SUMIE: A Synthetic Benchmark for Incremental Entity Summarization

0

Sign in to get full access
Overview
- This paper introduces a new synthetic benchmark dataset called
\datasetnamefor evaluating incremental entity summarization models. - Incremental entity summarization is the task of generating a summary of an entity (e.g., a person, organization, or location) based on information that becomes available over time.
- The
\datasetnamedataset aims to provide a standardized testbed for this task, addressing limitations of existing datasets.
Plain English Explanation
The paper presents a new dataset called \datasetname that is designed to help evaluate and improve models for a specific type of text summarization task. This task is about summarizing information about an entity, like a person or a company, as new details about that entity become available over time.
Existing datasets for text summarization often have limitations, such as not reflecting the incremental nature of how information about entities is typically gathered. The \datasetname dataset is intended to provide a more realistic and standardized testbed for developing and comparing models that can handle this type of incremental summarization challenge.
By creating this new dataset, the researchers aim to advance the state of the art in this area of natural language processing and support the development of more capable systems for automatically summarizing information about entities as it becomes available.
Technical Explanation
The paper introduces a new synthetic dataset called \datasetname that is designed to evaluate models for the task of incremental entity summarization. In this task, the goal is to generate a summary of an entity (e.g., a person, organization, or location) based on information that becomes available over time, rather than having access to all the information upfront.
The \datasetname dataset is generated using a semi-automated process that involves randomly sampling entity profiles from Wikidata and Wikipedia, and then simulating the incremental release of information about these entities over a series of timesteps. This allows the dataset to capture the inherent uncertainty and evolving nature of real-world entity information.
The paper discusses several desirable properties for a dataset to support incremental entity summarization research, such as diversity of entity types, realistic language, and continuity of information across timesteps. It then demonstrates how the \datasetname dataset meets these criteria through various analyses and comparisons to existing benchmarks.
Critical Analysis
The \datasetname dataset provides a valuable contribution to the field of text summarization by addressing the limitations of existing datasets in the context of incremental entity summarization. The semi-automated data generation process allows for the creation of a large-scale, diverse, and realistic testbed for this task.
However, the paper acknowledges that the \datasetname dataset is a synthetic benchmark, and as such, it may not fully capture the complexities and nuances of real-world entity information sources. There could be potential biases or artifacts introduced during the data generation process that could impact the generalizability of the results obtained using this dataset.
Additionally, the paper does not provide a comprehensive evaluation of the dataset's suitability for training and evaluating incremental entity summarization models. Further research and experimentation would be needed to assess the dataset's ability to reliably measure and drive progress in this area of natural language processing.
Conclusion
The \datasetname dataset introduced in this paper represents an important step forward in the development of benchmarks for incremental entity summarization. By creating a large-scale, diverse, and realistic synthetic dataset, the researchers have provided a valuable tool for the research community to advance the state of the art in this challenging task.
While the dataset has some limitations as a synthetic benchmark, it opens up new avenues for exploring how language models and summarization systems can handle the evolving and uncertain nature of real-world entity information. The insights gained from using the \datasetname dataset could ultimately lead to the creation of more robust and practical systems for automatically summarizing entities as new information becomes available.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SUMIE: A Synthetic Benchmark for Incremental Entity Summarization
Eunjeong Hwang, Yichao Zhou, Beliz Gunel, James Bradley Wendt, Sandeep Tata
