TIPAA-SSL: Text Independent Phone-to-Audio Alignment based on Self-Supervised Learning and Knowledge Transfer
2405.02124
0
0
🔄
Abstract
In this paper, we present a novel approach for text independent phone-to-audio alignment based on phoneme recognition, representation learning and knowledge transfer. Our method leverages a self-supervised model (wav2vec2) fine-tuned for phoneme recognition using a Connectionist Temporal Classification (CTC) loss, a dimension reduction model and a frame-level phoneme classifier trained thanks to forced-alignment labels (using Montreal Forced Aligner) to produce multi-lingual phonetic representations, thus requiring minimal additional training. We evaluate our model using synthetic native data from the TIMIT dataset and the SCRIBE dataset for American and British English, respectively. Our proposed model outperforms the state-of-the-art (charsiu) in statistical metrics and has applications in language learning and speech processing systems. We leave experiments on other languages for future work but the design of the system makes it easily adaptable to other languages.
Create account to get full access
Overview
- This paper presents a novel approach for text-independent phone-to-audio alignment using phoneme recognition, representation learning, and knowledge transfer.
- The method leverages a self-supervised wav2vec2 model fine-tuned for phoneme recognition, a dimension reduction model, and a frame-level phoneme classifier.
- The model is evaluated on synthetic native data from the TIMIT dataset and the SCRIBE dataset for American and British English, outperforming the state-of-the-art charsiu approach.
- The authors suggest the system's design makes it easily adaptable to other languages, and they plan to explore experiments in other languages in the future.
Plain English Explanation
The researchers have developed a new way to automatically align text with audio, without needing the text to be specific to the audio. This is useful for applications like language learning and speech processing systems.
The key idea is to use a pre-trained AI model that can recognize individual speech sounds (phonemes). This model is then fine-tuned and combined with other components to create a system that can accurately match up text and audio, even for languages it hasn't been trained on before.
The researchers tested their system on English data and found it performed better than the previous state-of-the-art approach. The flexible design of their system also suggests it could be easily adapted to work with other languages in the future.
Technical Explanation
The paper presents a text-independent phone-to-audio alignment approach that leverages phoneme recognition, representation learning, and knowledge transfer. The core components include:
- A self-supervised wav2vec2 model fine-tuned for phoneme recognition using Connectionist Temporal Classification (CTC) loss.
- A dimension reduction model to produce multi-lingual phonetic representations.
- A frame-level phoneme classifier trained using forced-alignment labels from the Montreal Forced Aligner.
The authors evaluate their proposed model on synthetic native data from the TIMIT dataset and the SCRIBE dataset for American and British English, respectively. Their model outperforms the state-of-the-art charsiu approach in statistical metrics.
The flexible design of the system suggests it could be easily adapted to other languages, and the authors plan to explore experiments on other languages in the future.
Critical Analysis
The paper presents a promising approach for text-independent phone-to-audio alignment, but there are a few potential limitations and areas for further research:
- The evaluation is limited to English data, and the authors acknowledge the need to explore other languages to fully demonstrate the system's adaptability.
- The performance of the model on non-native speech or accented speech is not addressed, which could be an important consideration for real-world applications.
- The computational efficiency and inference speed of the proposed system are not reported, which would be useful for understanding its practical deployment feasibility.
Overall, the research shows an innovative approach to a challenging problem, but further exploration and validation on a broader range of data and use cases would help strengthen the claims and practical applicability of the method.
Conclusion
This paper presents a novel text-independent phone-to-audio alignment approach that leverages phoneme recognition, representation learning, and knowledge transfer. The authors demonstrate that their flexible and effective system outperforms the state-of-the-art on English data, and they plan to explore its adaptability to other languages in the future.
