What Matters in Transformers? Not All Attention is Needed
2406.15786
0
0

Abstract
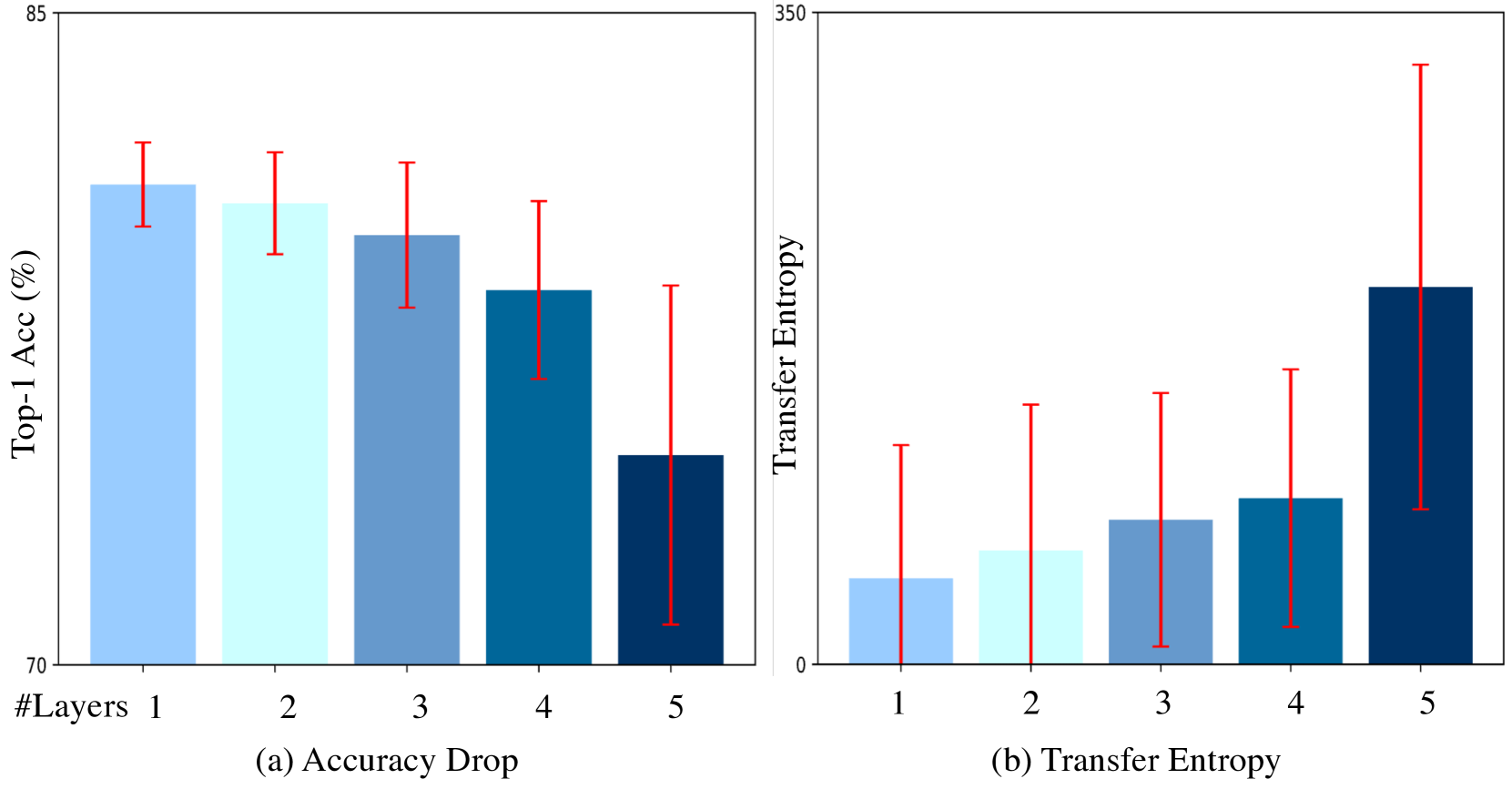
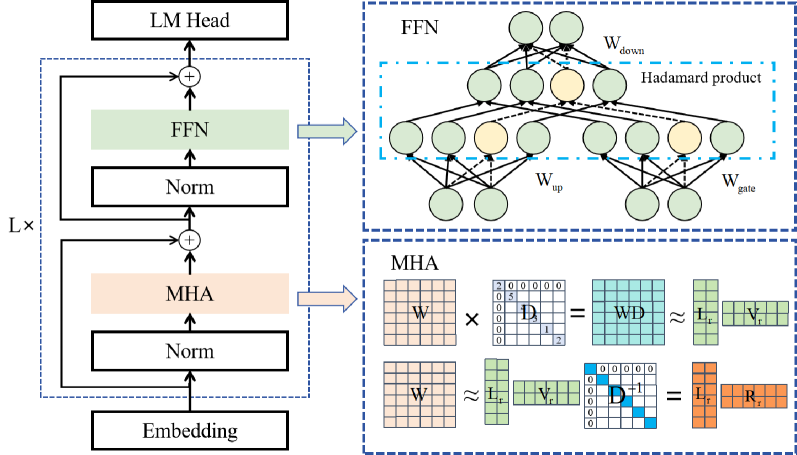
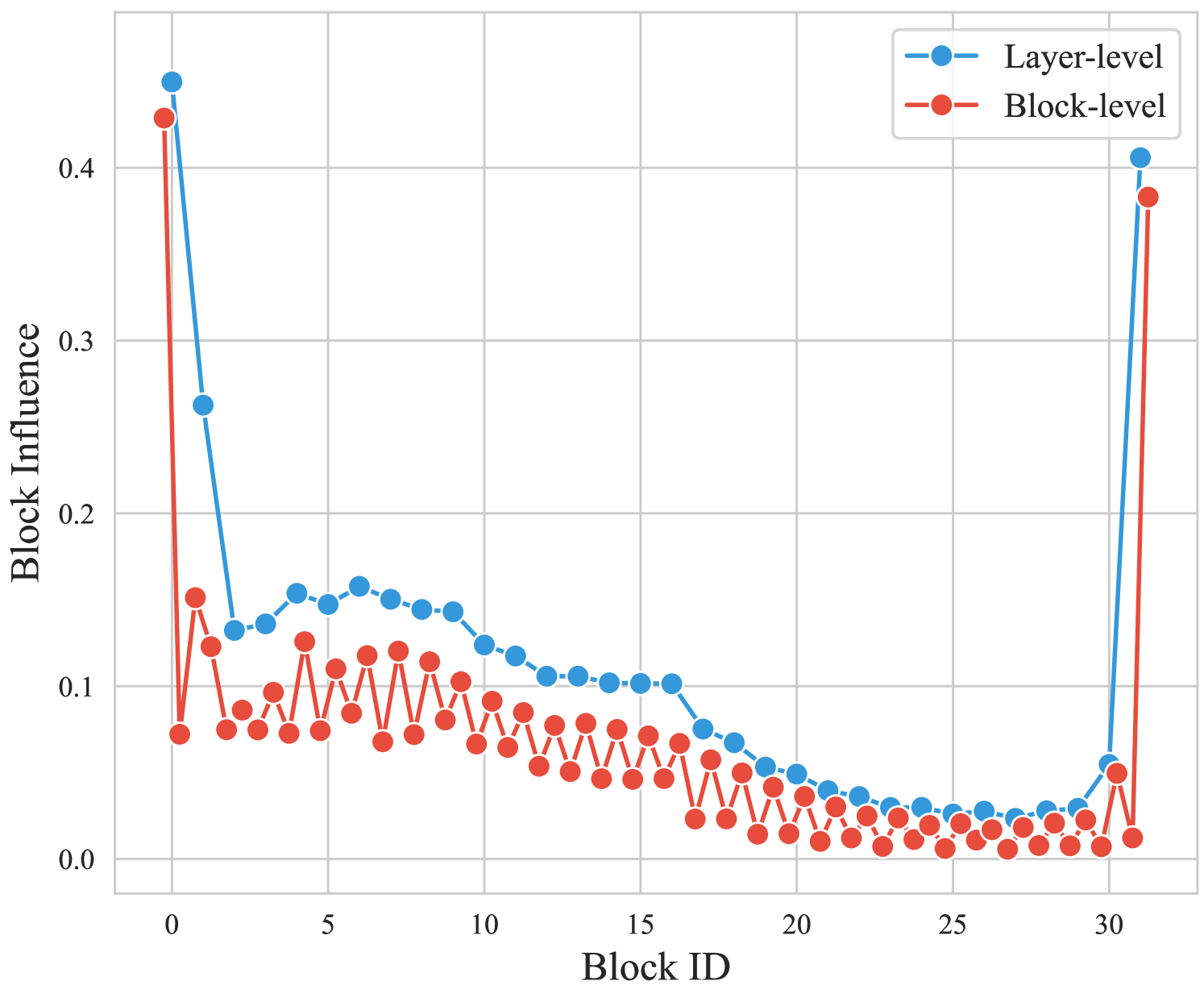
Scaling Transformer-based large language models (LLMs) has demonstrated promising performance across various tasks. However, this scaling also introduces redundant structures, posing challenges for real-world deployment. Despite some recognition of redundancy in LLMs, the variability of redundancy across different structures, such as MLP and Attention layers, is under-explored. In this work, we investigate the varying redundancy across different modules within Transformers, including Blocks, MLP, and Attention layers, using a similarity-based metric. This metric operates on the premise that redundant structures produce outputs highly similar to their inputs. Surprisingly, while attention layers are essential for transformers and distinguish them from other mainstream architectures, we found that a large proportion of attention layers exhibit excessively high similarity and can be safely pruned without degrading performance, leading to reduced memory and computation costs. Additionally, we further propose a method that jointly drops Attention and MLP layers, achieving improved performance and dropping ratios. Extensive experiments demonstrate the effectiveness of our methods, e.g., Llama-3-70B maintains comparable performance even after pruning half of the attention layers. Our findings provide valuable insights for future network architecture design. The code will be released at: url{https://github.com/Shwai-He/LLM-Drop}.
