C-LLM: Learn to Check Chinese Spelling Errors Character by Character

0

Sign in to get full access
Overview
- This paper introduces C-LLM, a novel approach for learning to check Chinese spelling errors character by character.
- It leverages Rich Semantic Knowledge Enhanced Large Language Models to capture contextual information and CSCD-NS: Chinese Spelling Check Dataset - Native Speaker to train the model.
- The proposed method outperforms existing state-of-the-art Chinese spelling error detection and correction systems.
Plain English Explanation
The paper focuses on developing a system that can identify and correct spelling errors in Chinese text. Chinese writing can be challenging as it uses thousands of unique characters, each with its own meaning and pronunciation. This makes it difficult for existing spelling correction algorithms, which are often designed for alphabetic languages like English.
The researchers introduce C-LLM, a large language model trained specifically to understand the contextual nuances of Chinese. By leveraging rich semantic knowledge, C-LLM can better identify when a character is used incorrectly in a sentence and suggest the appropriate replacement.
The model is trained on a dataset called CSCD-NS, which contains examples of common spelling mistakes made by native Chinese speakers. This allows C-LLM to learn the types of errors humans are likely to make and how to correct them.
Compared to previous approaches, C-LLM demonstrates improved performance in both detecting and correcting Chinese spelling errors. This has important applications in areas like text editing, language learning, and content moderation, where accurate spelling is crucial.
Technical Explanation
The core of the C-LLM approach is a large language model that has been pre-trained on a Chinese-centric corpus using techniques like Chinese Tiny LLM Pretraining. This allows the model to deeply understand the structure and semantics of the Chinese language.
To detect and correct spelling errors, C-LLM uses a bi-directional architecture similar to Bi-DCSpell. It processes the input text both left-to-right and right-to-left to capture the full contextual information around each character.
The model is trained on the CSCD-NS dataset, which contains naturally occurring spelling mistakes made by native Chinese speakers. This allows C-LLM to learn the types of errors humans actually make, rather than just synthetic mistakes.
During inference, C-LLM analyzes each character in the input text and predicts whether it is correct or not. If an error is detected, the model then generates a corrected version of the character. This character-by-character approach is more granular than previous word-level spelling correction methods, allowing for more precise identification and correction of errors.
Critical Analysis
The researchers acknowledge that C-LLM is not infallible and may still make mistakes, especially with rare or complex characters. Additionally, the model is trained on native speaker errors, so it may not perform as well on spelling mistakes made by non-native learners of Chinese.
While the paper demonstrates impressive results, it would be valuable to see further evaluation of C-LLM on a wider range of real-world Chinese text corpora, including social media, technical documents, and creative writing. This could help uncover additional challenges and edge cases.
It would also be interesting to explore integrating C-LLM with Contextual Spelling Correction Language Models for low-resource languages. This could expand the applicability of the approach to other writing systems beyond Chinese.
Conclusion
The C-LLM system presented in this paper represents a significant advance in Chinese spelling error detection and correction. By leveraging rich semantic knowledge and a character-level approach, it outperforms previous state-of-the-art methods.
This technology has important implications for improving the quality and accessibility of Chinese text across a variety of applications, from language learning to content moderation. As Chinese continues to grow as a global language, tools like C-LLM will become increasingly valuable for ensuring clear and error-free communication.
