Cross-domain Open-world Discovery

0
Sign in to get full access
Overview
- This paper introduces a novel approach for cross-domain open-world discovery, which aims to identify and understand new concepts that may emerge in different domains.
- The proposed method leverages a combination of prototypical learning and open-set classification to enable the discovery and categorization of unknown concepts.
- The researchers evaluate their approach on several benchmark datasets, demonstrating its effectiveness in identifying and characterizing new concepts across distinct domains.
Plain English Explanation
The researchers have developed a system that can discover and understand new concepts that arise in different areas or "domains." This is an important challenge because the world is constantly changing, and new things are always emerging that we need to be able to recognize and make sense of.
The key idea is to use a combination of two machine learning techniques: prototypical learning and open-set classification. Prototypical learning helps the system learn what the core or "prototype" characteristics of known concepts are. Open-set classification then allows the system to identify when something new and unknown is encountered, rather than just trying to force it into one of the known categories.
By using these complementary approaches, the system can not only recognize new concepts, but also start to understand what those new concepts are and how they relate to the things it already knows about. The researchers tested this system on several different datasets, showing that it is effective at discovering and characterizing novel concepts across a range of domains.
This work is significant because it represents an important step towards building AI systems that can adaptively learn about the world, rather than being limited to only what they were initially trained on. As the world continues to evolve, this type of open-world discovery will become increasingly crucial for developing truly intelligent and capable AI assistants.
Technical Explanation
The paper introduces a novel approach for Cross-domain Open-world Discovery, which aims to identify and understand new concepts that may emerge in different domains. The proposed method leverages a combination of Prototypical Learning and Open-set Classification to enable the discovery and categorization of unknown concepts.
Specifically, the system first learns prototypical representations of known concepts through a meta-learning process. This allows the model to capture the core characteristics of each concept, which can then be used to recognize similar instances. The open-set classification component then enables the model to identify when an input does not match any of the known prototypes, indicating the presence of a novel concept.
When a new concept is detected, the system attempts to understand its relationship to the known concepts by measuring its similarity to the learned prototypes. This provides a way to categorize the new concept and integrate it into the system's understanding. The researchers evaluate their approach on several benchmark datasets, demonstrating its effectiveness in identifying and characterizing new concepts across distinct domains.
Critical Analysis
The paper presents a compelling approach to the challenge of open-world discovery, leveraging a combination of state-of-the-art techniques in an innovative way. However, the authors acknowledge some limitations to their work.
One key concern is the potential for the system to become overwhelmed as the number of known concepts grows, making it increasingly difficult to efficiently learn new prototypes and perform accurate open-set classification. Domain Generalization techniques may be needed to address this scalability issue.
Additionally, the current system relies on a fixed set of known concepts, whereas in a truly open-world setting, the set of known concepts should be dynamic and continuously evolving. Further research is needed to develop methods that can seamlessly incorporate new concepts over time, without requiring a complete retraining of the model.
Finally, while the experiments demonstrate the system's effectiveness on benchmark datasets, its performance in real-world, uncontrolled environments remains to be seen. Factors such as noisy or incomplete data, adversarial attacks, and changing data distributions could pose significant challenges that would need to be addressed.
Conclusion
The proposed approach for Cross-domain Open-world Discovery represents an important step towards building AI systems that can adaptively learn about the world, rather than being limited to only what they were initially trained on. By combining prototypical learning and open-set classification, the system can effectively identify and characterize new concepts as they emerge across different domains.
