Cross-Input Certified Training for Universal Perturbations

0

Sign in to get full access
Overview
- This paper presents a novel approach called Cross-Input Certified Training (CICT) for training neural networks to be robust against universal adversarial perturbations.
- Universal adversarial perturbations are small changes to the input that can cause a model to misclassify multiple images across different classes.
- The proposed CICT method aims to train models that are certified to be robust against such universal perturbations, ensuring reliable performance even in the face of adversarial attacks.
Plain English Explanation
The paper explores a technique called Cross-Input Certified Training (CICT) that helps neural networks become more robust against a particular type of attack known as "universal adversarial perturbations." These are small, carefully crafted changes to the input that can cause a model to misclassify multiple images across different classes.
The key idea behind CICT is to train the model in a way that ensures it will make the correct prediction, even if the input is slightly altered by these universal adversarial perturbations. This is done by exposing the model to a diverse set of possible perturbations during the training process, so that it learns to be resilient to a wide range of such attacks.
By making the model "certified" to be robust against universal perturbations, the researchers aim to improve the reliability and trustworthiness of these AI systems, ensuring they perform well even in the face of adversarial attempts to mislead or confuse them. This is an important consideration, as neural networks have been shown to be susceptible to such universal perturbations that can undermine their performance in real-world applications.
Technical Explanation
The paper introduces a novel training method called Cross-Input Certified Training (CICT) that aims to make neural networks robust against universal adversarial perturbations. These are small, imperceptible changes to the input that can cause a model to misclassify multiple images across different classes, as demonstrated in prior research on the susceptibility of neural networks to such universal perturbations.
The CICT approach works by exposing the model to a diverse set of possible perturbations during the training process, ensuring that it learns to make the correct prediction even when the input is slightly altered. This is achieved by optimizing the model's parameters to minimize a cross-input adversarial loss, which encourages the model to be robust against a wide range of universal perturbations.
The authors demonstrate the effectiveness of CICT through extensive experiments on both image classification and natural language processing tasks. They show that models trained using CICT achieve superior robust performance against data-label perturbations compared to standard training methods, while also maintaining high clean accuracy.
The paper also discusses the double-edged sword of input perturbations and proposes an error-driven uncertainty-aware training approach to further improve the robustness of the CICT-trained models.
Critical Analysis
The paper presents a promising approach to addressing the issue of universal adversarial perturbations, which is a significant challenge in the field of machine learning and AI safety. The CICT method is well-designed and backed by a solid theoretical foundation, as well as empirical evidence demonstrating its effectiveness.
One potential limitation of the CICT approach is that it may require a more computationally intensive training process compared to standard training methods, as the model needs to be optimized against a diverse set of possible perturbations. This could make CICT less practical for certain applications with strict computational constraints.
Additionally, the paper does not address the potential for the CICT-trained models to be vulnerable to other types of adversarial attacks, such as targeted or adaptive perturbations. Further research may be needed to assess the broader robustness of the CICT approach and its applicability to different attack scenarios.
Overall, the CICT method presented in this paper is a valuable contribution to the field of adversarial machine learning, and the insights gained from this work could inspire future research on improving the robustness and reliability of neural networks in the face of increasingly sophisticated adversarial threats.
Conclusion
The paper introduces a novel training approach called Cross-Input Certified Training (CICT) that aims to make neural networks robust against universal adversarial perturbations. These are small, imperceptible changes to the input that can cause a model to misclassify multiple images across different classes, as demonstrated in prior research on the susceptibility of neural networks to such universal perturbations.
The CICT method works by exposing the model to a diverse set of possible perturbations during the training process, ensuring that it learns to make the correct prediction even when the input is slightly altered. The authors show that CICT-trained models achieve superior robust performance against data-label perturbations while maintaining high clean accuracy.
This work represents an important step towards improving the reliability and trustworthiness of AI systems, as they become more resilient to adversarial attacks that seek to undermine their performance. By addressing the challenge of universal adversarial perturbations, the CICT approach could have significant implications for the real-world deployment of machine learning models in safety-critical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cross-Input Certified Training for Universal Perturbations
Changming Xu, Gagandeep Singh
Existing work in trustworthy machine learning primarily focuses on single-input adversarial perturbations. In many real-world attack scenarios, input-agnostic adversarial attacks, e.g. universal adversarial perturbations (UAPs), are much more feasible. Current certified training methods train models robust to single-input perturbations but achieve suboptimal clean and UAP accuracy, thereby limiting their applicability in practical applications. We propose a novel method, CITRUS, for certified training of networks robust against UAP attackers. We show in an extensive evaluation across different datasets, architectures, and perturbation magnitudes that our method outperforms traditional certified training methods on standard accuracy (up to 10.3%) and achieves SOTA performance on the more practical certified UAP accuracy metric.
Read more9/10/2024
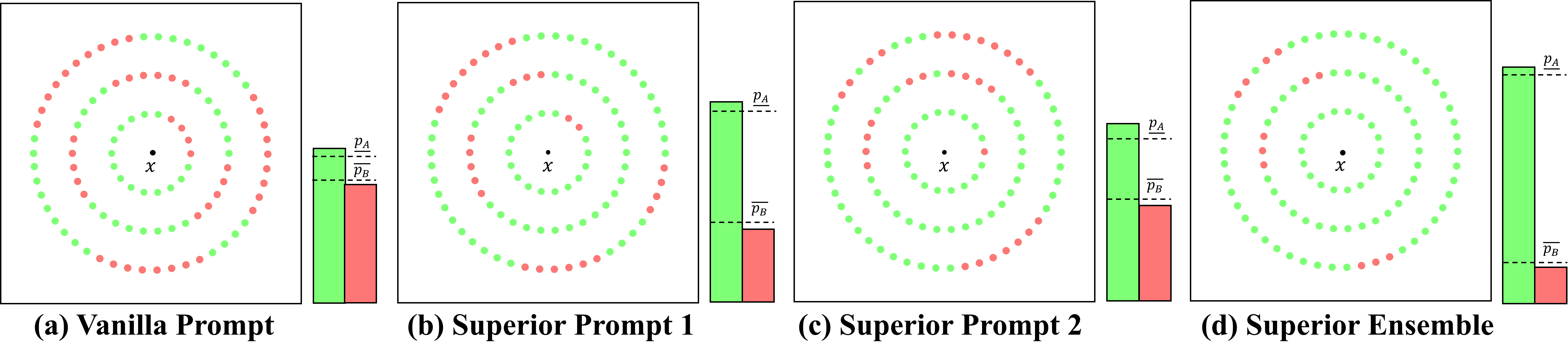
0
CR-UTP: Certified Robustness against Universal Text Perturbations
Qian Lou, Xin Liang, Jiaqi Xue, Yancheng Zhang, Rui Xie, Mengxin Zheng
It is imperative to ensure the stability of every prediction made by a language model; that is, a language's prediction should remain consistent despite minor input variations, like word substitutions. In this paper, we investigate the problem of certifying a language model's robustness against Universal Text Perturbations (UTPs), which have been widely used in universal adversarial attacks and backdoor attacks. Existing certified robustness based on random smoothing has shown considerable promise in certifying the input-specific text perturbations (ISTPs), operating under the assumption that any random alteration of a sample's clean or adversarial words would negate the impact of sample-wise perturbations. However, with UTPs, masking only the adversarial words can eliminate the attack. A naive method is to simply increase the masking ratio and the likelihood of masking attack tokens, but it leads to a significant reduction in both certified accuracy and the certified radius due to input corruption by extensive masking. To solve this challenge, we introduce a novel approach, the superior prompt search method, designed to identify a superior prompt that maintains higher certified accuracy under extensive masking. Additionally, we theoretically motivate why ensembles are a particularly suitable choice as base prompts for random smoothing. The method is denoted by superior prompt ensembling technique. We also empirically confirm this technique, obtaining state-of-the-art results in multiple settings. These methodologies, for the first time, enable high certified accuracy against both UTPs and ISTPs. The source code of CR-UTP is available at url {https://github.com/UCFML-Research/CR-UTP}.
Read more6/6/2024

