Safety through feedback in Constrained RL

0

Sign in to get full access
Overview
- This paper presents a method for improving the safety of reinforcement learning (RL) agents by incorporating feedback signals during training.
- The proposed approach, called "Safety through Feedback in Constrained RL", aims to enable RL agents to learn safe behaviors while optimizing for a primary task.
- The method leverages constraints and feedback signals to guide the agent's learning process and ensure that it avoids unsafe actions or states.
Plain English Explanation
The paper focuses on the challenge of making reinforcement learning (RL) systems safe and reliable, especially in scenarios where the agent's actions could lead to harmful or undesirable outcomes. RL agents are often trained to optimize a primary task, such as winning a game or completing a task, but this can sometimes lead them to take risky or unsafe actions.
To address this, the researchers developed a new method that incorporates feedback signals during the training process. The idea is to give the RL agent additional information about what actions or states are considered safe or unsafe, and then use this feedback to guide the agent's learning. This way, the agent can learn to optimize its performance on the primary task while also avoiding unsafe behaviors.
The feedback signals could come from a human supervisor, a set of predefined rules, or even from the agent's own internal understanding of safety. By using these signals, the RL agent can learn to balance its primary objective with the need to stay within safe boundaries.
This approach is particularly useful in applications where safety is critical, such as self-driving cars, medical decision-making, or industrial control systems. By incorporating feedback and constraints into the RL training process, the researchers hope to create agents that can operate safely and reliably in the real world.
Technical Explanation
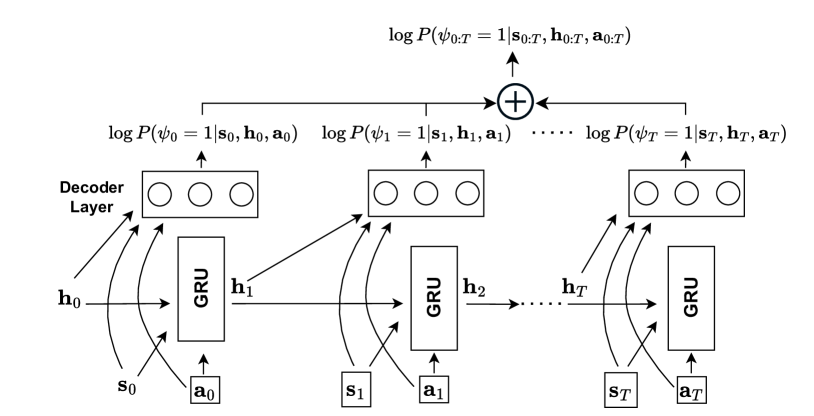
The paper formalizes the problem of "Constrained Reinforcement Learning" (CRL), where an RL agent must optimize a primary task while also satisfying a set of safety constraints. The authors introduce a novel approach called "Safety through Feedback in Constrained RL" that leverages feedback signals to guide the agent's learning process.
The key components of the proposed method include:
-
Markov Decision Process (MDP): The RL problem is formulated as an MDP, which includes the agent's state, actions, transition dynamics, and a reward function.
-
Safety Constraints: In addition to the primary reward function, the agent must also satisfy a set of safety constraints, which are represented as additional cost functions.
-
Feedback Signals: During training, the agent receives feedback signals that indicate whether its actions or states are considered safe or unsafe. These signals can come from a variety of sources, such as human supervisors, predefined rules, or the agent's own internal understanding of safety.
-
Constrained Optimization: The agent's learning process is formulated as a constrained optimization problem, where the primary objective is to maximize the cumulative reward, subject to the safety constraints.
-
Adaptive Shaping of Feedback: The feedback signals are adaptively shaped during training to balance the agent's primary task performance with its safety requirements.
Through extensive experiments, the authors demonstrate that their "Safety through Feedback in Constrained RL" approach can successfully train RL agents to learn safe behaviors while optimizing for a primary task. The method outperforms alternative approaches, such as Safe Reinforcement Learning through Learned Non-Markovian Rewards, Jointly Learning Cost Constraints from Demonstrations, and Do No Harm: Counterfactual Approach to Safe Exploration, in terms of both primary task performance and safety constraint satisfaction.
Critical Analysis
The paper presents a promising approach for improving the safety of reinforcement learning systems, which is a critical challenge in the field. By incorporating feedback signals during training, the method can guide the agent's learning process to balance its primary objective with safety requirements.
One potential limitation of the approach is that it relies on the availability of accurate and reliable feedback signals. In real-world applications, obtaining such signals may be challenging, especially if they need to come from human supervisors or complex rule-based systems. The paper does not extensively discuss the practical challenges of obtaining and incorporating these feedback signals.
Additionally, the paper focuses on a single primary task and a set of predefined safety constraints. In more complex, real-world scenarios, RL agents may need to navigate multiple, potentially conflicting objectives and safety concerns. The authors mention that their method can be extended to handle multi-objective problems, but further research may be needed to fully address this challenge.
