CTS: A Consistency-Based Medical Image Segmentation Model
2405.09056
0
0
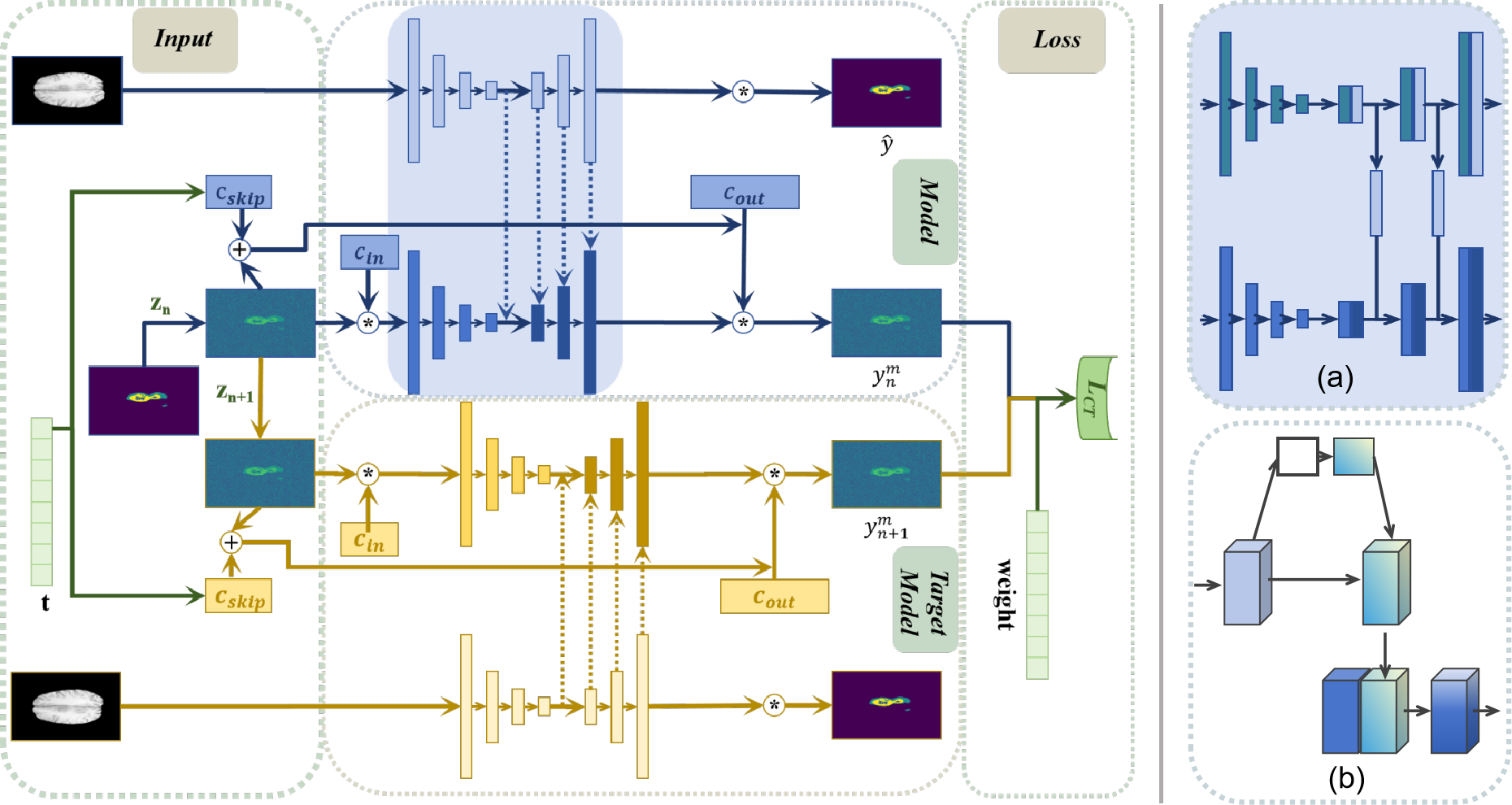
Abstract
In medical image segmentation tasks, diffusion models have shown significant potential. However, mainstream diffusion models suffer from drawbacks such as multiple sampling times and slow prediction results. Recently, consistency models, as a standalone generative network, have resolved this issue. Compared to diffusion models, consistency models can reduce the sampling times to once, not only achieving similar generative effects but also significantly speeding up training and prediction. However, they are not suitable for image segmentation tasks, and their application in the medical imaging field has not yet been explored. Therefore, this paper applies the consistency model to medical image segmentation tasks, designing multi-scale feature signal supervision modes and loss function guidance to achieve model convergence. Experiments have verified that the CTS model can obtain better medical image segmentation results with a single sampling during the test phase.
Create account to get full access
Overview
- The paper presents a new medical image segmentation model called Consistency-based Transformer Segmentation (CTS), which leverages consistency-based training to improve segmentation performance.
