ReflectSumm: A Benchmark for Course Reflection Summarization

0

Sign in to get full access
Overview
- This paper introduces ReflectSumm, a new benchmark for evaluating the performance of automatic summarization models on course reflection texts.
- Course reflections are an important part of the learning process, where students analyze their experiences and lessons learned during a course.
- The ReflectSumm dataset contains over 16,000 course reflections from various university courses, providing a valuable resource for training and evaluating summarization models.
Plain English Explanation
The paper presents a new dataset called ReflectSumm that can be used to train and test AI models to automatically summarize course reflection texts. Course reflections are written by students to analyze what they've learned and experienced in a class. These reflections are an important part of the learning process, but can be time-consuming for instructors to read through. The ReflectSumm dataset provides over 16,000 example reflections from various university courses, which can help AI models learn how to effectively summarize the key points from these types of texts. This benchmark dataset can advance research on automatic summarization and help develop tools to support instructors and students in the learning process.
Technical Explanation
The paper introduces the ReflectSumm dataset, which contains over 16,000 course reflection texts collected from various university courses. The reflections cover a wide range of topics and disciplines, providing a diverse dataset for training and evaluating summarization models.
The authors describe the process of collecting and curating the ReflectSumm dataset. They obtained permission from students and instructors to use the reflection texts, anonymized the data, and performed quality control checks. The dataset is divided into training, validation, and test sets to support robust model evaluation.
To establish baselines, the authors evaluate the performance of several existing summarization models on the ReflectSumm benchmark. They assess the models' ability to generate concise summaries that capture the key points and reflect the overall meaning of the original course reflections.
The results show that current state-of-the-art summarization models struggle to effectively summarize the course reflection texts, highlighting the unique challenges and opportunities presented by this new benchmark. The authors discuss potential directions for future research to improve the performance of automatic summarization on this type of reflective text.
Critical Analysis
The ReflectSumm dataset and benchmark provide a valuable contribution to the field of automatic text summarization. By focusing on course reflections, the authors address an important use case that has received limited attention in previous summarization research.
One potential limitation of the dataset is the potential for bias, as the reflections may be influenced by factors such as the specific course, instructor, and student demographics. The authors acknowledge this and suggest further research to understand how these factors may impact summarization performance.
Additionally, the paper does not provide a detailed analysis of the types of errors or weaknesses exhibited by the baseline models. A more in-depth examination of the models' strengths, weaknesses, and failure modes could help guide future research and model development.
Overall, the ReflectSumm benchmark is a promising step forward in advancing the state-of-the-art in automatic text summarization, particularly for reflective and educational texts. The dataset and findings presented in this paper encourage further research and the development of more sophisticated summarization models capable of capturing the nuances and insights present in course reflections.
Conclusion
The ReflectSumm dataset and benchmark introduced in this paper represent an important contribution to the field of automatic text summarization. By focusing on course reflection texts, the authors have created a valuable resource for training and evaluating summarization models on a type of content that is crucial for student learning and instructor assessment.
The results demonstrate that current state-of-the-art summarization models struggle to effectively capture the key points and overall meaning of course reflections, highlighting the unique challenges posed by this type of text. This presents an opportunity for future research to develop more advanced summarization techniques that can better handle the nuanced and reflective nature of these texts.
Overall, the ReflectSumm benchmark has the potential to drive progress in automatic summarization and support the development of tools that can assist instructors and students in the learning process. As the field continues to evolve, this dataset and the insights gained from it will likely play an important role in advancing the state-of-the-art in text summarization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ReflectSumm: A Benchmark for Course Reflection Summarization
Yang Zhong, Mohamed Elaraby, Diane Litman, Ahmed Ashraf Butt, Muhsin Menekse
This paper introduces ReflectSumm, a novel summarization dataset specifically designed for summarizing students' reflective writing. The goal of ReflectSumm is to facilitate developing and evaluating novel summarization techniques tailored to real-world scenarios with little training data, %practical tasks with potential implications in the opinion summarization domain in general and the educational domain in particular. The dataset encompasses a diverse range of summarization tasks and includes comprehensive metadata, enabling the exploration of various research questions and supporting different applications. To showcase its utility, we conducted extensive evaluations using multiple state-of-the-art baselines. The results provide benchmarks for facilitating further research in this area.
Read more4/24/2024