As the world continues to evolve, this type of open-world discovery will become increasingly crucial for developing truly intelligent and capable AI assistants that can keep up with the changing environment. While the current work has some limitations, the researchers have laid the groundwork for further advancements in this direction, with the potential to significantly impact the field of machine learning and artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cross-domain Open-world Discovery
Shuo Wen, Maria Brbic
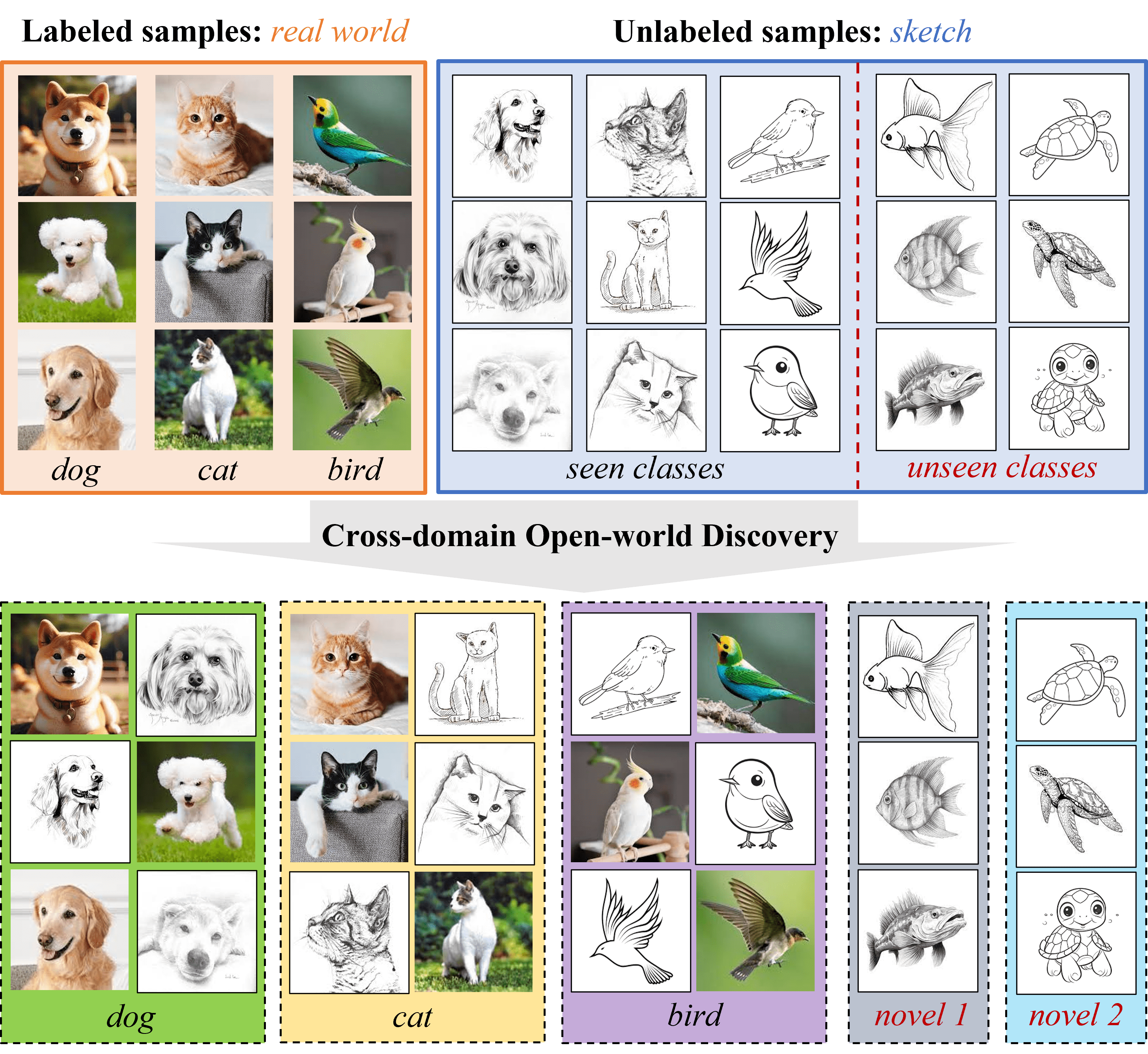
In many real-world applications, test data may commonly exhibit categorical shifts, characterized by the emergence of novel classes, as well as distribution shifts arising from feature distributions different from the ones the model was trained on. However, existing methods either discover novel classes in the open-world setting or assume domain shifts without the ability to discover novel classes. In this work, we consider a cross-domain open-world discovery setting, where the goal is to assign samples to seen classes and discover unseen classes under a domain shift. To address this challenging problem, we present CROW, a prototype-based approach that introduces a cluster-then-match strategy enabled by a well-structured representation space of foundation models. In this way, CROW discovers novel classes by robustly matching clusters with previously seen classes, followed by fine-tuning the representation space using an objective designed for cross-domain open-world discovery. Extensive experimental results on image classification benchmark datasets demonstrate that CROW outperforms alternative baselines, achieving an 8% average performance improvement across 75 experimental settings.
