially dangerous situations, which is a key challenge in deploying RL agents in high-stakes applications.
Conclusion
This paper introduces a novel framework for quantifying the "criticality" of different states encountered by reinforcement learning agents. By defining "true criticality" as the expected performance drop when deviating from the agent's policy, and "proxy criticality" as an efficient approximation, the researchers provide a way to both accurately measure and interpretably communicate the potential risks at different points in time.
The key innovation is the ability to detect critical situations even before they occur, enabling more effective debugging and oversight of autonomous RL agents. The authors demonstrate the approach in an Atari game environment, showing that monitoring just the 5% of moments with the lowest "safety margins" could potentially prevent around half of the agent's errors.
While more research is needed to fully validate and generalize the criticality framework, this work represents an important step towards building safer and more reliable reinforcement learning systems. By quantifying the risks associated with different states, RL agents can be better equipped to handle unexpected or dangerous situations, paving the way for wider real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Criticality and Safety Margins for Reinforcement Learning
Alexander Grushin, Walt Woods, Alvaro Velasquez, Simon Khan
State of the art reinforcement learning methods sometimes encounter unsafe situations. Identifying when these situations occur is of interest both for post-hoc analysis and during deployment, where it might be advantageous to call out to a human overseer for help. Efforts to gauge the criticality of different points in time have been developed, but their accuracy is not well established due to a lack of ground truth, and they are not designed to be easily interpretable by end users. Therefore, we seek to define a criticality framework with both a quantifiable ground truth and a clear significance to users. We introduce true criticality as the expected drop in reward when an agent deviates from its policy for n consecutive random actions. We also introduce the concept of proxy criticality, a low-overhead metric that has a statistically monotonic relationship to true criticality. Safety margins make these interpretable, when defined as the number of random actions for which performance loss will not exceed some tolerance with high confidence. We demonstrate this approach in several environment-agent combinations; for an A3C agent in an Atari Beamrider environment, the lowest 5% of safety margins contain 47% of agent losses; i.e., supervising only 5% of decisions could potentially prevent roughly half of an agent's errors. This criticality framework measures the potential impacts of bad decisions, even before those decisions are made, allowing for more effective debugging and oversight of autonomous agents.
Read more9/30/2024
0
Accurately Predicting Probabilities of Safety-Critical Rare Events for Intelligent Systems
Ruoxuan Bai, Jingxuan Yang, Weiduo Gong, Yi Zhang, Qiujing Lu, Shuo Feng
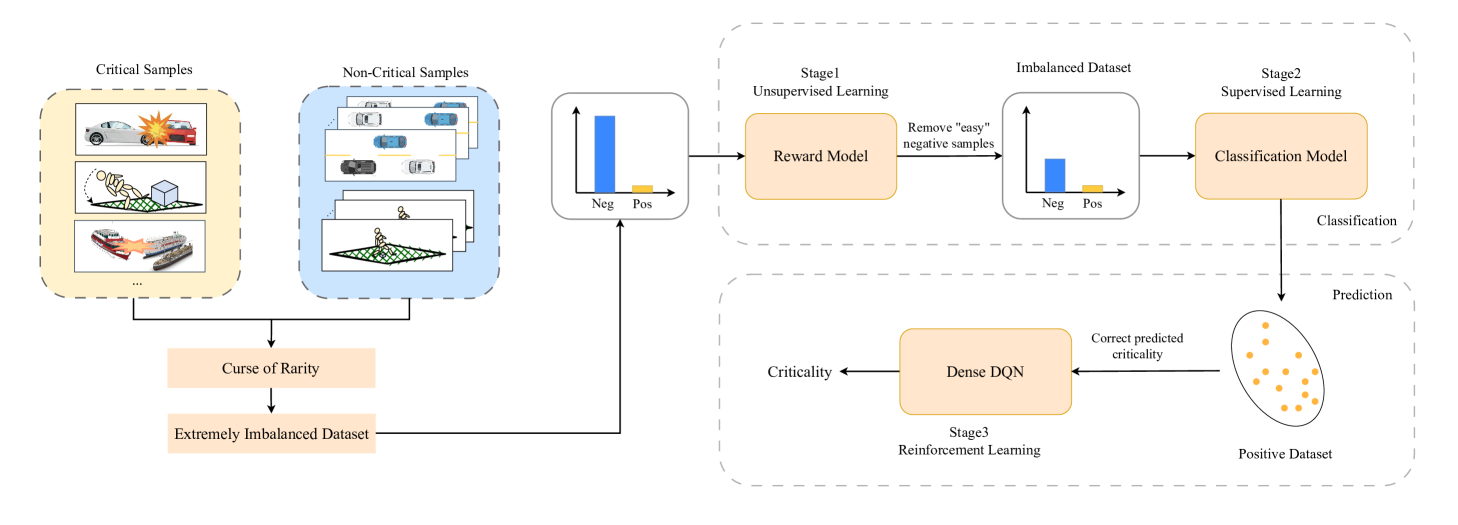
Intelligent systems are increasingly integral to our daily lives, yet rare safety-critical events present significant latent threats to their practical deployment. Addressing this challenge hinges on accurately predicting the probability of safety-critical events occurring within a given time step from the current state, a metric we define as 'criticality'. The complexity of predicting criticality arises from the extreme data imbalance caused by rare events in high dimensional variables associated with the rare events, a challenge we refer to as the curse of rarity. Existing methods tend to be either overly conservative or prone to overlooking safety-critical events, thus struggling to achieve both high precision and recall rates, which severely limits their applicability. This study endeavors to develop a criticality prediction model that excels in both precision and recall rates for evaluating the criticality of safety-critical autonomous systems. We propose a multi-stage learning framework designed to progressively densify the dataset, mitigating the curse of rarity across stages. To validate our approach, we evaluate it in two cases: lunar lander and bipedal walker scenarios. The results demonstrate that our method surpasses traditional approaches, providing a more accurate and dependable assessment of criticality in intelligent systems.
Read more4/8/2024
0
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
Read more5/7/2024

0
Safety through feedback in Constrained RL
Shashank Reddy Chirra, Pradeep Varakantham, Praveen Paruchuri
In safety-critical RL settings, the inclusion of an additional cost function is often favoured over the arduous task of modifying the reward function to ensure the agent's safe behaviour. However, designing or evaluating such a cost function can be prohibitively expensive. For instance, in the domain of self-driving, designing a cost function that encompasses all unsafe behaviours (e.g. aggressive lane changes) is inherently complex. In such scenarios, the cost function can be learned from feedback collected offline in between training rounds. This feedback can be system generated or elicited from a human observing the training process. Previous approaches have not been able to scale to complex environments and are constrained to receiving feedback at the state level which can be expensive to collect. To this end, we introduce an approach that scales to more complex domains and extends to beyond state-level feedback, thus, reducing the burden on the evaluator. Inferring the cost function in such settings poses challenges, particularly in assigning credit to individual states based on trajectory-level feedback. To address this, we propose a surrogate objective that transforms the problem into a state-level supervised classification task with noisy labels, which can be solved efficiently. Additionally, it is often infeasible to collect feedback on every trajectory generated by the agent, hence, two fundamental questions arise: (1) Which trajectories should be presented to the human? and (2) How many trajectories are necessary for effective learning? To address these questions, we introduce textit{novelty-based sampling} that selectively involves the evaluator only when the the agent encounters a textit{novel} trajectory. We showcase the efficiency of our method through experimentation on several benchmark Safety Gymnasium environments and realistic self-driving scenarios.
Read more7/1/2024