Cross-Lingual Word Alignment for ASEAN Languages with Contrastive Learning

0
🚀
Sign in to get full access
Overview
- Proposes a novel approach to improve cross-lingual word alignment, a crucial task for natural language processing in low-resource languages
- Introduces a BiLSTM-based encoder-decoder model that outperforms pre-trained language models in low-resource settings
- Incorporates contrastive learning to explicitly model the differences between word embeddings in the shared cross-lingual space
- Evaluates the model on five bilingual aligned datasets spanning four ASEAN languages: Lao, Vietnamese, Thai, and Indonesian
- Demonstrates that integrating contrastive learning consistently improves word alignment accuracy in low-resource scenarios
Plain English Explanation
Cross-lingual word alignment is the process of matching words in one language to their equivalent words in another language. This is an important task for natural language processing, especially for languages that have limited resources available, like data and pre-trained models.
The researchers propose a new model that uses a BiLSTM (Bidirectional Long Short-Term Memory) network to encode and decode the words. This model outperforms pre-trained language models in low-resource settings. However, the previous model only considered the similarity between word embeddings, and did not explicitly capture the differences between them.
To address this limitation, the researchers incorporate contrastive learning into the BiLSTM-based encoder-decoder framework. Contrastive learning is a technique that helps the model learn the differences between related and unrelated pairs of things. In this case, the model learns the differences between pairs of words in the shared cross-lingual embedding space.
The researchers evaluate their model on five datasets that align words between four Southeast Asian languages: Lao, Vietnamese, Thai, and Indonesian. The results show that adding the contrastive learning component consistently improves the accuracy of the word alignment, even in these low-resource language scenarios.
The researchers plan to release the dataset and code they used, which will help support future research on word alignment for ASEAN or other low-resource languages.
Technical Explanation
The researchers propose a BiLSTM-based encoder-decoder model for cross-lingual word alignment, which outperforms pre-trained language models in low-resource settings. To further improve the performance, they incorporate contrastive learning into the encoder-decoder framework.
The contrastive learning component introduces a multi-view negative sampling strategy to learn the differences between word pairs in the shared cross-lingual embedding space. This is in contrast to previous approaches that only considered the similarity between word embeddings, without explicitly modeling the differences.
The researchers evaluate their model on five bilingual aligned datasets spanning four ASEAN languages: Lao, Vietnamese, Thai, and Indonesian. These datasets represent low-resource scenarios, where pre-trained models and language resources are limited.
The experimental results demonstrate that integrating contrastive learning consistently improves the word alignment accuracy across all datasets, confirming the effectiveness of the proposed method in low-resource settings. This is a significant contribution, as cross-lingual word alignment plays a crucial role in various natural language processing tasks, particularly for low-resource languages.
Critical Analysis
The researchers acknowledge that their approach is limited to word-level alignment and does not consider contextual information or sentence-level alignment. Future research could explore incorporating contextual learning or sentence-level alignment to further improve the performance of the model.
Additionally, the evaluation is focused on ASEAN languages, which may have unique characteristics and challenges compared to other low-resource language pairs. Expanding the evaluation to a more diverse set of low-resource languages could provide a more comprehensive understanding of the model's capabilities and limitations.
While the researchers plan to release the dataset and code, it would be helpful to see more details on the specific techniques used for contrastive learning and how they were integrated into the BiLSTM-based encoder-decoder architecture. This level of technical detail could aid researchers in replicating and building upon the proposed approach.
Overall, the researchers have made a valuable contribution to the field of cross-lingual word alignment, particularly in low-resource settings. The incorporation of contrastive learning appears to be a promising direction for improving the performance of such models, and the planned release of the dataset and code will likely spur further research in this area.
Conclusion
The proposed BiLSTM-based encoder-decoder model with contrastive learning represents a significant advancement in cross-lingual word alignment, a crucial task for natural language processing in low-resource languages. By explicitly modeling the differences between word embeddings in the shared cross-lingual space, the researchers have demonstrated consistent improvements in alignment accuracy across multiple ASEAN language datasets.