The research has important implications for language learning and speech processing applications, as it can enable robust and accurate alignment of text and audio without the need for text-specific training data. As the authors continue to refine and validate the approach, it has the potential to make significant contributions to these fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
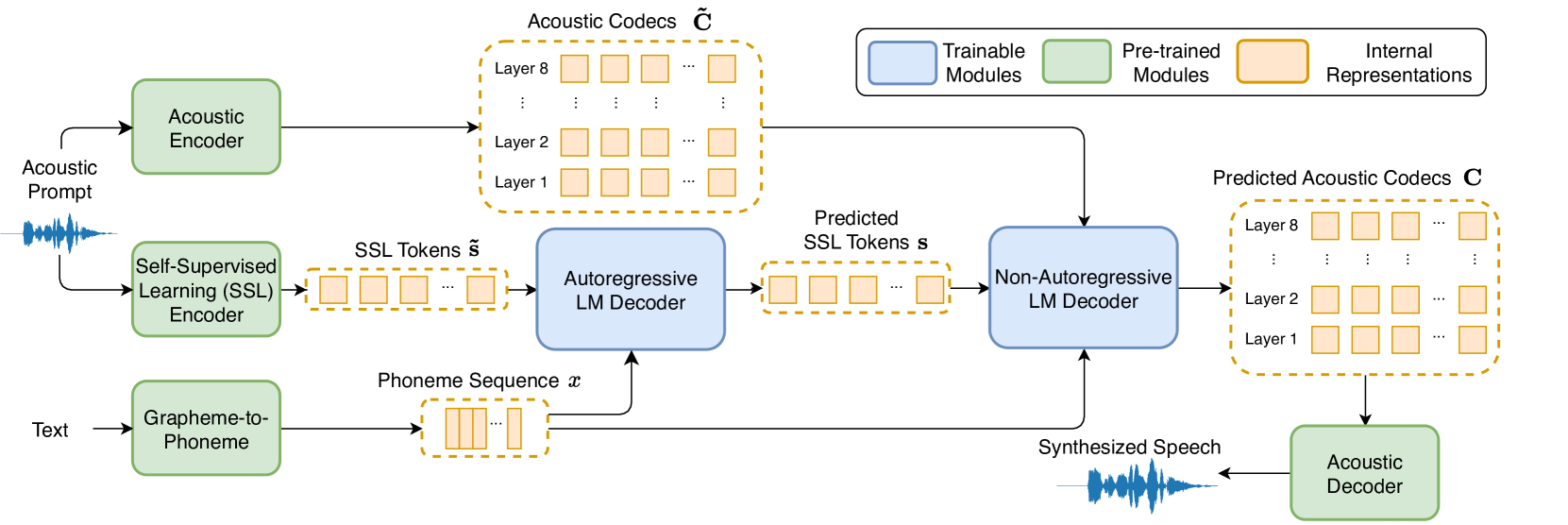
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
0
0
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
6/13/2024
🚀
Low-Resource Self-Supervised Learning with SSL-Enhanced TTS
Po-chun Hsu, Ali Elkahky, Wei-Ning Hsu, Yossi Adi, Tu Anh Nguyen, Jade Copet, Emmanuel Dupoux, Hung-yi Lee, Abdelrahman Mohamed
0
0
Self-supervised learning (SSL) techniques have achieved remarkable results in various speech processing tasks. Nonetheless, a significant challenge remains in reducing the reliance on vast amounts of speech data for pre-training. This paper proposes to address this challenge by leveraging synthetic speech to augment a low-resource pre-training corpus. We construct a high-quality text-to-speech (TTS) system with limited resources using SSL features and generate a large synthetic corpus for pre-training. Experimental results demonstrate that our proposed approach effectively reduces the demand for speech data by 90% with only slight performance degradation. To the best of our knowledge, this is the first work aiming to enhance low-resource self-supervised learning in speech processing.
6/5/2024
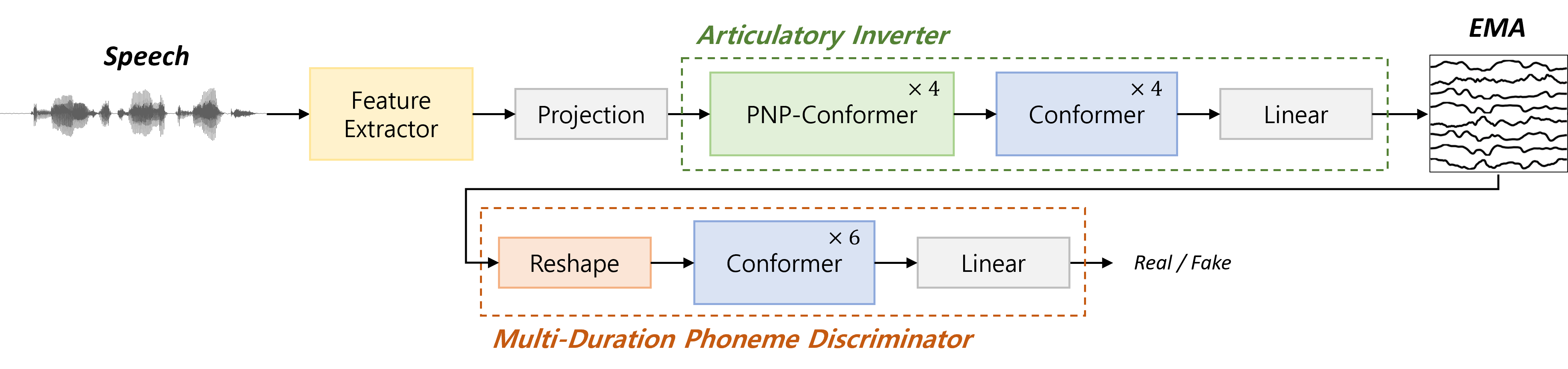
Speaker-Independent Acoustic-to-Articulatory Inversion through Multi-Channel Attention Discriminator
Woo-Jin Chung, Hong-Goo Kang
0
0
We present a novel speaker-independent acoustic-to-articulatory inversion (AAI) model, overcoming the limitations observed in conventional AAI models that rely on acoustic features derived from restricted datasets. To address these challenges, we leverage representations from a pre-trained self-supervised learning (SSL) model to more effectively estimate the global, local, and kinematic pattern information in Electromagnetic Articulography (EMA) signals during the AAI process. We train our model using an adversarial approach and introduce an attention-based Multi-duration phoneme discriminator (MDPD) designed to fully capture the intricate relationship among multi-channel articulatory signals. Our method achieves a Pearson correlation coefficient of 0.847, marking state-of-the-art performance in speaker-independent AAI models. The implementation details and code can be found online.
