CTISum: A New Benchmark Dataset For Cyber Threat Intelligence Summarization

0

Sign in to get full access
Overview
- A new benchmark dataset called CTISum for evaluating Cyber Threat Intelligence (CTI) summarization models
- The dataset contains over 10,000 CTI reports and associated summaries
- Designed to advance research in automated CTI summarization, which is crucial for analysts to efficiently consume large volumes of CTI information
Plain English Explanation
The researchers have created a new dataset called CTISum to help develop better systems for summarizing Cyber Threat Intelligence (CTI) reports. CTI reports contain important information about cyber threats, vulnerabilities, and attack tactics that security analysts need to be aware of. However, there is a huge volume of these reports, making it difficult for analysts to read and understand all the relevant information.
The CTISum dataset contains over 10,000 CTI reports along with human-written summaries of those reports. Researchers can use this dataset to train and test machine learning models that can automatically summarize the key points of a CTI report in a concise way. This would save analysts a lot of time and effort, allowing them to quickly identify the most critical information they need to protect their organizations from cyber threats.
By providing a standardized benchmark dataset, the researchers hope to spur more progress in the field of automated CTI summarization, which is an important problem for cybersecurity.
Technical Explanation
The CTISum dataset consists of over 10,000 Cyber Threat Intelligence (CTI) reports along with human-written summaries of those reports. The reports cover a wide range of cyber threats, vulnerabilities, and attack techniques.
To construct the dataset, the researchers collected CTI reports from various public and private sources, including security blogs, threat intelligence platforms, and government agencies. They then hired expert annotators to review each report and write a concise summary capturing the key information.
The dataset is designed to serve as a standardized benchmark for evaluating the performance of automated CTI summarization systems. Researchers can use the reports and summaries to train machine learning models to generate summaries, and then evaluate the quality of those summaries against the human-written reference summaries.
The dataset includes metadata about each report, such as the source, publication date, and topic tags. This additional information can be used to analyze the performance of summarization models across different types of CTI content.
By providing a large-scale, high-quality dataset for CTI summarization, the researchers aim to advance the state-of-the-art in this important area of cybersecurity research. Automated CTI summarization can significantly improve analysts' ability to quickly identify and respond to emerging cyber threats.
Critical Analysis
The CTISum dataset represents a valuable contribution to the field of Cyber Threat Intelligence (CTI) research. The large scale and diversity of the reports, combined with the high-quality human-written summaries, make this an excellent benchmark for evaluating CTI summarization models.
One potential limitation is the representativeness of the dataset. While the researchers have tried to include reports from a variety of sources, the dataset may still be biased towards certain types of CTI content or organizations. It would be helpful to understand the demographic and geographic distribution of the reports to assess how well the dataset covers the broader CTI landscape.
Additionally, the dataset only provides single-sentence summaries for each report. In practice, analysts may require more detailed, multi-sentence summaries to fully comprehend the key information. Future work could explore expanding the dataset to include longer, more comprehensive summaries.
Despite these minor caveats, the CTISum dataset represents a significant step forward in enabling rigorous, reproducible research on automated CTI summarization. By providing a standardized benchmark, the researchers have laid the groundwork for continued advancements in this crucial area of cybersecurity.
Conclusion
The CTISum dataset is a valuable new resource for researchers working on Cyber Threat Intelligence (CTI) summarization. By providing a large-scale, high-quality dataset of CTI reports and human-written summaries, the researchers have created a standardized benchmark to drive progress in this important field.
Automated CTI summarization has the potential to greatly enhance the efficiency and effectiveness of security analysts, who are tasked with consuming and acting on vast amounts of threat intelligence. The CTISum dataset will enable researchers to develop and test more advanced summarization models, ultimately leading to better tools and techniques for protecting organizations from cyber threats.
Overall, the CTISum dataset represents an important contribution to the cybersecurity research community, and the authors are to be commended for their efforts in creating this valuable resource.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CTISum: A New Benchmark Dataset For Cyber Threat Intelligence Summarization
Wei Peng, Junmei Ding, Wei Wang, Lei Cui, Wei Cai, Zhiyu Hao, Xiaochun Yun
Cyber Threat Intelligence (CTI) summarization task requires the system to generate concise and accurate highlights from raw intelligence data, which plays an important role in providing decision-makers with crucial information to quickly detect and respond to cyber threats in the cybersecurity domain. However, efficient techniques for summarizing CTI reports, including facts, analytical insights, attack processes, etc., have largely been unexplored, primarily due to the lack of available dataset. To this end, we present CTISum, a new benchmark for CTI summarization task. Considering the importance of attack process, a novel fine-grained subtask of attack process summarization is proposed to enable defenders to assess risk, identify security gaps, vulnerabilities, and so on. Specifically, we first design a multi-stage annotation pipeline to gather and annotate the CTI data, and then benchmark the CTISum with a collection of extractive and abstractive summarization methods. Experimental results show that current state-of-the-art models exhibit limitations when applied to CTISum, underscoring the fact that automatically producing concise summaries of CTI reports remains an open research challenge.
Read more8/14/2024

