Cross-Architecture Transfer Learning for Linear-Cost Inference Transformers
2404.02684
0
0

Abstract
Recently, multiple architectures has been proposed to improve the efficiency of the Transformer Language Models through changing the design of the self-attention block to have a linear-cost inference (LCI). A notable approach in this realm is the State-Space Machines (SSMs) architecture, which showed on-par performance on language modeling tasks with the self-attention transformers. However, such an architectural change requires a full pretraining of the weights from scratch, which incurs a huge cost to researchers and practitioners who want to use the new architectures. In the more traditional linear attention works, it has been proposed to approximate full attention with linear attention by swap-and-finetune framework. Motivated by this approach, we propose Cross-Architecture Transfer Learning (XATL), in which the weights of the shared components between LCI and self-attention-based transformers, such as layernorms, MLPs, input/output embeddings, are directly transferred to the new architecture from already pre-trained model parameters. We experimented the efficacy of the method on varying sizes and alternative attention architectures and show that methodabbr significantly reduces the training time up to 2.5x times and converges to a better minimum with up to 2.6% stronger model on the LM benchmarks within the same compute budget.
Create account to get full access
Overview
- This paper proposes a novel approach for cross-architecture transfer learning to enable efficient inference of large language models (LLMs) on resource-constrained devices.
- The key contributions include a linear-cost attention mechanism and a transfer learning technique that allows pre-trained LLMs to be fine-tuned on target architectures with minimal performance degradation.
- The proposed methods aim to enable the deployment of powerful LLMs on a wide range of edge devices and mobile applications.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly powerful, but they require a lot of computing power to run, which makes them difficult to use on smaller devices like smartphones or tablets. This paper presents a new way to make LLMs work more efficiently on these types of devices.
The researchers developed a new type of attention mechanism that is less computationally expensive, allowing the LLM to run faster without losing too much accuracy. They also created a method for "transferring" the knowledge from a pre-trained LLM to a new model that is better suited for running on low-power devices.
By combining these two innovations, the researchers were able to build LLMs that maintain their impressive capabilities while being much more efficient to run. This could enable a wide range of new applications for LLMs, such as [link to "Attending to Graph Transformers" paper] using them for language tasks on mobile devices or [link to "Efficiently Distilling LLMs for Edge Applications" paper] deploying them in edge computing environments.
Technical Explanation
The paper introduces a novel "linear-cost attention" mechanism that reduces the computational complexity of the standard attention used in transformer-based LLMs from quadratic to linear. This is achieved by approximating the attention scores using a low-rank factorization, which allows the attention calculations to be performed more efficiently.
To enable the deployment of these linear-cost attention transformers on resource-constrained devices, the authors propose a cross-architecture transfer learning technique. This involves pre-training a large transformer model on a high-performance server, then fine-tuning a compressed version of the model on the target hardware architecture. The transfer learning approach helps preserve the performance of the original LLM while adapting it to run efficiently on the target platform.
The paper evaluates the proposed methods on a range of language tasks and hardware platforms, demonstrating significant speedups and only modest accuracy degradation compared to the original LLMs. For example, on the [link to "Efficiently Distilling LLMs for Edge Applications" paper] GLUE benchmark, the linear-cost attention transformers achieved 95% of the performance of the full-size models while being 4x faster.
Critical Analysis
The paper presents a compelling approach for enabling the efficient deployment of large language models on edge devices and mobile platforms. The linear-cost attention mechanism and cross-architecture transfer learning techniques are well-motivated and appear to be effective based on the experiments.
However, the paper does not address some potential limitations and areas for further research. For instance, the transfer learning approach may be sensitive to the specific architectures involved, and the performance trade-offs could vary depending on the target hardware. Additionally, the paper does not explore the broader implications of making powerful LLMs more accessible on resource-constrained devices, such as potential privacy or security concerns.
It would be valuable for future work to investigate these issues in more depth, as well as explore other techniques for improving the efficiency of LLMs, such as [link to "How Does Multi-Task Training Affect Transformer" paper] multi-task training or [link to "is-attention-required-icl-exploring-relationship-between" paper] alternative neural architectures.