This work has important implications for developing more effective natural language processing solutions for underserved and underrepresented languages, which often lack the resources and data available for higher-resource languages. The planned release of the dataset and code will further support research in this area, potentially leading to even more robust and versatile cross-lingual alignment models in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
0
Cross-Lingual Word Alignment for ASEAN Languages with Contrastive Learning
Jingshen Zhang, Xinying Qiu, Teng Shen, Wenyu Wang, Kailin Zhang, Wenhe Feng
Cross-lingual word alignment plays a crucial role in various natural language processing tasks, particularly for low-resource languages. Recent study proposes a BiLSTM-based encoder-decoder model that outperforms pre-trained language models in low-resource settings. However, their model only considers the similarity of word embedding spaces and does not explicitly model the differences between word embeddings. To address this limitation, we propose incorporating contrastive learning into the BiLSTM-based encoder-decoder framework. Our approach introduces a multi-view negative sampling strategy to learn the differences between word pairs in the shared cross-lingual embedding space. We evaluate our model on five bilingual aligned datasets spanning four ASEAN languages: Lao, Vietnamese, Thai, and Indonesian. Experimental results demonstrate that integrating contrastive learning consistently improves word alignment accuracy across all datasets, confirming the effectiveness of the proposed method in low-resource scenarios. We will release our data set and code to support future research on ASEAN or more low-resource word alignment.
Read more7/9/2024
0
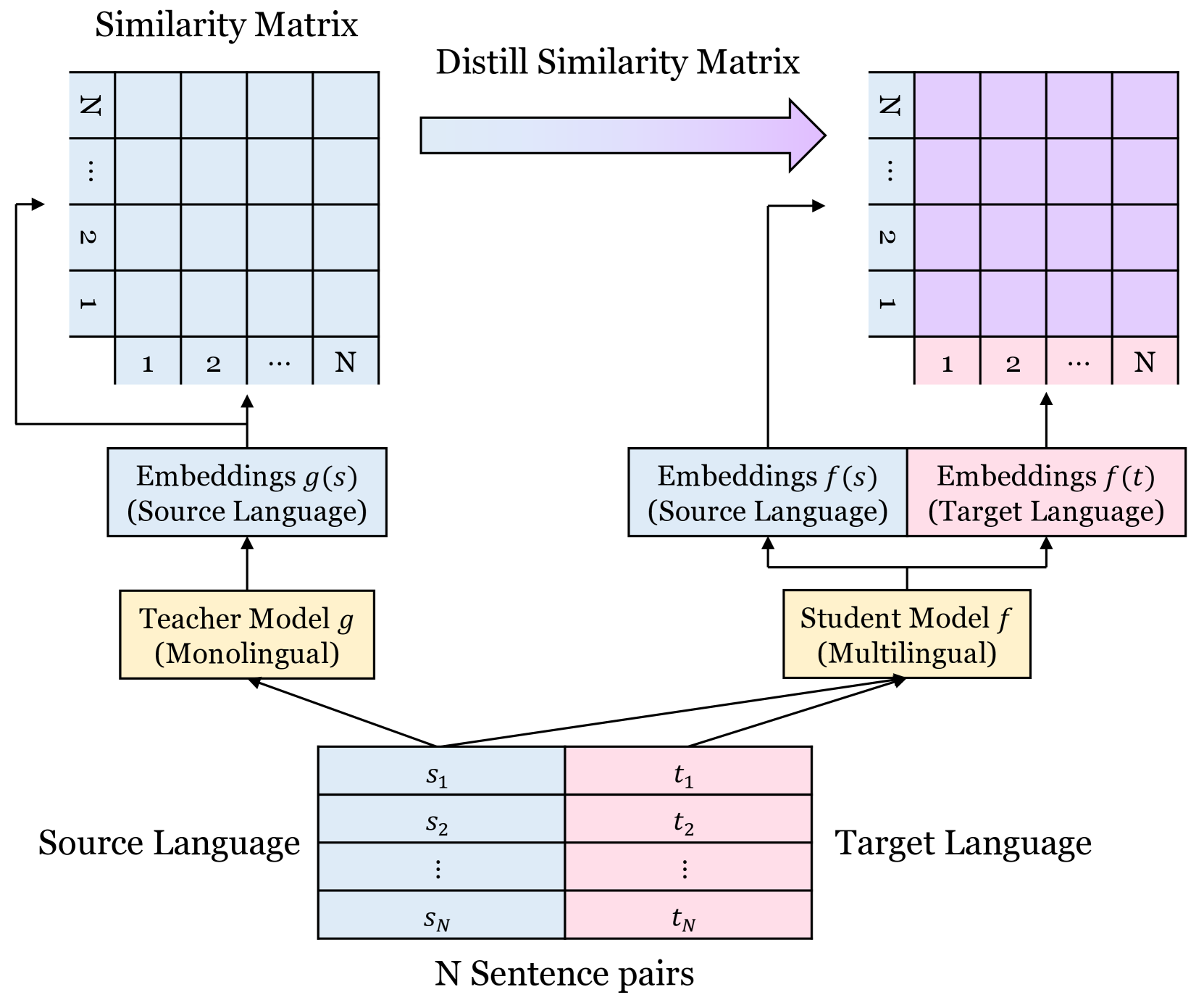
Improving Multi-lingual Alignment Through Soft Contrastive Learning
Minsu Park, Seyeon Choi, Chanyeol Choi, Jun-Seong Kim, Jy-yong Sohn