0
ReflectSumm: A Benchmark for Course Reflection Summarization
Yang Zhong, Mohamed Elaraby, Diane Litman, Ahmed Ashraf Butt, Muhsin Menekse
This paper introduces ReflectSumm, a novel summarization dataset specifically designed for summarizing students' reflective writing. The goal of ReflectSumm is to facilitate developing and evaluating novel summarization techniques tailored to real-world scenarios with little training data, %practical tasks with potential implications in the opinion summarization domain in general and the educational domain in particular. The dataset encompasses a diverse range of summarization tasks and includes comprehensive metadata, enabling the exploration of various research questions and supporting different applications. To showcase its utility, we conducted extensive evaluations using multiple state-of-the-art baselines. The results provide benchmarks for facilitating further research in this area.
Read more4/24/2024
0
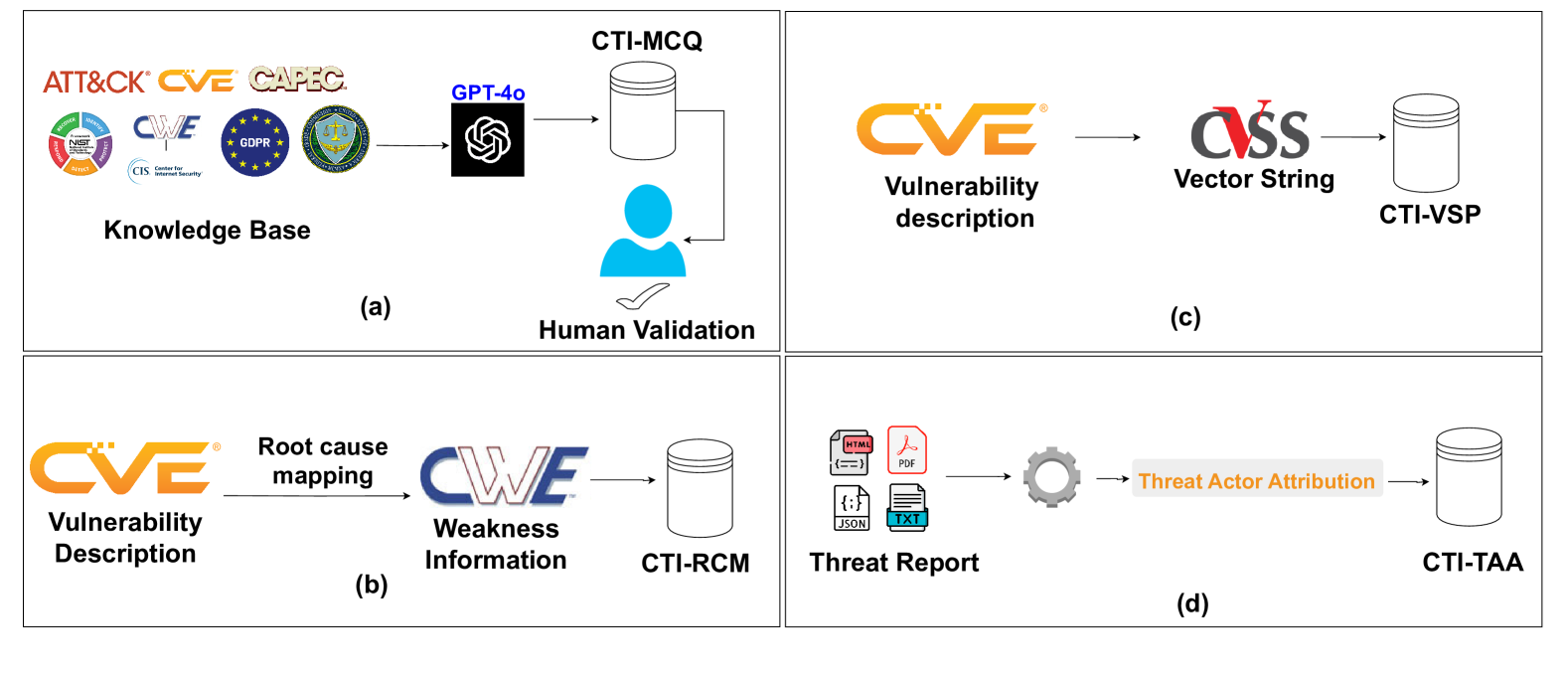
CTIBench: A Benchmark for Evaluating LLMs in Cyber Threat Intelligence
Md Tanvirul Alam, Dipkamal Bhusal, Le Nguyen, Nidhi Rastogi
Cyber threat intelligence (CTI) is crucial in today's cybersecurity landscape, providing essential insights to understand and mitigate the ever-evolving cyber threats. The recent rise of Large Language Models (LLMs) have shown potential in this domain, but concerns about their reliability, accuracy, and hallucinations persist. While existing benchmarks provide general evaluations of LLMs, there are no benchmarks that address the practical and applied aspects of CTI-specific tasks. To bridge this gap, we introduce CTIBench, a benchmark designed to assess LLMs' performance in CTI applications. CTIBench includes multiple datasets focused on evaluating knowledge acquired by LLMs in the cyber-threat landscape. Our evaluation of several state-of-the-art models on these tasks provides insights into their strengths and weaknesses in CTI contexts, contributing to a better understanding of LLM capabilities in CTI.
Read more6/26/2024

0
SUMIE: A Synthetic Benchmark for Incremental Entity Summarization
Eunjeong Hwang, Yichao Zhou, Beliz Gunel, James Bradley Wendt, Sandeep Tata
No existing dataset adequately tests how well language models can incrementally update entity summaries - a crucial ability as these models rapidly advance. The Incremental Entity Summarization (IES) task is vital for maintaining accurate, up-to-date knowledge. To address this, we introduce SUMIE, a fully synthetic dataset designed to expose real-world IES challenges. This dataset effectively highlights problems like incorrect entity association and incomplete information presentation. Unlike common synthetic datasets, ours captures the complexity and nuances found in real-world data. We generate informative and diverse attributes, summaries, and unstructured paragraphs in sequence, ensuring high quality. The alignment between generated summaries and paragraphs exceeds 96%, confirming the dataset's quality. Extensive experiments demonstrate the dataset's difficulty - state-of-the-art LLMs struggle to update summaries with an F1 higher than 80.4%. We will open source the benchmark and the evaluation metrics to help the community make progress on IES tasks.
Read more6/10/2024