Cross-domain-aware Worker Selection with Training for Crowdsourced Annotation

0

Sign in to get full access
Overview
- This paper presents a novel approach for selecting workers and providing training in the context of crowdsourced annotation tasks.
- The key focus is on addressing the challenges of cross-domain crowdsourcing, where workers may have expertise in different domains than the task at hand.
- The proposed method aims to improve the quality and efficiency of crowdsourced annotations by carefully selecting workers and providing them with targeted training.
Plain English Explanation
When companies or researchers need large amounts of data annotated, they often turn to crowdsourcing platforms where many people can contribute. However, the quality of the annotations can vary greatly, especially when the workers have expertise in different domains than the task at hand.
This paper introduces a new approach to address this challenge. The researchers developed a method that carefully selects the most suitable workers for a given annotation task, and then provides them with targeted training to improve their performance.
The key idea is to consider the workers' existing knowledge and skills, and match them to the specific requirements of the annotation task. By doing this, the researchers can identify workers who are more likely to provide high-quality annotations, even if their expertise is in a different domain.
The training component then helps these workers quickly get up to speed on the task at hand, further improving the quality and consistency of the crowdsourced annotations. This approach aims to make crowdsourcing more effective, efficient, and reliable, even for complex tasks that require specialized knowledge.
Technical Explanation
The paper proposes a "Cross-domain-aware Worker Selection with Training" (CWST) framework for crowdsourced annotation tasks. The main components of this framework are:
-
Worker Selection: The method first evaluates each worker's existing knowledge and skills, and then selects the most suitable workers for the given annotation task. This is done by modeling the worker's domain expertise using a cross-domain aware worker model.
-
Worker Training: The selected workers are then provided with targeted training to improve their performance on the specific annotation task. The training is designed to quickly bring workers up to speed on the task requirements, even if their expertise is in a different domain.
The researchers evaluated their CWST framework on several crowdsourced annotation tasks, including image classification and text sentiment analysis. The results showed that CWST outperformed traditional crowdsourcing approaches in terms of annotation quality and efficiency.
One key insight from the paper is the importance of considering cross-domain expertise when selecting workers. By matching workers' skills to the task requirements, the researchers were able to identify and utilize workers who may not have direct experience in the task domain, but could still contribute high-quality annotations with the right training.
Critical Analysis
The paper presents a well-designed and thorough approach to addressing the challenges of cross-domain crowdsourcing. The researchers have clearly identified an important problem and have proposed a novel solution that leverages worker selection and targeted training.
One potential limitation of the research is the reliance on self-reported worker expertise, which may not always accurately reflect their actual capabilities. The researchers acknowledge this and suggest exploring more objective methods of assessing worker skills in future work.
Additionally, the paper does not provide much detail on the specific training content and delivery methods used. Further research could explore different training approaches and their impact on worker performance.
Overall, the CWST framework represents a significant advancement in the field of crowdsourced annotation, and the insights from this research could be valuable for anyone looking to improve the quality and efficiency of their crowdsourcing efforts.
Conclusion
This paper introduces a novel approach for selecting and training workers in the context of crowdsourced annotation tasks. By considering the cross-domain expertise of workers and providing them with targeted training, the researchers were able to improve the quality and efficiency of the crowdsourced annotations.
The key contribution of this work is the recognition that traditional crowdsourcing methods may not be well-suited for complex tasks that require specialized knowledge. The CWST framework offers a solution by carefully matching workers to the task requirements and equipping them with the necessary skills.
The insights from this research could have wide-ranging implications for various industries and research domains that rely on crowdsourced data, such as machine learning model development, self-supervised learning, data allocation, and noise correction in subjective datasets. By improving the quality and consistency of crowdsourced annotations, the CWST framework could also contribute to more robust and reliable crowdsourcing systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cross-domain-aware Worker Selection with Training for Crowdsourced Annotation
Yushi Sun, Jiachuan Wang, Peng Cheng, Libin Zheng, Lei Chen, Jian Yin
Annotation through crowdsourcing draws incremental attention, which relies on an effective selection scheme given a pool of workers. Existing methods propose to select workers based on their performance on tasks with ground truth, while two important points are missed. 1) The historical performances of workers in other tasks. In real-world scenarios, workers need to solve a new task whose correlation with previous tasks is not well-known before the training, which is called cross-domain. 2) The dynamic worker performance as workers will learn from the ground truth. In this paper, we consider both factors in designing an allocation scheme named cross-domain-aware worker selection with training approach. Our approach proposes two estimation modules to both statistically analyze the cross-domain correlation and simulate the learning gain of workers dynamically. A framework with a theoretical analysis of the worker elimination process is given. To validate the effectiveness of our methods, we collect two novel real-world datasets and generate synthetic datasets. The experiment results show that our method outperforms the baselines on both real-world and synthetic datasets.