Making decent multi-lingual sentence representations is critical to achieve high performances in cross-lingual downstream tasks. In this work, we propose a novel method to align multi-lingual embeddings based on the similarity of sentences measured by a pre-trained mono-lingual embedding model. Given translation sentence pairs, we train a multi-lingual model in a way that the similarity between cross-lingual embeddings follows the similarity of sentences measured at the mono-lingual teacher model. Our method can be considered as contrastive learning with soft labels defined as the similarity between sentences. Our experimental results on five languages show that our contrastive loss with soft labels far outperforms conventional contrastive loss with hard labels in various benchmarks for bitext mining tasks and STS tasks. In addition, our method outperforms existing multi-lingual embeddings including LaBSE, for Tatoeba dataset. The code is available at https://github.com/YAI12xLinq-B/IMASCL
Read more5/29/2024
💬
0
Improving In-context Learning of Multilingual Generative Language Models with Cross-lingual Alignment
Chong Li, Shaonan Wang, Jiajun Zhang, Chengqing Zong
Multilingual generative models obtain remarkable cross-lingual in-context learning capabilities through pre-training on large-scale corpora. However, they still exhibit a performance bias toward high-resource languages and learn isolated distributions of multilingual sentence representations, which may hinder knowledge transfer across languages. To bridge this gap, we propose a simple yet effective cross-lingual alignment framework exploiting pairs of translation sentences. It aligns the internal sentence representations across different languages via multilingual contrastive learning and aligns outputs by following cross-lingual instructions in the target language. Experimental results show that even with less than 0.1 {textperthousand} of pre-training tokens, our alignment framework significantly boosts the cross-lingual abilities of generative language models and mitigates the performance gap. Further analyses reveal that it results in a better internal multilingual representation distribution of multilingual models.
