Improving In-context Learning of Multilingual Generative Language Models with Cross-lingual Alignment
2311.08089
0
0
💬
Abstract
Multilingual generative models obtain remarkable cross-lingual in-context learning capabilities through pre-training on large-scale corpora. However, they still exhibit a performance bias toward high-resource languages and learn isolated distributions of multilingual sentence representations, which may hinder knowledge transfer across languages. To bridge this gap, we propose a simple yet effective cross-lingual alignment framework exploiting pairs of translation sentences. It aligns the internal sentence representations across different languages via multilingual contrastive learning and aligns outputs by following cross-lingual instructions in the target language. Experimental results show that even with less than 0.1 {textperthousand} of pre-training tokens, our alignment framework significantly boosts the cross-lingual abilities of generative language models and mitigates the performance gap. Further analyses reveal that it results in a better internal multilingual representation distribution of multilingual models.
Create account to get full access
Overview
- Multilingual language models have impressive cross-lingual abilities through pre-training on large datasets
- However, they still perform better on high-resource languages and their multilingual representations are isolated
- This paper proposes a simple framework to align the internal representations and outputs of multilingual models across languages
Plain English Explanation
Multilingual AI language models, which can understand and generate text in many languages, have become quite advanced through extensive pre-training on massive amounts of data. These models can perform well across different languages, a capability known as cross-lingual learning.
However, these models still tend to perform better on languages that have more available data (high-resource languages) compared to low-resource languages. Additionally, the way these models represent language internally can be disconnected across different languages, hindering their ability to effectively transfer knowledge between them.
To address this, the researchers propose a simple framework to better align the internal representations and outputs of multilingual models across languages. The key idea is to use paired translations as a signal to pull the model's representations for the same content closer together, regardless of the language. This helps the model build a more cohesive understanding of language that translates better across languages.
Technical Explanation
The paper introduces a cross-lingual alignment framework to improve the multilingual capabilities of large language models. The core idea is to leverage parallel translation data to align the internal sentence representations and outputs of the model across different languages.
For representation alignment, the framework uses a contrastive learning objective to pull the representations of parallel translation pairs closer together in the embedding space, while pushing apart representations of unrelated sentences. This encourages the model to learn a more cohesive multilingual representation distribution, as opposed to isolated language-specific distributions.
For output alignment, the framework fine-tunes the model to follow cross-lingual instructions in the target language. This helps the model generate responses that are well-aligned with the language and context of the input, further improving cross-lingual transfer.
Experiments show that this simple alignment framework can significantly boost the cross-lingual abilities of multilingual language models, even when using a tiny fraction (less than 0.1%) of the original pre-training data. Further analysis reveals that the framework results in more well-aligned internal multilingual representations, addressing the issue of isolated language distributions seen in existing multilingual models.
Critical Analysis
The proposed cross-lingual alignment framework is a clever and effective approach to improving the multilingual capabilities of large language models. By explicitly aligning the internal representations and outputs across languages, the framework addresses a key limitation of existing multilingual models.
That said, the paper does not provide a thorough investigation of the limitations or potential drawbacks of the approach. For example, it would be valuable to understand how the framework performs on extremely low-resource languages, or how it scales as the number of target languages increases.
Additionally, while the authors demonstrate strong empirical results, they do not provide much insight into the underlying mechanisms driving the performance improvements. A deeper analysis of how the aligned representations impact downstream cross-lingual transfer could yield valuable insights for the field.
Overall, this is a compelling piece of research that makes a notable contribution to the challenge of building truly multilingual AI systems. By encouraging readers to think critically about the approach and its broader implications, the authors pave the way for further advancements in this important area of study.
Conclusion
This paper introduces a simple yet effective framework for aligning the internal representations and outputs of multilingual language models across different languages. By leveraging parallel translation data, the framework encourages the model to learn a more cohesive understanding of language that can be effectively transferred across linguistic boundaries.
The experimental results demonstrate significant improvements in cross-lingual capabilities, even with limited training data. This suggests that the proposed approach could be a valuable tool for enhancing the multilingual abilities of large language models, with potential applications in areas such as machine translation, multilingual question answering, and cross-lingual knowledge transfer.
