Cross-view image geo-localization with Panorama-BEV Co-Retrieval Network

0

Sign in to get full access
Overview
- Cross-view image geo-localization is the task of finding the geographic location of a street-level image by matching it with a reference database of panoramic images.
- The paper presents the Panorama-BEV Co-Retrieval Network, a deep learning model that addresses this task by jointly learning representations from street-level images and panoramic bird's-eye-view (BEV) images.
- The key idea is to leverage the complementary information in these different viewpoints to improve geo-localization performance.
Plain English Explanation
The paper focuses on the problem of cross-view image geo-localization, which is about finding the location of a street-level photo by matching it against a database of panoramic, overhead images. To do this, the researchers developed a deep learning model called the Panorama-BEV Co-Retrieval Network.
The core insight is that street-level and overhead images contain complementary information that can be leveraged together to improve geo-localization. Street-level images capture detailed visual cues like building facades and street-level objects, while overhead panoramic images provide a broader, bird's-eye-view (BEV) of the surrounding area. By jointly learning representations from both viewpoints, the model can make more accurate matches between the query street-level image and the reference panoramic images.
Technical Explanation
The Panorama-BEV Co-Retrieval Network has two main components:
- A street-level image encoder that learns visual features from the query street-level image.
- A panoramic BEV image encoder that learns features from the reference panoramic images.
The model is trained to maximize the similarity between the encoded features of a matching street-level and panoramic image pair, while minimizing the similarity for non-matching pairs. This allows the model to learn a joint embedding space where visually similar street-level and panoramic images are mapped close together.
At inference time, the model takes a query street-level image and retrieves the most similar panoramic images from the database. The geographic location associated with the top-ranked panoramic image is then returned as the predicted location of the query image.
The paper demonstrates the effectiveness of this approach through experiments on several cross-view geo-localization benchmarks, showing significant performance improvements over prior methods.
Critical Analysis
The Panorama-BEV Co-Retrieval Network represents an interesting and promising approach to cross-view geo-localization. By jointly learning from street-level and overhead panoramic views, the model is able to leverage complementary information to make more accurate location predictions.
However, the paper does not discuss potential limitations or challenges of this approach. For example, the model may struggle in urban environments with many similar-looking buildings or in areas with significant changes over time between the street-level and panoramic reference images.
Additionally, the paper focuses solely on the geo-localization task and does not explore other potential applications of the learned joint representations, such as fine-grained location and orientation extraction or BEV reconstruction from street-level imagery.
Further research could investigate the robustness of the model to various real-world challenges, as well as explore other use cases for the joint street-level and panoramic image representations.
Conclusion
The Panorama-BEV Co-Retrieval Network proposed in this paper represents an innovative approach to cross-view geo-localization that leverages the complementary information in street-level and overhead panoramic images. By jointly learning visual representations from these different viewpoints, the model is able to achieve significant performance improvements over prior methods.
While the paper does not address potential limitations or other applications of the learned representations, the core idea of exploiting multi-view information for improved geo-localization is a promising direction for future research. As autonomous systems and location-based services become more prevalent, advances in cross-view geo-localization could have important implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cross-view image geo-localization with Panorama-BEV Co-Retrieval Network
Junyan Ye, Zhutao Lv, Weijia Li, Jinhua Yu, Haote Yang, Huaping Zhong, Conghui He
Cross-view geolocalization identifies the geographic location of street view images by matching them with a georeferenced satellite database. Significant challenges arise due to the drastic appearance and geometry differences between views. In this paper, we propose a new approach for cross-view image geo-localization, i.e., the Panorama-BEV Co-Retrieval Network. Specifically, by utilizing the ground plane assumption and geometric relations, we convert street view panorama images into the BEV view, reducing the gap between street panoramas and satellite imagery. In the existing retrieval of street view panorama images and satellite images, we introduce BEV and satellite image retrieval branches for collaborative retrieval. By retaining the original street view retrieval branch, we overcome the limited perception range issue of BEV representation. Our network enables comprehensive perception of both the global layout and local details around the street view capture locations. Additionally, we introduce CVGlobal, a global cross-view dataset that is closer to real-world scenarios. This dataset adopts a more realistic setup, with street view directions not aligned with satellite images. CVGlobal also includes cross-regional, cross-temporal, and street view to map retrieval tests, enabling a comprehensive evaluation of algorithm performance. Our method excels in multiple tests on common cross-view datasets such as CVUSA, CVACT, VIGOR, and our newly introduced CVGlobal, surpassing the current state-of-the-art approaches. The code and datasets can be found at url{https://github.com/yejy53/EP-BEV}.
Read more8/13/2024