6/26/2024
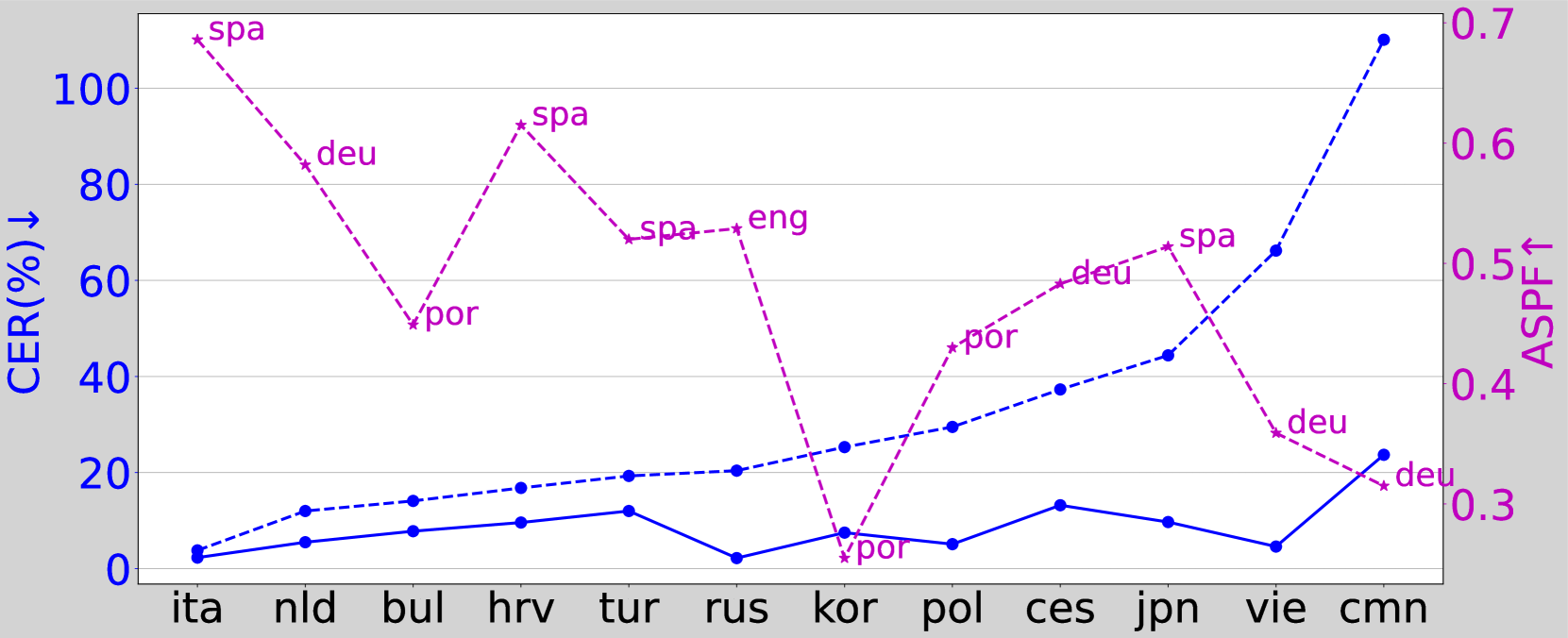
An Initial Investigation of Language Adaptation for TTS Systems under Low-resource Scenarios
Cheng Gong, Erica Cooper, Xin Wang, Chunyu Qiang, Mengzhe Geng, Dan Wells, Longbiao Wang, Jianwu Dang, Marc Tessier, Aidan Pine, Korin Richmond, Junichi Yamagishi
0
0
Self-supervised learning (SSL) representations from massively multilingual models offer a promising solution for low-resource language speech tasks. Despite advancements, language adaptation in TTS systems remains an open problem. This paper explores the language adaptation capability of ZMM-TTS, a recent SSL-based multilingual TTS system proposed in our previous work. We conducted experiments on 12 languages using limited data with various fine-tuning configurations. We demonstrate that the similarity in phonetics between the pre-training and target languages, as well as the language category, affects the target language's adaptation performance. Additionally, we find that the fine-tuning dataset size and number of speakers influence adaptability. Surprisingly, we also observed that using paired data for fine-tuning is not always optimal compared to audio-only data. Beyond speech intelligibility, our analysis covers speaker similarity, language identification, and predicted MOS.
6/14/2024