Read more6/18/2024

0
Cross-domain-aware Worker Selection with Training for Crowdsourced Annotation
Yushi Sun, Jiachuan Wang, Peng Cheng, Libin Zheng, Lei Chen, Jian Yin
Annotation through crowdsourcing draws incremental attention, which relies on an effective selection scheme given a pool of workers. Existing methods propose to select workers based on their performance on tasks with ground truth, while two important points are missed. 1) The historical performances of workers in other tasks. In real-world scenarios, workers need to solve a new task whose correlation with previous tasks is not well-known before the training, which is called cross-domain. 2) The dynamic worker performance as workers will learn from the ground truth. In this paper, we consider both factors in designing an allocation scheme named cross-domain-aware worker selection with training approach. Our approach proposes two estimation modules to both statistically analyze the cross-domain correlation and simulate the learning gain of workers dynamically. A framework with a theoretical analysis of the worker elimination process is given. To validate the effectiveness of our methods, we collect two novel real-world datasets and generate synthetic datasets. The experiment results show that our method outperforms the baselines on both real-world and synthetic datasets.
Read more6/12/2024

0
New!Open-World Test-Time Training: Self-Training with Contrast Learning
Houcheng Su, Mengzhu Wang, Jiao Li, Bingli Wang, Daixian Liu, Zeheng Wang
Traditional test-time training (TTT) methods, while addressing domain shifts, often assume a consistent class set, limiting their applicability in real-world scenarios characterized by infinite variety. Open-World Test-Time Training (OWTTT) addresses the challenge of generalizing deep learning models to unknown target domain distributions, especially in the presence of strong Out-of-Distribution (OOD) data. Existing TTT methods often struggle to maintain performance when confronted with strong OOD data. In OWTTT, the focus has predominantly been on distinguishing between overall strong and weak OOD data. However, during the early stages of TTT, initial feature extraction is hampered by interference from strong OOD and corruptions, resulting in diminished contrast and premature classification of certain classes as strong OOD. To address this, we introduce Open World Dynamic Contrastive Learning (OWDCL), an innovative approach that utilizes contrastive learning to augment positive sample pairs. This strategy not only bolsters contrast in the early stages but also significantly enhances model robustness in subsequent stages. In comparison datasets, our OWDCL model has produced the most advanced performance.
Read more9/17/2024

0
POWN: Prototypical Open-World Node Classification
Marcel Hoffmann, Lukas Galke, Ansgar Scherp
We consider the problem of textit{true} open-world semi-supervised node classification, in which nodes in a graph either belong to known or new classes, with the latter not present during training. Existing methods detect and reject new classes but fail to distinguish between different new classes. We adapt existing methods and show they do not solve the problem sufficiently. We introduce a novel end-to-end approach for classification into known classes and new classes based on class prototypes, which we call Prototypical Open-World Learning for Node Classification (POWN). Our method combines graph semi-supervised learning, self-supervised learning, and pseudo-labeling to learn prototype representations of new classes in a zero-shot way. In contrast to existing solutions from the vision domain, POWN does not require data augmentation techniques for node classification. Experiments on benchmark datasets demonstrate the effectiveness of POWN, where it outperforms baselines by up to $20%$ accuracy on the small and up to $30%$ on the large datasets. Source code is available at https://github.com/Bobowner/POWN.
Read more6/17/2024