Overall, this research demonstrates the power of tailoring language models to the unique characteristics of specific writing systems, rather than relying on one-size-fits-all approaches. The insights and techniques developed here could inspire similar innovations for other complex linguistic challenges in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
C-LLM: Learn to Check Chinese Spelling Errors Character by Character
Kunting Li, Yong Hu, Liang He, Fandong Meng, Jie Zhou
Chinese Spell Checking (CSC) aims to detect and correct spelling errors in sentences. Despite Large Language Models (LLMs) exhibit robust capabilities and are widely applied in various tasks, their performance on CSC is often unsatisfactory. We find that LLMs fail to meet the Chinese character-level constraints of the CSC task, namely equal length and phonetic similarity, leading to a performance bottleneck. Further analysis reveal that this issue stems from the granularity of tokenization, as current mixed character-word tokenization struggles to satisfy these character-level constraints. To address this issue, we propose C-LLM, a Large Language Model-based Chinese Spell Checking method that learns to check errors Character by Character. Character-level tokenization enables the model to learn character-level alignment, effectively mitigating issues related to character-level constraints. Furthermore, CSC is simplified to replication-dominated and substitution-supplemented tasks. Experiments on two CSC benchmarks demonstrate that C-LLM achieves an average improvement of 10% over existing methods. Specifically, it shows a 2.1% improvement in general scenarios and a significant 12% improvement in vertical domain scenarios, establishing state-of-the-art performance. The source code can be accessed at https://github.com/ktlKTL/C-LLM.
Read more6/26/2024

0
Rich Semantic Knowledge Enhanced Large Language Models for Few-shot Chinese Spell Checking
Ming Dong, Yujing Chen, Miao Zhang, Hao Sun, Tingting He
Chinese Spell Checking (CSC) is a widely used technology, which plays a vital role in speech to text (STT) and optical character recognition (OCR). Most of the existing CSC approaches relying on BERT architecture achieve excellent performance. However, limited by the scale of the foundation model, BERT-based method does not work well in few-shot scenarios, showing certain limitations in practical applications. In this paper, we explore using an in-context learning method named RS-LLM (Rich Semantic based LLMs) to introduce large language models (LLMs) as the foundation model. Besides, we study the impact of introducing various Chinese rich semantic information in our framework. We found that by introducing a small number of specific Chinese rich semantic structures, LLMs achieve better performance than the BERT-based model on few-shot CSC task. Furthermore, we conduct experiments on multiple datasets, and the experimental results verified the superiority of our proposed framework.
Read more6/10/2024
⛏️
0
CSCD-NS: a Chinese Spelling Check Dataset for Native Speakers
Yong Hu, Fandong Meng, Jie Zhou
In this paper, we present CSCD-NS, the first Chinese spelling check (CSC) dataset designed for native speakers, containing 40,000 samples from a Chinese social platform. Compared with existing CSC datasets aimed at Chinese learners, CSCD-NS is ten times larger in scale and exhibits a distinct error distribution, with a significantly higher proportion of word-level errors. To further enhance the data resource, we propose a novel method that simulates the input process through an input method, generating large-scale and high-quality pseudo data that closely resembles the actual error distribution and outperforms existing methods. Moreover, we investigate the performance of various models in this scenario, including large language models (LLMs), such as ChatGPT. The result indicates that generative models underperform BERT-like classification models due to strict length and pronunciation constraints. The high prevalence of word-level errors also makes CSC for native speakers challenging enough, leaving substantial room for improvement.
