Error-Driven Uncertainty Aware Training

0
Sign in to get full access
Overview
- This paper proposes a novel training approach called "Error-Driven Uncertainty Aware Training" (EDUA) to address the issue of overconfidence in modern uncertainty-aware deep learning models.
- The authors argue that existing uncertainty-aware training methods fail to account for the uncertainty inherent in the training data itself, leading to overly confident model predictions.
- EDUA aims to calibrate the model's uncertainty estimates by incorporating information about the uncertainty in the training data, captured through error-driven uncertainty.
Plain English Explanation
The paper focuses on a common problem in machine learning called "overconfidence." This means that the models we train can become too sure of their own predictions, even when they're not actually very accurate. The authors of this paper believe this happens because the training methods used today don't properly account for the inherent uncertainty in the data used to train the models.
To fix this, the researchers developed a new training approach called "Error-Driven Uncertainty Aware Training" (EDUA). The key idea behind EDUA is to explicitly model the uncertainty in the training data itself, and then use that information to help the model calibrate its own uncertainty estimates. By doing this, the model becomes more aware of when it's uncertain, and less likely to make overconfident predictions.
The authors argue that this is an important problem to solve, as overconfident models can lead to poor decision-making in real-world applications. EDUA aims to be a step towards building more reliable and trustworthy AI systems.
Technical Explanation
The paper introduces the "Error-Driven Uncertainty Aware Training" (EDUA) method, which aims to address the overconfidence issue in modern uncertainty-aware deep learning models. The authors argue that existing uncertainty-aware training approaches, such as Epistemic Uncertainty Quantification and Over-Certainty Phenomenon, fail to account for the inherent uncertainty in the training data itself, leading to overly confident model predictions.
EDUA incorporates information about the uncertainty in the training data, captured through error-driven uncertainty, to calibrate the model's uncertainty estimates. The authors propose a multi-task learning framework where the model simultaneously learns to predict the target variable and estimate the associated uncertainty. This uncertainty estimate is then used to regularize the model, encouraging it to produce well-calibrated uncertainty estimates.
The authors evaluate EDUA on several benchmark datasets and compare its performance to existing uncertainty-aware training methods, as well as standard deterministic models. The results demonstrate that EDUA outperforms the baselines in terms of predictive accuracy and uncertainty calibration, as measured by metrics such as negative log-likelihood and expected calibration error.
Critical Analysis
The paper makes a compelling case for the importance of addressing the overconfidence issue in modern deep learning models, and the proposed EDUA method represents a promising approach to this problem. The authors' argument that existing uncertainty-aware training methods fail to account for the inherent uncertainty in the training data is well-supported and aligns with the findings of related work, such as the Comprehensive Survey on Uncertainty Quantification in Deep Learning.
However, the paper does not provide a thorough discussion of the potential limitations or caveats of the EDUA method. For example, the authors do not address how the method might perform on more complex or noisy datasets, or how it might scale to larger models and datasets. Additionally, the paper lacks a detailed analysis of the computational complexity and training time of the EDUA approach compared to the baselines.
Further research could also explore the applicability of EDUA to other domains, such as Awareness of Uncertainty in Classification Using Multivariate Model, and investigate potential extensions or refinements to the core EDUA methodology.
Conclusion
The "Error-Driven Uncertainty Aware Training" (EDUA) method proposed in this paper represents an important step towards addressing the overconfidence issue in modern deep learning models. By explicitly incorporating information about the uncertainty inherent in the training data, EDUA is able to produce more well-calibrated uncertainty estimates, which can lead to more reliable and trustworthy AI systems.
The technical insights and experimental results presented in the paper suggest that EDUA is a promising approach that merits further exploration and development. As the field of AI continues to advance, addressing the challenge of overconfidence will be crucial for ensuring the safe and responsible deployment of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Error-Driven Uncertainty Aware Training
Pedro Mendes, Paolo Romano, David Garlan
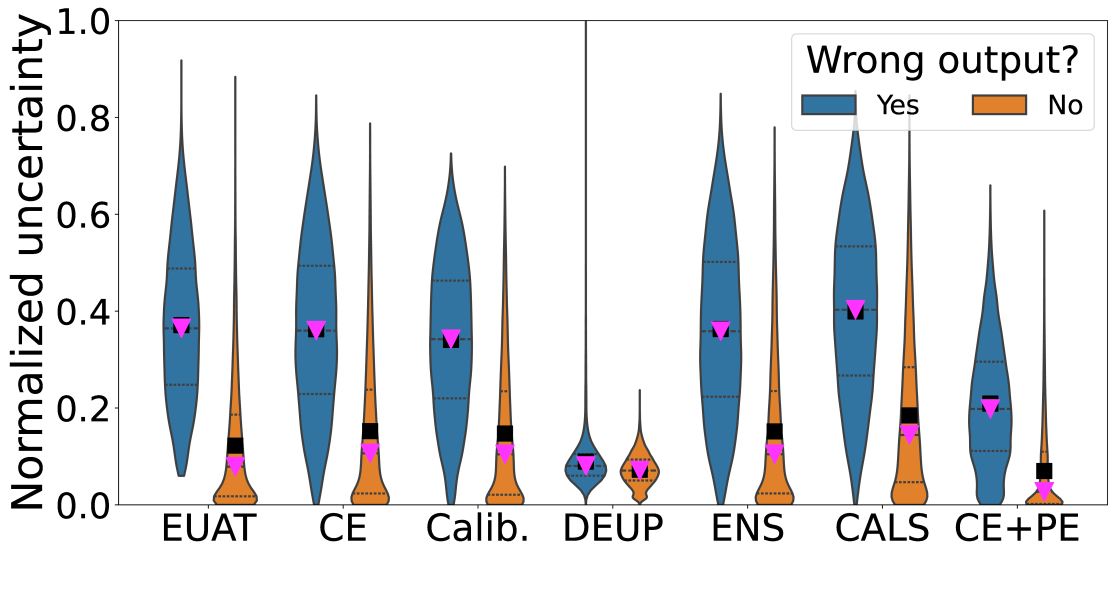
Neural networks are often overconfident about their predictions, which undermines their reliability and trustworthiness. In this work, we present a novel technique, named Error-Driven Uncertainty Aware Training (EUAT), which aims to enhance the ability of neural classifiers to estimate their uncertainty correctly, namely to be highly uncertain when they output inaccurate predictions and low uncertain when their output is accurate. The EUAT approach operates during the model's training phase by selectively employing two loss functions depending on whether the training examples are correctly or incorrectly predicted by the model. This allows for pursuing the twofold goal of i) minimizing model uncertainty for correctly predicted inputs and ii) maximizing uncertainty for mispredicted inputs, while preserving the model's misprediction rate. We evaluate EUAT using diverse neural models and datasets in the image recognition domains considering both non-adversarial and adversarial settings. The results show that EUAT outperforms existing approaches for uncertainty estimation (including other uncertainty-aware training techniques, calibration, ensembles, and DEUP) by providing uncertainty estimates that not only have higher quality when evaluated via statistical metrics (e.g., correlation with residuals) but also when employed to build binary classifiers that decide whether the model's output can be trusted or not and under distributional data shifts.