As the field of multilingual AI continues to advance, frameworks like the one presented in this paper will play an important role in building language models that can truly understand and communicate fluently across a diverse range of languages and contexts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
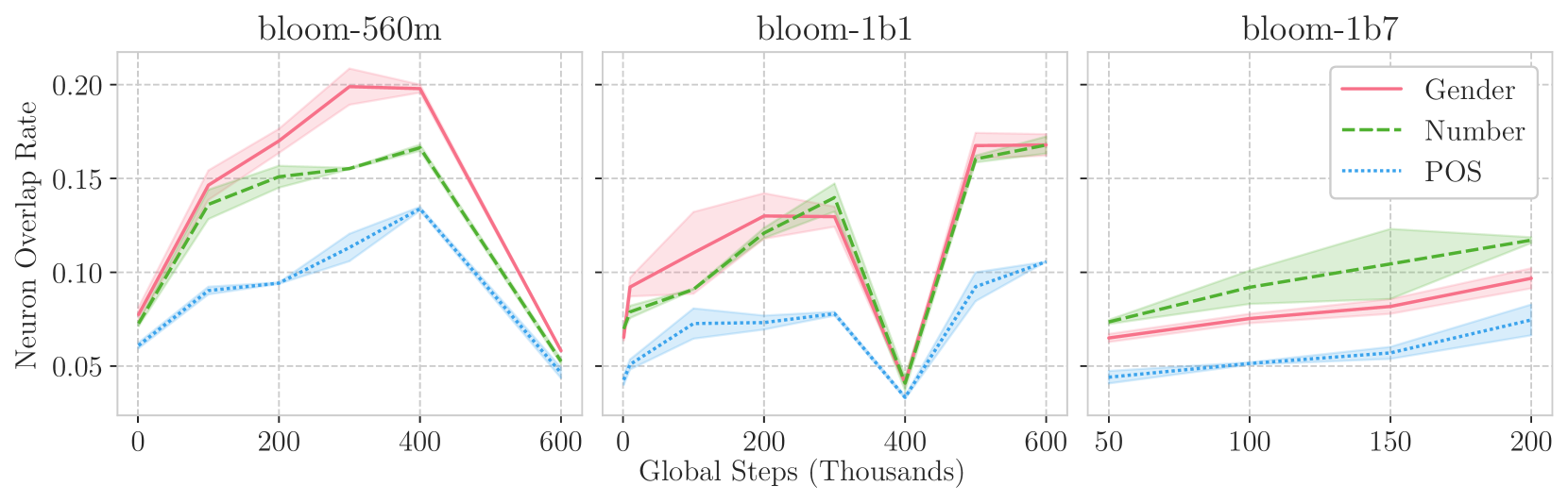
Probing the Emergence of Cross-lingual Alignment during LLM Training
Hetong Wang, Pasquale Minervini, Edoardo M. Ponti
0
0
Multilingual Large Language Models (LLMs) achieve remarkable levels of zero-shot cross-lingual transfer performance. We speculate that this is predicated on their ability to align languages without explicit supervision from parallel sentences. While representations of translationally equivalent sentences in different languages are known to be similar after convergence, however, it remains unclear how such cross-lingual alignment emerges during pre-training of LLMs. Our study leverages intrinsic probing techniques, which identify which subsets of neurons encode linguistic features, to correlate the degree of cross-lingual neuron overlap with the zero-shot cross-lingual transfer performance for a given model. In particular, we rely on checkpoints of BLOOM, a multilingual autoregressive LLM, across different training steps and model scales. We observe a high correlation between neuron overlap and downstream performance, which supports our hypothesis on the conditions leading to effective cross-lingual transfer. Interestingly, we also detect a degradation of both implicit alignment and multilingual abilities in certain phases of the pre-training process, providing new insights into the multilingual pretraining dynamics.
6/21/2024
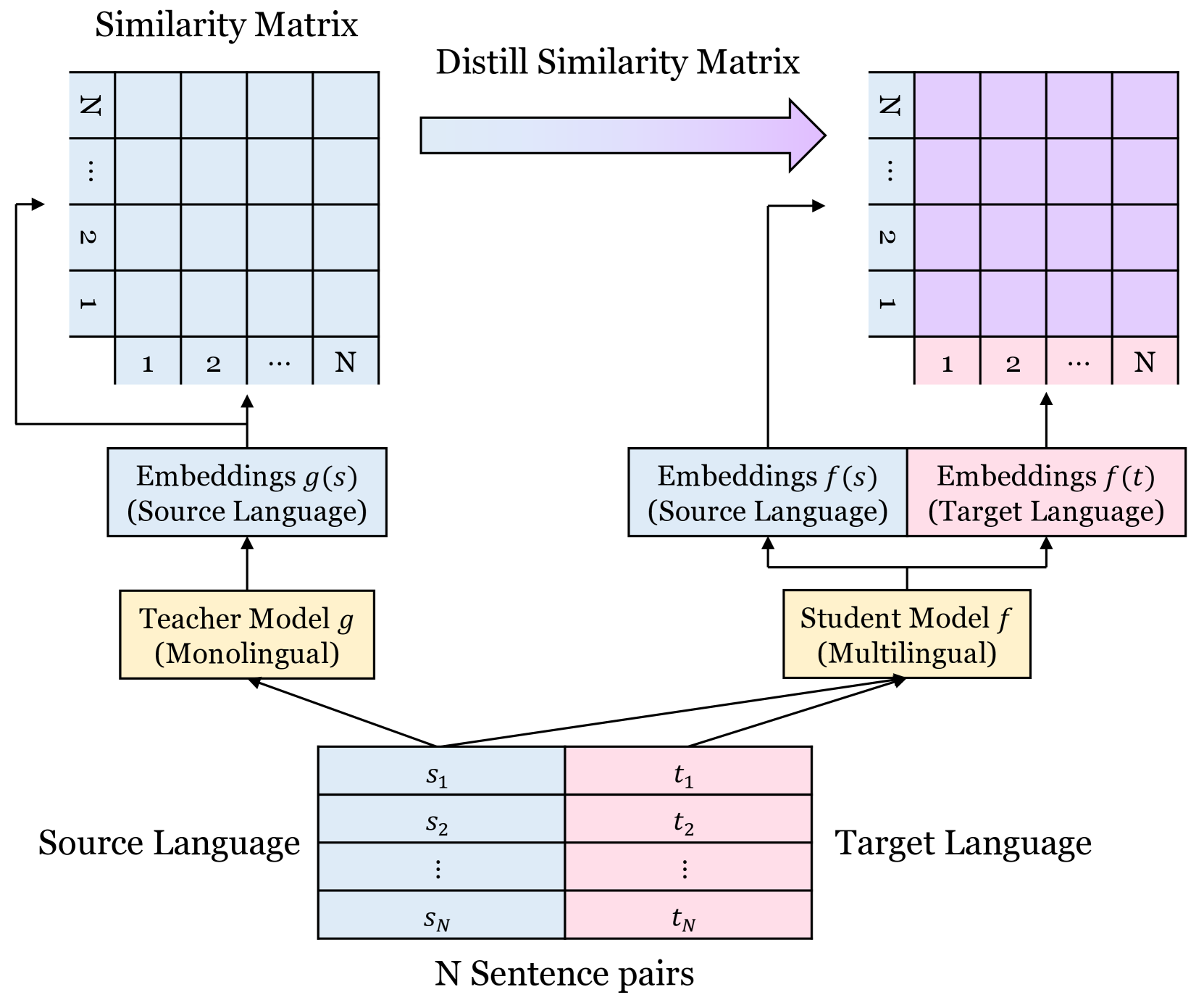
Improving Multi-lingual Alignment Through Soft Contrastive Learning
Minsu Park, Seyeon Choi, Chanyeol Choi, Jun-Seong Kim, Jy-yong Sohn
0
0
Making decent multi-lingual sentence representations is critical to achieve high performances in cross-lingual downstream tasks. In this work, we propose a novel method to align multi-lingual embeddings based on the similarity of sentences measured by a pre-trained mono-lingual embedding model. Given translation sentence pairs, we train a multi-lingual model in a way that the similarity between cross-lingual embeddings follows the similarity of sentences measured at the mono-lingual teacher model. Our method can be considered as contrastive learning with soft labels defined as the similarity between sentences. Our experimental results on five languages show that our contrastive loss with soft labels far outperforms conventional contrastive loss with hard labels in various benchmarks for bitext mining tasks and STS tasks. In addition, our method outperforms existing multi-lingual embeddings including LaBSE, for Tatoeba dataset. The code is available at https://github.com/YAI12xLinq-B/IMASCL