Conclusion
This paper presents an innovative approach for enabling the efficient inference of large language models on a wide range of hardware platforms, from powerful servers to resource-constrained edge devices. By developing a linear-cost attention mechanism and a cross-architecture transfer learning technique, the researchers have made significant progress towards the goal of deploying powerful LLMs in real-world applications that were previously out of reach.
The methods described in this paper could have far-reaching implications, from powering more capable virtual assistants on smartphones to enabling [link to "Dijiang: Efficient Large Language Models Through Compact" paper] new edge computing applications that leverage the capabilities of large language models. As the field of natural language processing continues to advance, this work represents an important step towards making these powerful AI technologies more accessible and practical for a diverse range of use cases.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Small-E: Small Language Model with Linear Attention for Efficient Speech Synthesis
Th'eodor Lemerle, Nicolas Obin, Axel Roebel
0
0
Recent advancements in text-to-speech (TTS) powered by language models have showcased remarkable capabilities in achieving naturalness and zero-shot voice cloning. Notably, the decoder-only transformer is the prominent architecture in this domain. However, transformers face challenges stemming from their quadratic complexity in sequence length, impeding training on lengthy sequences and resource-constrained hardware. Moreover they lack specific inductive bias with regards to the monotonic nature of TTS alignments. In response, we propose to replace transformers with emerging recurrent architectures and introduce specialized cross-attention mechanisms for reducing repeating and skipping issues. Consequently our architecture can be efficiently trained on long samples and achieve state-of-the-art zero-shot voice cloning against baselines of comparable size. Our implementation and demos are available at https://github.com/theodorblackbird/lina-speech.
6/12/2024
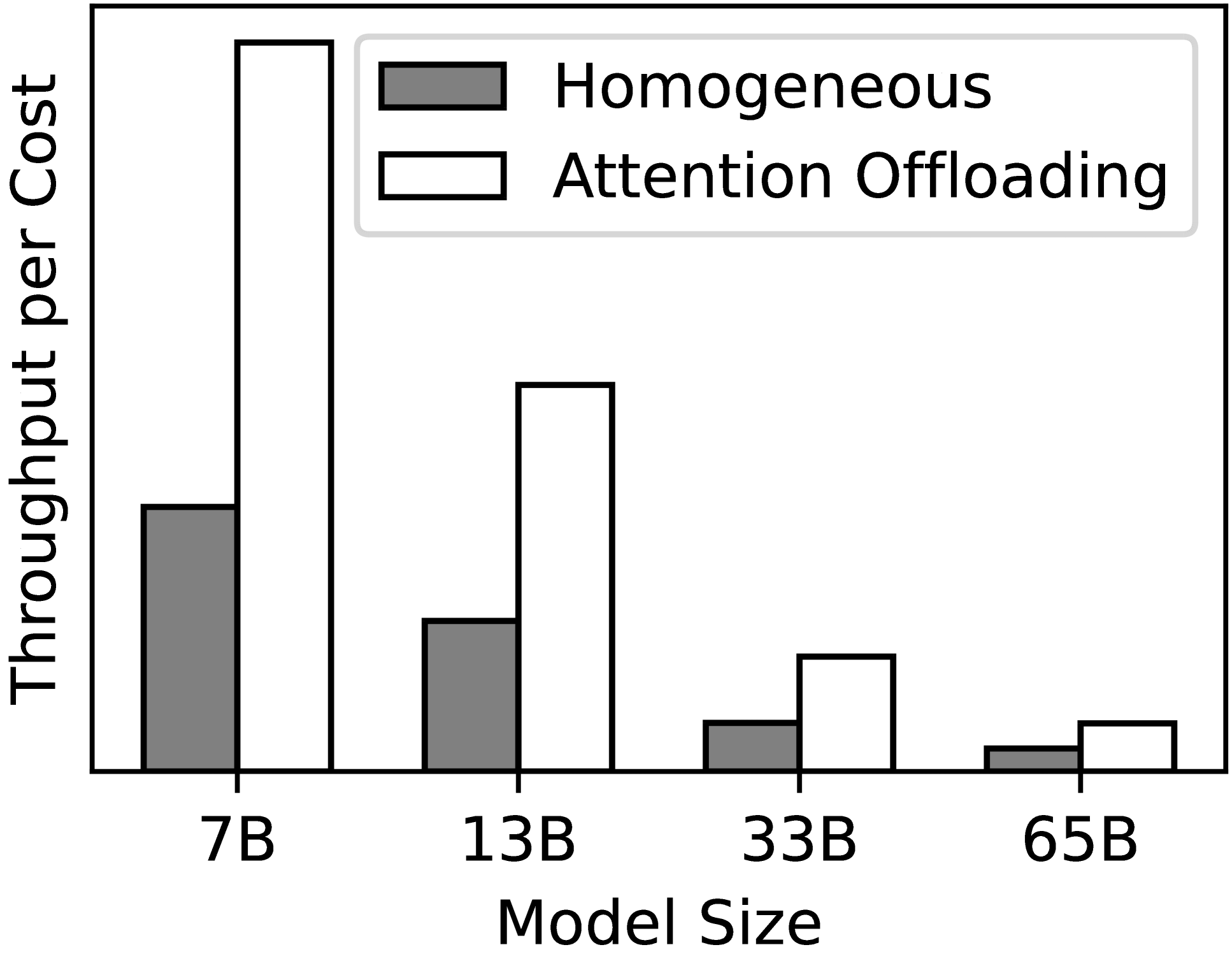
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
0
0
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
5/6/2024

What Matters in Transformers? Not All Attention is Needed
Shwai He, Guoheng Sun, Zheyu Shen, Ang Li
0
0