Read more9/12/2024
🏋️
0
Training of Neural Networks with Uncertain Data -- A Mixture of Experts Approach
Lucas Luttner
This paper introduces the Uncertainty-aware Mixture of Experts (uMoE), a novel solution aimed at addressing aleatoric uncertainty within Neural Network (NN) based predictive models. While existing methodologies primarily concentrate on managing uncertainty during inference, uMoE uniquely embeds uncertainty into the training phase. Employing a Divide and Conquer strategy, uMoE strategically partitions the uncertain input space into more manageable subspaces. It comprises Expert components, individually trained on their respective subspace uncertainties. Overarching the Experts, a Gating Unit, leveraging additional information regarding the distribution of uncertain in-puts across these subspaces, dynamically adjusts the weighting to minimize deviations from ground truth. Our findings demonstrate the superior performance of uMoE over baseline methods in effectively managing data uncertainty. Furthermore, through a comprehensive robustness analysis, we showcase its adaptability to varying uncertainty levels and propose optimal threshold parameters. This innovative approach boasts broad applicability across diverse da-ta-driven domains, including but not limited to biomedical signal processing, autonomous driving, and production quality control.
Read more4/26/2024
🏋️
0
Provable Unrestricted Adversarial Training without Compromise with Generalizability
Lilin Zhang, Ning Yang, Yanchao Sun, Philip S. Yu
Adversarial training (AT) is widely considered as the most promising strategy to defend against adversarial attacks and has drawn increasing interest from researchers. However, the existing AT methods still suffer from two challenges. First, they are unable to handle unrestricted adversarial examples (UAEs), which are built from scratch, as opposed to restricted adversarial examples (RAEs), which are created by adding perturbations bound by an $l_p$ norm to observed examples. Second, the existing AT methods often achieve adversarial robustness at the expense of standard generalizability (i.e., the accuracy on natural examples) because they make a tradeoff between them. To overcome these challenges, we propose a unique viewpoint that understands UAEs as imperceptibly perturbed unobserved examples. Also, we find that the tradeoff results from the separation of the distributions of adversarial examples and natural examples. Based on these ideas, we propose a novel AT approach called Provable Unrestricted Adversarial Training (PUAT), which can provide a target classifier with comprehensive adversarial robustness against both UAE and RAE, and simultaneously improve its standard generalizability. Particularly, PUAT utilizes partially labeled data to achieve effective UAE generation by accurately capturing the natural data distribution through a novel augmented triple-GAN. At the same time, PUAT extends the traditional AT by introducing the supervised loss of the target classifier into the adversarial loss and achieves the alignment between the UAE distribution, the natural data distribution, and the distribution learned by the classifier, with the collaboration of the augmented triple-GAN. Finally, the solid theoretical analysis and extensive experiments conducted on widely-used benchmarks demonstrate the superiority of PUAT.
Read more5/21/2024
🧠
0
Epistemic Uncertainty Quantification For Pre-trained Neural Network
Hanjing Wang, Qiang Ji
Epistemic uncertainty quantification (UQ) identifies where models lack knowledge. Traditional UQ methods, often based on Bayesian neural networks, are not suitable for pre-trained non-Bayesian models. Our study addresses quantifying epistemic uncertainty for any pre-trained model, which does not need the original training data or model modifications and can ensure broad applicability regardless of network architectures or training techniques. Specifically, we propose a gradient-based approach to assess epistemic uncertainty, analyzing the gradients of outputs relative to model parameters, and thereby indicating necessary model adjustments to accurately represent the inputs. We first explore theoretical guarantees of gradient-based methods for epistemic UQ, questioning the view that this uncertainty is only calculable through differences between multiple models. We further improve gradient-driven UQ by using class-specific weights for integrating gradients and emphasizing distinct contributions from neural network layers. Additionally, we enhance UQ accuracy by combining gradient and perturbation methods to refine the gradients. We evaluate our approach on out-of-distribution detection, uncertainty calibration, and active learning, demonstrating its superiority over current state-of-the-art UQ methods for pre-trained models.
Read more4/17/2024