Read more6/12/2024
📊
0
Cost-efficient Crowdsourcing for Span-based Sequence Labeling: Worker Selection and Data Augmentation
Yujie Wang, Chao Huang, Liner Yang, Zhixuan Fang, Yaping Huang, Yang Liu, Jingsi Yu, Erhong Yang
This paper introduces a novel crowdsourcing worker selection algorithm, enhancing annotation quality and reducing costs. Unlike previous studies targeting simpler tasks, this study contends with the complexities of label interdependencies in sequence labeling. The proposed algorithm utilizes a Combinatorial Multi-Armed Bandit (CMAB) approach for worker selection, and a cost-effective human feedback mechanism. The challenge of dealing with imbalanced and small-scale datasets, which hinders offline simulation of worker selection, is tackled using an innovative data augmentation method termed shifting, expanding, and shrinking (SES). Rigorous testing on CoNLL 2003 NER and Chinese OEI datasets showcased the algorithm's efficiency, with an increase in F1 score up to 100.04% of the expert-only baseline, alongside cost savings up to 65.97%. The paper also encompasses a dataset-independent test emulating annotation evaluation through a Bernoulli distribution, which still led to an impressive 97.56% F1 score of the expert baseline and 59.88% cost savings. Furthermore, our approach can be seamlessly integrated into Reinforcement Learning from Human Feedback (RLHF) systems, offering a cost-effective solution for obtaining human feedback.
Read more7/30/2024
0
Cross-domain Open-world Discovery
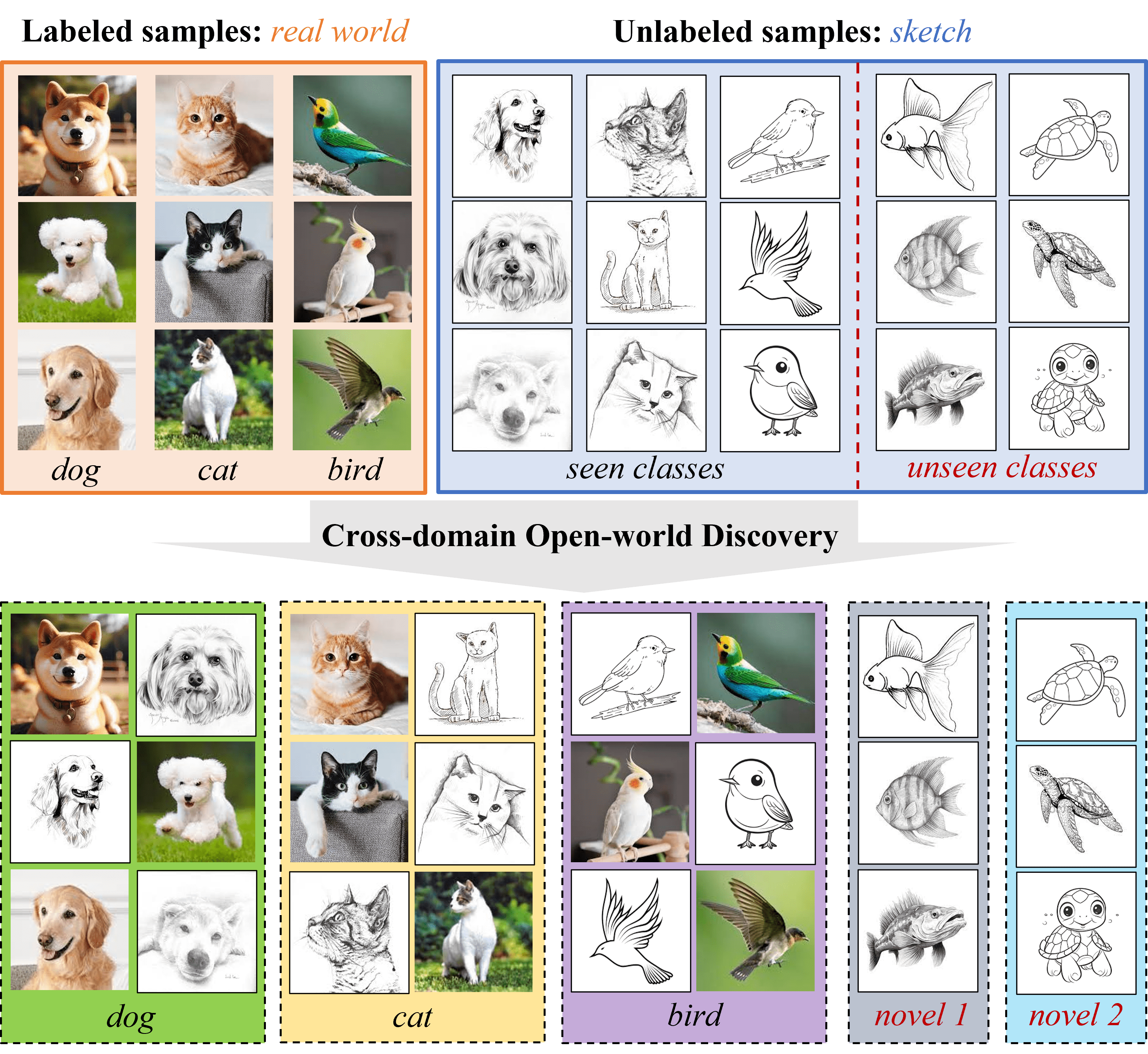
Shuo Wen, Maria Brbic
In many real-world applications, test data may commonly exhibit categorical shifts, characterized by the emergence of novel classes, as well as distribution shifts arising from feature distributions different from the ones the model was trained on. However, existing methods either discover novel classes in the open-world setting or assume domain shifts without the ability to discover novel classes. In this work, we consider a cross-domain open-world discovery setting, where the goal is to assign samples to seen classes and discover unseen classes under a domain shift. To address this challenging problem, we present CROW, a prototype-based approach that introduces a cluster-then-match strategy enabled by a well-structured representation space of foundation models. In this way, CROW discovers novel classes by robustly matching clusters with previously seen classes, followed by fine-tuning the representation space using an objective designed for cross-domain open-world discovery. Extensive experimental results on image classification benchmark datasets demonstrate that CROW outperforms alternative baselines, achieving an 8% average performance improvement across 75 experimental settings.