Create account to get full access
Overview
- The paper investigates the importance of different attention mechanisms in Transformer models, a type of neural network architecture widely used in natural language processing tasks.
- The authors explore the hypothesis that not all attention layers are equally critical for the model's performance, and that some layers can be pruned or simplified without significantly impacting the model's accuracy.
- The paper presents a detailed analysis and experimental results that support this hypothesis, providing insights into the inner workings of Transformer models and potential strategies for improving their efficiency.
Plain English Explanation
Transformer models have become very popular in recent years for tasks like language understanding and generation. These models use a special mechanism called "attention" to help them understand the relationships between different parts of the input.
The authors of this paper wondered if all the attention layers in a Transformer model are really necessary. They hypothesized that some attention layers might be more important than others, and that the model could still perform well even if some attention layers were removed or simplified.
To test this, the researchers conducted a series of experiments where they modified the attention layers in different ways and measured the model's performance. They found that, indeed, not all attention layers are equally important. Some layers could be removed or simplified without causing a big drop in the model's accuracy.
This is an important finding because it suggests that Transformer models might be able to be made more efficient and faster, without sacrificing too much performance. By focusing on the most important attention layers and pruning the less important ones, the models could become smaller and run more quickly, which could be useful in real-world applications.
The paper provides valuable insights into the inner workings of Transformer models and opens up new avenues for research and development in this important area of machine learning.
Technical Explanation
The paper presents a detailed analysis of the role and importance of different attention layers in Transformer models. The authors hypothesize that not all attention layers are equally critical for the model's performance, and that some layers can be pruned or simplified without significantly impacting the model's accuracy.
To test this hypothesis, the researchers conduct a series of experiments on various Transformer-based models, including MLP-Can-Be-Good-Transformer-Learner, LoRaP, and BlockPruner. They explore different strategies for modifying the attention layers, such as attention-as-hypernetwork and skip-layer-attention, and measure the impact on the model's performance.
The results of the experiments show that, indeed, not all attention layers are equally important. The researchers find that certain attention layers can be removed or simplified without a significant drop in the model's accuracy, while other layers are more critical for the model's performance.
These findings have important implications for the design and optimization of Transformer models. By identifying the most important attention layers and focusing on them, it may be possible to create more efficient and faster Transformer-based models, which could be beneficial for real-world applications where computational resources and latency are important considerations.
Critical Analysis
The paper provides a thorough and well-designed study on the importance of attention layers in Transformer models. The authors acknowledge the limitations of their work, noting that the optimal configuration of attention layers may vary depending on the specific task and dataset.
One potential area for further research could be to investigate the relationship between the input data characteristics and the importance of different attention layers. It's possible that certain types of data or tasks may require a different attention layer configuration than others.
Additionally, the authors focus primarily on pruning or simplifying attention layers, but there may be other strategies for improving Transformer efficiency, such as attention-as-hypernetwork or skip-layer-attention. Exploring a wider range of optimization techniques could further enhance the capabilities of Transformer models.
Overall, the paper presents a valuable contribution to the understanding of Transformer models and opens up new avenues for research and development in this important area of machine learning.
Conclusion
The key takeaway from this paper is that not all attention layers in Transformer models are equally important for the model's performance. The authors' experiments demonstrate that certain attention layers can be pruned or simplified without a significant impact on the model's accuracy, suggesting that Transformer models can be made more efficient and faster without sacrificing too much performance.
These findings have important implications for the design and optimization of Transformer-based models, particularly in real-world applications where computational resources and latency are important considerations. By focusing on the most critical attention layers and streamlining the less important ones, researchers and engineers can develop more efficient and practical Transformer models that can be deployed in a wider range of scenarios.