0
Cross-view geo-localization: a survey
Abhilash Durgam, Sidike Paheding, Vikas Dhiman, Vijay Devabhaktuni
Cross-view geo-localization has garnered notable attention in the realm of computer vision, spurred by the widespread availability of copious geotagged datasets and the advancements in machine learning techniques. This paper provides a thorough survey of cutting-edge methodologies, techniques, and associated challenges that are integral to this domain, with a focus on feature-based and deep learning strategies. Feature-based methods capitalize on unique features to establish correspondences across disparate viewpoints, whereas deep learning-based methodologies deploy convolutional neural networks to embed view-invariant attributes. This work also delineates the multifaceted challenges encountered in cross-view geo-localization, such as variations in viewpoints and illumination, the occurrence of occlusions, and it elucidates innovative solutions that have been formulated to tackle these issues. Furthermore, we delineate benchmark datasets and relevant evaluation metrics, and also perform a comparative analysis of state-of-the-art techniques. Finally, we conclude the paper with a discussion on prospective avenues for future research and the burgeoning applications of cross-view geo-localization in an intricately interconnected global landscape.
Read more6/17/2024

0
ConGeo: Robust Cross-view Geo-localization across Ground View Variations
Li Mi, Chang Xu, Javiera Castillo-Navarro, Syrielle Montariol, Wen Yang, Antoine Bosselut, Devis Tuia
Cross-view geo-localization aims at localizing a ground-level query image by matching it to its corresponding geo-referenced aerial view. In real-world scenarios, the task requires accommodating diverse ground images captured by users with varying orientations and reduced field of views (FoVs). However, existing learning pipelines are orientation-specific or FoV-specific, demanding separate model training for different ground view variations. Such models heavily depend on the North-aligned spatial correspondence and predefined FoVs in the training data, compromising their robustness across different settings. To tackle this challenge, we propose ConGeo, a single- and cross-view Contrastive method for Geo-localization: it enhances robustness and consistency in feature representations to improve a model's invariance to orientation and its resilience to FoV variations, by enforcing proximity between ground view variations of the same location. As a generic learning objective for cross-view geo-localization, when integrated into state-of-the-art pipelines, ConGeo significantly boosts the performance of three base models on four geo-localization benchmarks for diverse ground view variations and outperforms competing methods that train separate models for each ground view variation.
Read more9/6/2024
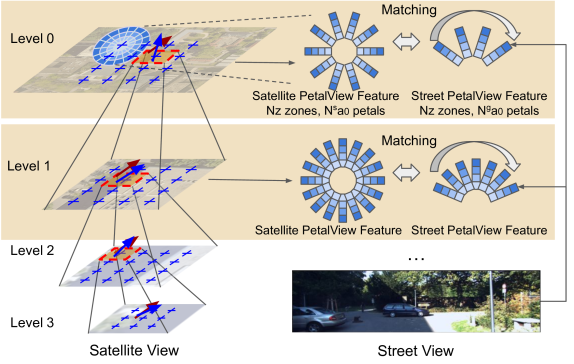
0
PetalView: Fine-grained Location and Orientation Extraction of Street-view Images via Cross-view Local Search with Supplementary Materials
Wenmiao Hu, Yichen Zhang, Yuxuan Liang, Xianjing Han, Yifang Yin, Hannes Kruppa, See-Kiong Ng, Roger Zimmermann
Satellite-based street-view information extraction by cross-view matching refers to a task that extracts the location and orientation information of a given street-view image query by using one or multiple geo-referenced satellite images. Recent work has initiated a new research direction to find accurate information within a local area covered by one satellite image centered at a location prior (e.g., from GPS). It can be used as a standalone solution or complementary step following a large-scale search with multiple satellite candidates. However, these existing works require an accurate initial orientation (angle) prior (e.g., from IMU) and/or do not efficiently search through all possible poses. To allow efficient search and to give accurate prediction regardless of the existence or the accuracy of the angle prior, we present PetalView extractors with multi-scale search. The PetalView extractors give semantically meaningful features that are equivalent across two drastically different views, and the multi-scale search strategy efficiently inspects the satellite image from coarse to fine granularity to provide sub-meter and sub-degree precision extraction. Moreover, when an angle prior is given, we propose a learnable prior angle mixer to utilize this information. Our method obtains the best performance on the VIGOR dataset and successfully improves the performance on KITTI dataset test 1 set with the recall within 1 meter (r@1m) for location estimation to 68.88% and recall within 1 degree (r@1d) 21.10% when no angle prior is available, and with angle prior achieves stable estimations at r@1m and r@1d above 70% and 21%, up to a 40-degree noise level.
Read more6/21/2024