Read more6/13/2024
0
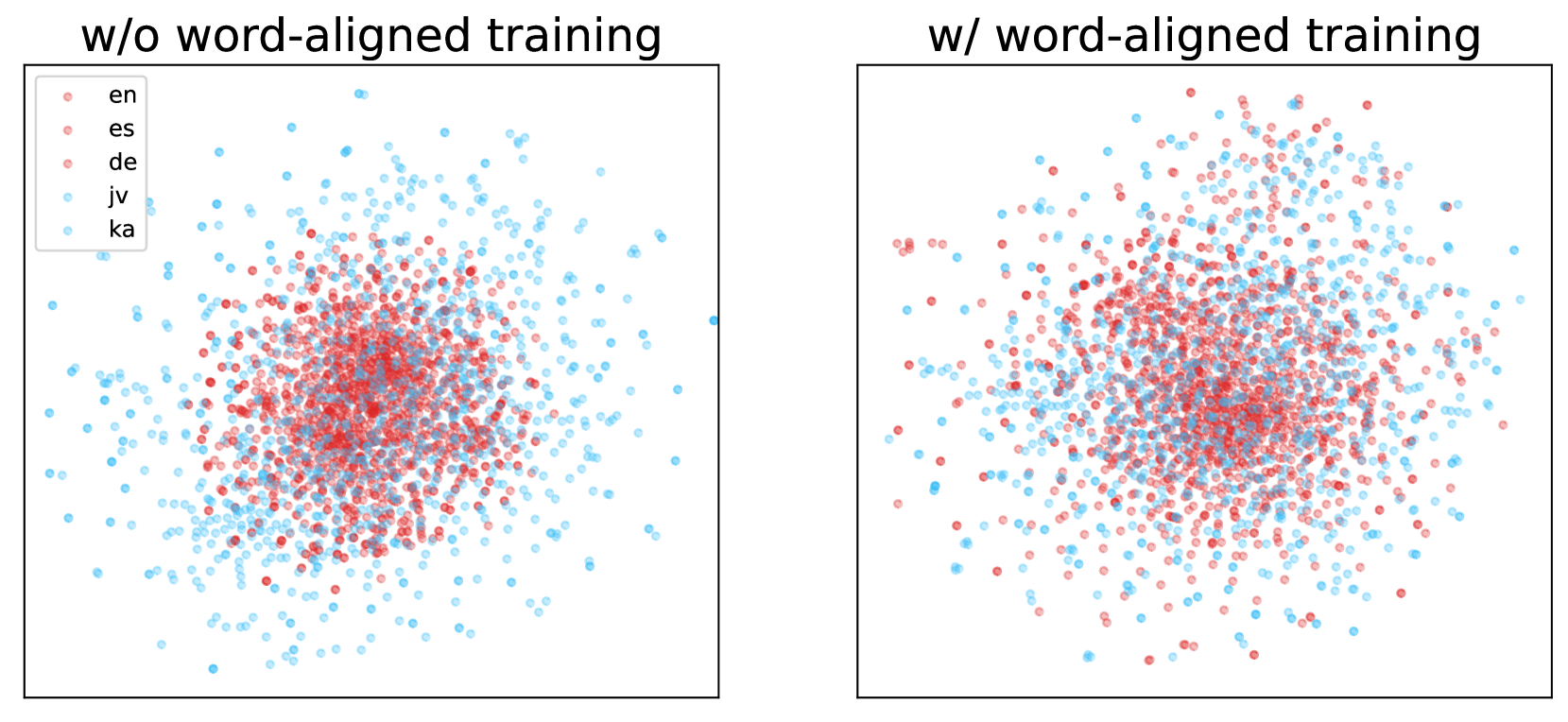
Enhancing Cross-lingual Sentence Embedding for Low-resource Languages with Word Alignment
Zhongtao Miao, Qiyu Wu, Kaiyan Zhao, Zilong Wu, Yoshimasa Tsuruoka
The field of cross-lingual sentence embeddings has recently experienced significant advancements, but research concerning low-resource languages has lagged due to the scarcity of parallel corpora. This paper shows that cross-lingual word representation in low-resource languages is notably under-aligned with that in high-resource languages in current models. To address this, we introduce a novel framework that explicitly aligns words between English and eight low-resource languages, utilizing off-the-shelf word alignment models. This framework incorporates three primary training objectives: aligned word prediction and word translation ranking, along with the widely used translation ranking. We evaluate our approach through experiments on the bitext retrieval task, which demonstrate substantial improvements on sentence embeddings in low-resource languages. In addition, the competitive performance of the proposed model across a broader range of tasks in high-resource languages underscores its practicality.
Read more4/4/2024