Another area for potential improvement is the adaptive shaping of the feedback signals during training. The current approach may require careful tuning of hyperparameters to achieve the right balance between primary task performance and safety. Exploring more sophisticated techniques for adaptively adjusting the feedback signals could further improve the method's robustness and applicability.
Overall, the "Safety through Feedback in Constrained RL" approach represents an important step forward in the quest for safe and reliable reinforcement learning systems. The paper's insights and experimental results provide a solid foundation for future research in this area, with potential applications in a wide range of safety-critical domains.
Conclusion
This paper introduces a novel method called "Safety through Feedback in Constrained RL" that aims to improve the safety of reinforcement learning agents by incorporating feedback signals during the training process. The key idea is to guide the agent's learning towards optimizing its primary task while also satisfying a set of safety constraints, using feedback signals from various sources.
The researchers demonstrate the effectiveness of their approach through extensive experiments, showing that it can outperform alternative methods in terms of both primary task performance and safety constraint satisfaction. This work represents an important contribution to the field of safe reinforcement learning, with potential applications in safety-critical domains such as self-driving cars, medical decision-making, and industrial control systems.
While the paper presents a promising solution, it also highlights the need for further research to address practical challenges, such as the availability and reliability of feedback signals, as well as the extension of the method to handle more complex, multi-objective scenarios. Continued advancements in this area will be crucial for unlocking the full potential of reinforcement learning while ensuring the safety and reliability of these systems in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Safety through feedback in Constrained RL
Shashank Reddy Chirra, Pradeep Varakantham, Praveen Paruchuri
In safety-critical RL settings, the inclusion of an additional cost function is often favoured over the arduous task of modifying the reward function to ensure the agent's safe behaviour. However, designing or evaluating such a cost function can be prohibitively expensive. For instance, in the domain of self-driving, designing a cost function that encompasses all unsafe behaviours (e.g. aggressive lane changes) is inherently complex. In such scenarios, the cost function can be learned from feedback collected offline in between training rounds. This feedback can be system generated or elicited from a human observing the training process. Previous approaches have not been able to scale to complex environments and are constrained to receiving feedback at the state level which can be expensive to collect. To this end, we introduce an approach that scales to more complex domains and extends to beyond state-level feedback, thus, reducing the burden on the evaluator. Inferring the cost function in such settings poses challenges, particularly in assigning credit to individual states based on trajectory-level feedback. To address this, we propose a surrogate objective that transforms the problem into a state-level supervised classification task with noisy labels, which can be solved efficiently. Additionally, it is often infeasible to collect feedback on every trajectory generated by the agent, hence, two fundamental questions arise: (1) Which trajectories should be presented to the human? and (2) How many trajectories are necessary for effective learning? To address these questions, we introduce textit{novelty-based sampling} that selectively involves the evaluator only when the the agent encounters a textit{novel} trajectory. We showcase the efficiency of our method through experimentation on several benchmark Safety Gymnasium environments and realistic self-driving scenarios.
Read more7/1/2024
0
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
Read more5/7/2024
🛸
0
Jointly Learning Cost and Constraints from Demonstrations for Safe Trajectory Generation
Shivam Chaubey, Francesco Verdoja, Ville Kyrki
Learning from Demonstration allows robots to mimic human actions. However, these methods do not model constraints crucial to ensure safety of the learned skill. Moreover, even when explicitly modelling constraints, they rely on the assumption of a known cost function, which limits their practical usability for task with unknown cost. In this work we propose a two-step optimization process that allow to estimate cost and constraints by decoupling the learning of cost functions from the identification of unknown constraints within the demonstrated trajectories. Initially, we identify the cost function by isolating the effect of constraints on parts of the demonstrations. Subsequently, a constraint leaning method is used to identify the unknown constraints. Our approach is validated both on simulated trajectories and a real robotic manipulation task. Our experiments show the impact that incorrect cost estimation has on the learned constraints and illustrate how the proposed method is able to infer unknown constraints, such as obstacles, from demonstrated trajectories without any initial knowledge of the cost.
Read more9/10/2024
🏅
0
Handling Long-Term Safety and Uncertainty in Safe Reinforcement Learning
Jonas Gunster, Puze Liu, Jan Peters, Davide Tateo
Safety is one of the key issues preventing the deployment of reinforcement learning techniques in real-world robots. While most approaches in the Safe Reinforcement Learning area do not require prior knowledge of constraints and robot kinematics and rely solely on data, it is often difficult to deploy them in complex real-world settings. Instead, model-based approaches that incorporate prior knowledge of the constraints and dynamics into the learning framework have proven capable of deploying the learning algorithm directly on the real robot. Unfortunately, while an approximated model of the robot dynamics is often available, the safety constraints are task-specific and hard to obtain: they may be too complicated to encode analytically, too expensive to compute, or it may be difficult to envision a priori the long-term safety requirements. In this paper, we bridge this gap by extending the safe exploration method, ATACOM, with learnable constraints, with a particular focus on ensuring long-term safety and handling of uncertainty. Our approach is competitive or superior to state-of-the-art methods in final performance while maintaining safer behavior during training.
Read more9/24/2024