The paper's insights into the inner workings of Transformer models also contribute to our broader understanding of this important neural network architecture, paving the way for further advancements in natural language processing and other domains where Transformers have become essential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MLP Can Be A Good Transformer Learner
Sihao Lin, Pumeng Lyu, Dongrui Liu, Tao Tang, Xiaodan Liang, Andy Song, Xiaojun Chang
0
0
Self-attention mechanism is the key of the Transformer but often criticized for its computation demands. Previous token pruning works motivate their methods from the view of computation redundancy but still need to load the full network and require same memory costs. This paper introduces a novel strategy that simplifies vision transformers and reduces computational load through the selective removal of non-essential attention layers, guided by entropy considerations. We identify that regarding the attention layer in bottom blocks, their subsequent MLP layers, i.e. two feed-forward layers, can elicit the same entropy quantity. Meanwhile, the accompanied MLPs are under-exploited since they exhibit smaller feature entropy compared to those MLPs in the top blocks. Therefore, we propose to integrate the uninformative attention layers into their subsequent counterparts by degenerating them into identical mapping, yielding only MLP in certain transformer blocks. Experimental results on ImageNet-1k show that the proposed method can remove 40% attention layer of DeiT-B, improving throughput and memory bound without performance compromise. Code is available at https://github.com/sihaoevery/lambda_vit.
4/9/2024
LoRAP: Transformer Sub-Layers Deserve Differentiated Structured Compression for Large Language Models
Guangyan Li, Yongqiang Tang, Wensheng Zhang
0
0
Large language models (LLMs) show excellent performance in difficult tasks, but they often require massive memories and computational resources. How to reduce the parameter scale of LLMs has become research hotspots. In this study, we make an important observation that the multi-head self-attention (MHA) sub-layer of Transformer exhibits noticeable low-rank structure, while the feed-forward network (FFN) sub-layer does not. With this regard, we design a mixed compression model, which organically combines Low-Rank matrix approximation And structured Pruning (LoRAP). For the MHA sub-layer, we propose an input activation weighted singular value decomposition method to strengthen the low-rank characteristic. Furthermore, we discover that the weight matrices in MHA sub-layer have different low-rank degrees. Thus, a novel parameter allocation scheme according to the discrepancy of low-rank degrees is devised. For the FFN sub-layer, we propose a gradient-free structured channel pruning method. During the pruning, we get an interesting finding that the least important 1% of parameter actually play a vital role in model performance. Extensive evaluations on zero-shot perplexity and zero-shot task classification indicate that our proposal is superior to previous structured compression rivals under multiple compression ratios.
4/16/2024
BlockPruner: Fine-grained Pruning for Large Language Models
Longguang Zhong, Fanqi Wan, Ruijun Chen, Xiaojun Quan, Liangzhi Li
0
0
With the rapid growth in the size and complexity of large language models (LLMs), the costs associated with their training and inference have escalated significantly. Research indicates that certain layers in LLMs harbor substantial redundancy, and pruning these layers has minimal impact on the overall performance. While various layer pruning methods have been developed based on this insight, they generally overlook the finer-grained redundancies within the layers themselves. In this paper, we delve deeper into the architecture of LLMs and demonstrate that finer-grained pruning can be achieved by targeting redundancies in multi-head attention (MHA) and multi-layer perceptron (MLP) blocks. We propose a novel, training-free structured pruning approach called BlockPruner. Unlike existing layer pruning methods, BlockPruner segments each Transformer layer into MHA and MLP blocks. It then assesses the importance of these blocks using perplexity measures and applies a heuristic search for iterative pruning. We applied BlockPruner to LLMs of various sizes and architectures and validated its performance across a wide range of downstream tasks. Experimental results show that BlockPruner achieves more granular and effective pruning compared to state-of-the-art baselines.
6/21/2024
🖼️
Attention as a Hypernetwork
Simon Schug, Seijin Kobayashi, Yassir Akram, Jo~ao Sacramento, Razvan Pascanu
0
0
Transformers can under some circumstances generalize to novel problem instances whose constituent parts might have been encountered during training but whose compositions have not. What mechanisms underlie this ability for compositional generalization? By reformulating multi-head attention as a hypernetwork, we reveal that a low-dimensional latent code specifies key-query specific operations. We find empirically that this latent code is highly structured, capturing information about the subtasks performed by the network. Using the framework of attention as a hypernetwork we further propose a simple modification of multi-head linear attention that strengthens the ability for compositional generalization on a range of abstract reasoning tasks. In particular, we introduce a symbolic version of the Raven Progressive Matrices human intelligence test on which we demonstrate how scaling model size and data enables compositional generalization and gives rise to a functionally structured latent code in the transformer.
6/24/2024