Read more5/24/2024
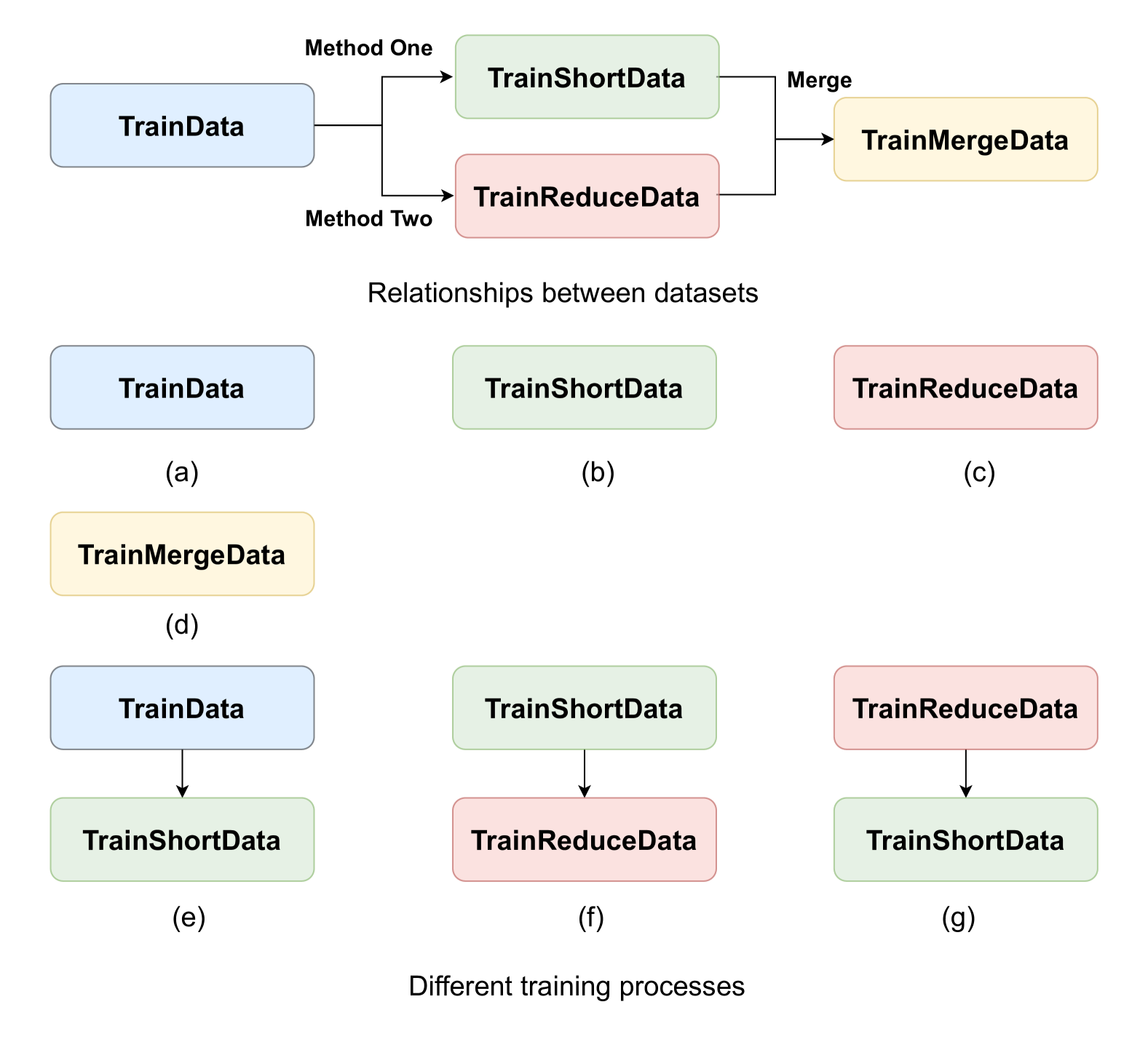
0
EdaCSC: Two Easy Data Augmentation Methods for Chinese Spelling Correction
Lei Sheng, Shuai-Shuai Xu
Chinese Spelling Correction (CSC) aims to detect and correct spelling errors in Chinese sentences caused by phonetic or visual similarities. While current CSC models integrate pinyin or glyph features and have shown significant progress,they still face challenges when dealing with sentences containing multiple typos and are susceptible to overcorrection in real-world scenarios. In contrast to existing model-centric approaches, we propose two data augmentation methods to address these limitations. Firstly, we augment the dataset by either splitting long sentences into shorter ones or reducing typos in sentences with multiple typos. Subsequently, we employ different training processes to select the optimal model. Experimental evaluations on the SIGHAN benchmarks demonstrate the superiority of our approach over most existing models, achieving state-of-the-art performance on the SIGHAN15 test set.
Read more9/10/2024