Scaling Transformer-based large language models (LLMs) has demonstrated promising performance across various tasks. However, this scaling also introduces redundant structures, posing challenges for real-world deployment. Despite some recognition of redundancy in LLMs, the variability of redundancy across different structures, such as MLP and Attention layers, is under-explored. In this work, we investigate the varying redundancy across different modules within Transformers, including Blocks, MLP, and Attention layers, using a similarity-based metric. This metric operates on the premise that redundant structures produce outputs highly similar to their inputs. Surprisingly, while attention layers are essential for transformers and distinguish them from other mainstream architectures, we found that a large proportion of attention layers exhibit excessively high similarity and can be safely pruned without degrading performance, leading to reduced memory and computation costs. Additionally, we further propose a method that jointly drops Attention and MLP layers, achieving improved performance and dropping ratios. Extensive experiments demonstrate the effectiveness of our methods, e.g., Llama-3-70B maintains comparable performance even after pruning half of the attention layers. Our findings provide valuable insights for future network architecture design. The code will be released at: url{https://github.com/Shwai-He/LLM-Drop}.
6/26/2024

Skip-Layer Attention: Bridging Abstract and Detailed Dependencies in Transformers
Qian Chen, Wen Wang, Qinglin Zhang, Siqi Zheng, Shiliang Zhang, Chong Deng, Hai Yu, Jiaqing Liu, Yukun Ma, Chong Zhang
0
0
The Transformer architecture has significantly advanced deep learning, particularly in natural language processing, by effectively managing long-range dependencies. However, as the demand for understanding complex relationships grows, refining the Transformer's architecture becomes critical. This paper introduces Skip-Layer Attention (SLA) to enhance Transformer models by enabling direct attention between non-adjacent layers. This method improves the model's ability to capture dependencies between high-level abstract features and low-level details. By facilitating direct attention between these diverse feature levels, our approach overcomes the limitations of current Transformers, which often rely on suboptimal intra-layer attention. Our implementation extends the Transformer's functionality by enabling queries in a given layer to interact with keys and values from both the current layer and one preceding layer, thus enhancing the diversity of multi-head attention without additional computational burden. Extensive experiments demonstrate that our enhanced Transformer model achieves superior performance in language modeling tasks, highlighting the effectiveness of our skip-layer attention mechanism.
6/18/2024