No existing dataset adequately tests how well language models can incrementally update entity summaries - a crucial ability as these models rapidly advance. The Incremental Entity Summarization (IES) task is vital for maintaining accurate, up-to-date knowledge. To address this, we introduce SUMIE, a fully synthetic dataset designed to expose real-world IES challenges. This dataset effectively highlights problems like incorrect entity association and incomplete information presentation. Unlike common synthetic datasets, ours captures the complexity and nuances found in real-world data. We generate informative and diverse attributes, summaries, and unstructured paragraphs in sequence, ensuring high quality. The alignment between generated summaries and paragraphs exceeds 96%, confirming the dataset's quality. Extensive experiments demonstrate the dataset's difficulty - state-of-the-art LLMs struggle to update summaries with an F1 higher than 80.4%. We will open source the benchmark and the evaluation metrics to help the community make progress on IES tasks.
Read more6/10/2024
📶
0
Wiki Entity Summarization Benchmark
Saeedeh Javadi, Atefeh Moradan, Mohammad Sorkhpar, Klim Zaporojets, Davide Mottin, Ira Assent
Entity summarization aims to compute concise summaries for entities in knowledge graphs. Existing datasets and benchmarks are often limited to a few hundred entities and discard graph structure in source knowledge graphs. This limitation is particularly pronounced when it comes to ground-truth summaries, where there exist only a few labeled summaries for evaluation and training. We propose WikES, a comprehensive benchmark comprising of entities, their summaries, and their connections. Additionally, WikES features a dataset generator to test entity summarization algorithms in different areas of the knowledge graph. Importantly, our approach combines graph algorithms and NLP models as well as different data sources such that WikES does not require human annotation, rendering the approach cost-effective and generalizable to multiple domains. Finally, WikES is scalable and capable of capturing the complexities of knowledge graphs in terms of topology and semantics. WikES features existing datasets for comparison. Empirical studies of entity summarization methods confirm the usefulness of our benchmark. Data, code, and models are available at: https://github.com/msorkhpar/wiki-entity-summarization.
Read more6/13/2024
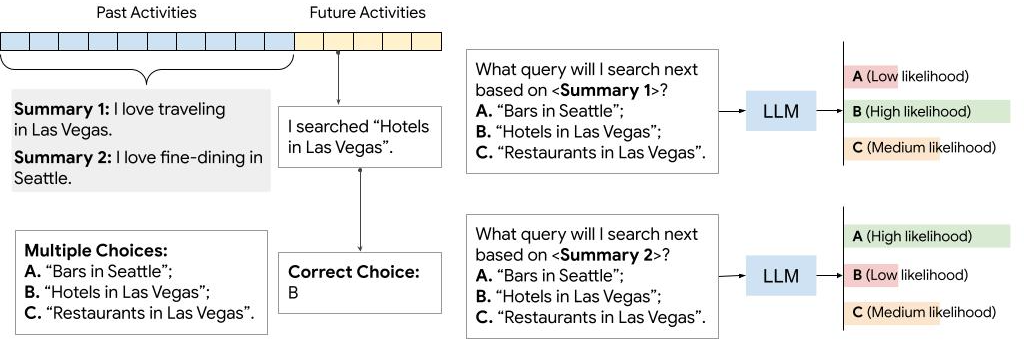
0
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches
Chao Wang, Neo Wu, Lin Ning, Jiaxing Wu, Luyang Liu, Jun Xie, Shawn O'Banion, Bradley Green
Large language models (LLMs) have shown remarkable capabilities in generating user summaries from a long list of raw user activity data. These summaries capture essential user information such as preferences and interests, and therefore are invaluable for LLM-based personalization applications, such as explainable recommender systems. However, the development of new summarization techniques is hindered by the lack of ground-truth labels, the inherent subjectivity of user summaries, and human evaluation which is often costly and time-consuming. To address these challenges, we introduce UserSumBench, a benchmark framework designed to facilitate iterative development of LLM-based summarization approaches. This framework offers two key components: (1) A reference-free summary quality metric. We show that this metric is effective and aligned with human preferences across three diverse datasets (MovieLens, Yelp and Amazon Review). (2) A novel robust summarization method that leverages time-hierarchical summarizer and self-critique verifier to produce high-quality summaries while eliminating hallucination. This method serves as a strong baseline for further innovation in summarization techniques.
Read more9/9/2024

0
CTISum: A New Benchmark Dataset For Cyber Threat Intelligence Summarization
Wei Peng, Junmei Ding, Wei Wang, Lei Cui, Wei Cai, Zhiyu Hao, Xiaochun Yun
Cyber Threat Intelligence (CTI) summarization task requires the system to generate concise and accurate highlights from raw intelligence data, which plays an important role in providing decision-makers with crucial information to quickly detect and respond to cyber threats in the cybersecurity domain. However, efficient techniques for summarizing CTI reports, including facts, analytical insights, attack processes, etc., have largely been unexplored, primarily due to the lack of available dataset. To this end, we present CTISum, a new benchmark for CTI summarization task. Considering the importance of attack process, a novel fine-grained subtask of attack process summarization is proposed to enable defenders to assess risk, identify security gaps, vulnerabilities, and so on. Specifically, we first design a multi-stage annotation pipeline to gather and annotate the CTI data, and then benchmark the CTISum with a collection of extractive and abstractive summarization methods. Experimental results show that current state-of-the-art models exhibit limitations when applied to CTISum, underscoring the fact that automatically producing concise summaries of CTI reports remains an open research challenge.
Read more8/14/2024