5/29/2024

mOthello: When Do Cross-Lingual Representation Alignment and Cross-Lingual Transfer Emerge in Multilingual Models?
Tianze Hua, Tian Yun, Ellie Pavlick
0
0
Many pretrained multilingual models exhibit cross-lingual transfer ability, which is often attributed to a learned language-neutral representation during pretraining. However, it remains unclear what factors contribute to the learning of a language-neutral representation, and whether the learned language-neutral representation suffices to facilitate cross-lingual transfer. We propose a synthetic task, Multilingual Othello (mOthello), as a testbed to delve into these two questions. We find that: (1) models trained with naive multilingual pretraining fail to learn a language-neutral representation across all input languages; (2) the introduction of anchor tokens (i.e., lexical items that are identical across languages) helps cross-lingual representation alignment; and (3) the learning of a language-neutral representation alone is not sufficient to facilitate cross-lingual transfer. Based on our findings, we propose a novel approach - multilingual pretraining with unified output space - that both induces the learning of language-neutral representation and facilitates cross-lingual transfer.
4/22/2024
Multilingual Pretraining and Instruction Tuning Improve Cross-Lingual Knowledge Alignment, But Only Shallowly
Changjiang Gao, Hongda Hu, Peng Hu, Jiajun Chen, Jixing Li, Shujian Huang
0
0
Despite their strong ability to retrieve knowledge in English, current large language models show imbalance abilities in different languages. Two approaches are proposed to address this, i.e., multilingual pretraining and multilingual instruction tuning. However, whether and how do such methods contribute to the cross-lingual knowledge alignment inside the models is unknown. In this paper, we propose CLiKA, a systematic framework to assess the cross-lingual knowledge alignment of LLMs in the Performance, Consistency and Conductivity levels, and explored the effect of multilingual pretraining and instruction tuning on the degree of alignment. Results show that: while both multilingual pretraining and instruction tuning are beneficial for cross-lingual knowledge alignment, the training strategy needs to be carefully designed. Namely, continued pretraining improves the alignment of the target language at the cost of other languages, while mixed pretraining affect other languages less. Also, the overall cross-lingual knowledge alignment, especially in the conductivity level, is unsatisfactory for all tested LLMs, and neither multilingual pretraining nor instruction tuning can substantially improve the cross-lingual knowledge conductivity.
4/9/2024