0
One Perturbation is Enough: On Generating Universal Adversarial Perturbations against Vision-Language Pre-training Models
Hao Fang, Jiawei Kong, Wenbo Yu, Bin Chen, Jiawei Li, Shutao Xia, Ke Xu
Vision-Language Pre-training (VLP) models trained on large-scale image-text pairs have demonstrated unprecedented capability in many practical applications. However, previous studies have revealed that VLP models are vulnerable to adversarial samples crafted by a malicious adversary. While existing attacks have achieved great success in improving attack effect and transferability, they all focus on instance-specific attacks that generate perturbations for each input sample. In this paper, we show that VLP models can be vulnerable to a new class of universal adversarial perturbation (UAP) for all input samples. Although initially transplanting existing UAP algorithms to perform attacks showed effectiveness in attacking discriminative models, the results were unsatisfactory when applied to VLP models. To this end, we revisit the multimodal alignments in VLP model training and propose the Contrastive-training Perturbation Generator with Cross-modal conditions (C-PGC). Specifically, we first design a generator that incorporates cross-modal information as conditioning input to guide the training. To further exploit cross-modal interactions, we propose to formulate the training objective as a multimodal contrastive learning paradigm based on our constructed positive and negative image-text pairs. By training the conditional generator with the designed loss, we successfully force the adversarial samples to move away from its original area in the VLP model's feature space, and thus essentially enhance the attacks. Extensive experiments show that our method achieves remarkable attack performance across various VLP models and Vision-and-Language (V+L) tasks. Moreover, C-PGC exhibits outstanding black-box transferability and achieves impressive results in fooling prevalent large VLP models including LLaVA and Qwen-VL.
Read more6/11/2024
🔎
0
Universal Adversarial Perturbations for Vision-Language Pre-trained Models
Peng-Fei Zhang, Zi Huang, Guangdong Bai
Vision-language pre-trained (VLP) models have been the foundation of numerous vision-language tasks. Given their prevalence, it be- comes imperative to assess their adversarial robustness, especially when deploying them in security-crucial real-world applications. Traditionally, adversarial perturbations generated for this assessment target specific VLP models, datasets, and/or downstream tasks. This practice suffers from low transferability and additional computation costs when transitioning to new scenarios. In this work, we thoroughly investigate whether VLP models are commonly sensitive to imperceptible perturbations of a specific pattern for the image modality. To this end, we propose a novel black-box method to generate Universal Adversarial Perturbations (UAPs), which is so called the Effective and T ransferable Universal Adversarial Attack (ETU), aiming to mislead a variety of existing VLP models in a range of downstream tasks. The ETU comprehensively takes into account the characteristics of UAPs and the intrinsic cross-modal interactions to generate effective UAPs. Under this regime, the ETU encourages both global and local utilities of UAPs. This benefits the overall utility while reducing interactions between UAP units, improving the transferability. To further enhance the effectiveness and transferability of UAPs, we also design a novel data augmentation method named ScMix. ScMix consists of self-mix and cross-mix data transformations, which can effectively increase the multi-modal data diversity while preserving the semantics of the original data. Through comprehensive experiments on various downstream tasks, VLP models, and datasets, we demonstrate that the proposed method is able to achieve effective and transferrable universal adversarial attacks.
Read more5/10/2024