Read more6/18/2024
0
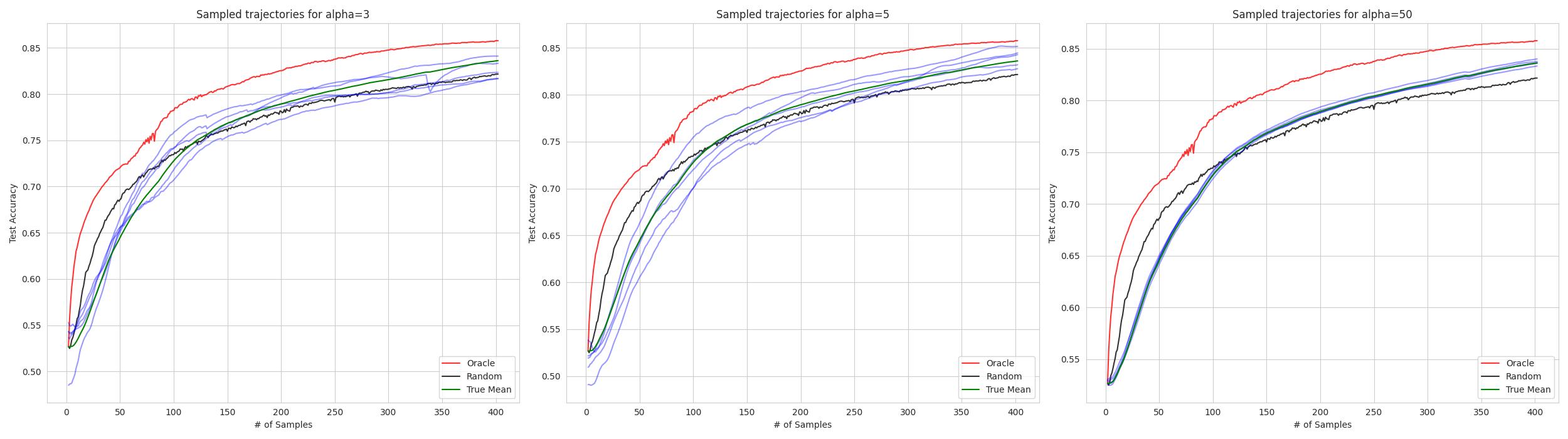
A Cross-Domain Benchmark for Active Learning
Thorben Werner, Johannes Burchert, Maximilian Stubbemann, Lars Schmidt-Thieme
Active Learning (AL) deals with identifying the most informative samples for labeling to reduce data annotation costs for supervised learning tasks. AL research suffers from the fact that lifts from literature generalize poorly and that only a small number of repetitions of experiments are conducted. To overcome these obstacles, we propose emph{CDALBench}, the first active learning benchmark which includes tasks in computer vision, natural language processing and tabular learning. Furthermore, by providing an efficient, greedy oracle, emph{CDALBench} can be evaluated with 50 runs for each experiment. We show, that both the cross-domain character and a large amount of repetitions are crucial for sophisticated evaluation of AL research. Concretely, we show that the superiority of specific methods varies over the different domains, making it important to evaluate Active Learning with a cross-domain benchmark. Additionally, we show that having a large amount of runs is crucial. With only conducting three runs as often done in the literature, the superiority of specific methods can strongly vary with the specific runs. This effect is so strong, that, depending on the seed, even a well-established method's performance can be significantly better and significantly worse than random for the same dataset.
Read more8/2/2024