0
CTISum: A New Benchmark Dataset For Cyber Threat Intelligence Summarization
Wei Peng, Junmei Ding, Wei Wang, Lei Cui, Wei Cai, Zhiyu Hao, Xiaochun Yun
Cyber Threat Intelligence (CTI) summarization task requires the system to generate concise and accurate highlights from raw intelligence data, which plays an important role in providing decision-makers with crucial information to quickly detect and respond to cyber threats in the cybersecurity domain. However, efficient techniques for summarizing CTI reports, including facts, analytical insights, attack processes, etc., have largely been unexplored, primarily due to the lack of available dataset. To this end, we present CTISum, a new benchmark for CTI summarization task. Considering the importance of attack process, a novel fine-grained subtask of attack process summarization is proposed to enable defenders to assess risk, identify security gaps, vulnerabilities, and so on. Specifically, we first design a multi-stage annotation pipeline to gather and annotate the CTI data, and then benchmark the CTISum with a collection of extractive and abstractive summarization methods. Experimental results show that current state-of-the-art models exhibit limitations when applied to CTISum, underscoring the fact that automatically producing concise summaries of CTI reports remains an open research challenge.
Read more8/14/2024

0
SurveySum: A Dataset for Summarizing Multiple Scientific Articles into a Survey Section
Leandro Car'isio Fernandes, Gustavo Bartz Guedes, Thiago Soares Laitz, Thales Sales Almeida, Rodrigo Nogueira, Roberto Lotufo, Jayr Pereira
Document summarization is a task to shorten texts into concise and informative summaries. This paper introduces a novel dataset designed for summarizing multiple scientific articles into a section of a survey. Our contributions are: (1) SurveySum, a new dataset addressing the gap in domain-specific summarization tools; (2) two specific pipelines to summarize scientific articles into a section of a survey; and (3) the evaluation of these pipelines using multiple metrics to compare their performance. Our results highlight the importance of high-quality retrieval stages and the impact of different configurations on the quality of generated summaries.
Read more8/30/2024
0
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches
Chao Wang, Neo Wu, Lin Ning, Jiaxing Wu, Luyang Liu, Jun Xie, Shawn O'Banion, Bradley Green
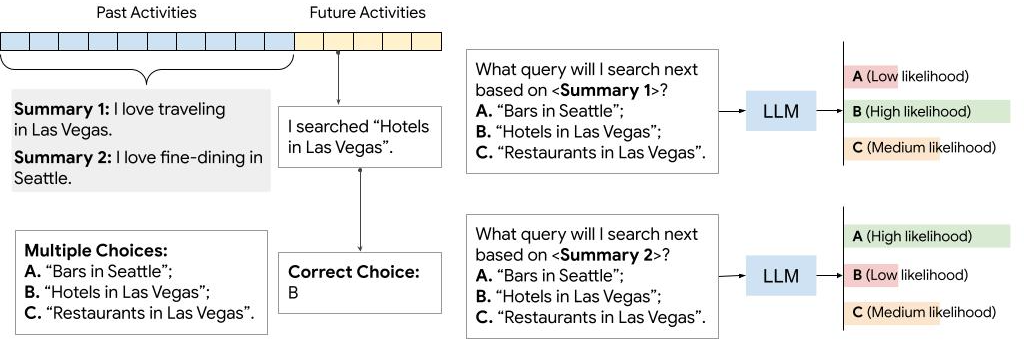
Large language models (LLMs) have shown remarkable capabilities in generating user summaries from a long list of raw user activity data. These summaries capture essential user information such as preferences and interests, and therefore are invaluable for LLM-based personalization applications, such as explainable recommender systems. However, the development of new summarization techniques is hindered by the lack of ground-truth labels, the inherent subjectivity of user summaries, and human evaluation which is often costly and time-consuming. To address these challenges, we introduce UserSumBench, a benchmark framework designed to facilitate iterative development of LLM-based summarization approaches. This framework offers two key components: (1) A reference-free summary quality metric. We show that this metric is effective and aligned with human preferences across three diverse datasets (MovieLens, Yelp and Amazon Review). (2) A novel robust summarization method that leverages time-hierarchical summarizer and self-critique verifier to produce high-quality summaries while eliminating hallucination. This method serves as a strong baseline for further innovation in summarization techniques.
Read more9/9/2024