- CTS combines a diffusion-based model with a transformer-based architecture to capture both local and global image features for accurate segmentation.
- The model is evaluated on several medical imaging datasets and demonstrates state-of-the-art performance, particularly on challenging segmentation tasks.
Plain English Explanation
Medical image segmentation is the process of dividing an image into meaningful regions, such as identifying different organs or structures in a CT or MRI scan. This is an important task in healthcare that can help doctors better diagnose and treat patients. However, developing accurate and robust segmentation models can be challenging, especially for complex or noisy medical images.
The researchers behind this paper have proposed a new segmentation model called CTS that aims to address these challenges. CTS combines two powerful machine learning techniques - diffusion models and transformers - to capture both local and global image features. Diffusion models are a type of generative model that can learn the underlying structure of data, while transformers are a type of neural network that excels at processing sequential information like images.
The key innovation in CTS is the use of consistency-based training, which encourages the model to produce similar segmentation outputs even when the input image is slightly perturbed. This helps the model become more robust to noise and variations in the input data, leading to better performance on a variety of medical imaging tasks.
The researchers evaluate CTS on several medical image datasets and show that it outperforms other state-of-the-art segmentation models, particularly on challenging segmentation problems. This suggests that the combination of diffusion models, transformers, and consistency-based training can be a powerful approach for tackling medical image analysis tasks.
Technical Explanation
The CTS model architecture consists of a diffusion-based backbone and a transformer-based segmentation head. The diffusion-based backbone learns a generative model of the input images, capturing both local and global image features. The transformer-based segmentation head then takes the learned image representation and produces the final segmentation map.
The key innovation in CTS is the use of consistency-based training, where the model is trained to produce consistent segmentation outputs even when the input image is perturbed with small transformations, such as rotation, scaling, or noise. This encourages the model to learn robust and generalizable features, leading to improved performance on a variety of medical imaging tasks.
The researchers evaluate CTS on several medical image segmentation datasets, including skin lesion segmentation, brain tumor segmentation, and lung nodule segmentation. They compare the performance of CTS to other state-of-the-art segmentation models, such as those based on semi-supervised learning and consistency-based learning. The results show that CTS outperforms these other models, particularly on challenging segmentation tasks where the input images are noisy or have complex structures.
Critical Analysis
The paper provides a comprehensive evaluation of the CTS model and demonstrates its impressive performance on a range of medical imaging datasets. However, there are a few potential limitations and areas for further research:
-
Dataset Bias: The paper evaluates CTS on several publicly available medical imaging datasets, but it's unclear how well the model would generalize to other datasets or real-world clinical scenarios, where the data may have different characteristics or biases.
-
Interpretability: The CTS model relies on a complex combination of diffusion models and transformers, which can make it difficult to interpret the model's decision-making process. Improving the interpretability of the model could be an important area for future research.
-
Clinical Validation: While the paper demonstrates the technical performance of CTS, it does not provide any insights into the potential clinical impact or practical application of the model in real-world healthcare settings. Further research and collaboration with medical professionals would be necessary to fully assess the model's clinical utility.
-
Computational Efficiency: The use of diffusion models and transformers may come with increased computational requirements, which could limit the deployment of CTS in resource-constrained clinical environments. Exploring ways to optimize the model's efficiency could be a valuable area of future work.
Overall, the CTS model represents an interesting and promising approach to medical image segmentation, but continued research and validation will be necessary to fully realize its potential impact on healthcare.
Conclusion
The CTS model presented in this paper demonstrates the potential of combining diffusion models, transformers, and consistency-based training for medical image segmentation. By leveraging the strengths of these different techniques, CTS is able to achieve state-of-the-art performance on a variety of challenging medical imaging tasks.
The key innovations in CTS, such as the use of consistency-based training, make the model more robust and generalizable, which is crucial for practical deployment in healthcare settings. While further research is needed to address potential limitations and validate the model's clinical utility, the results presented in this paper suggest that CTS could be a valuable tool for assisting medical professionals in tasks like disease diagnosis, treatment planning, and patient monitoring.
As the field of medical image analysis continues to evolve, models like CTS that can leverage advances in machine learning and deep learning will likely play an increasingly important role in improving healthcare outcomes and patient experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
DiffSeg: A Segmentation Model for Skin Lesions Based on Diffusion Difference
Zhihao Shuai, Yinan Chen, Shunqiang Mao, Yihan Zho, Xiaohong Zhang
0
0
Weakly supervised medical image segmentation (MIS) using generative models is crucial for clinical diagnosis. However, the accuracy of the segmentation results is often limited by insufficient supervision and the complex nature of medical imaging. Existing models also only provide a single outcome, which does not allow for the measurement of uncertainty. In this paper, we introduce DiffSeg, a segmentation model for skin lesions based on diffusion difference which exploits diffusion model principles to ex-tract noise-based features from images with diverse semantic information. By discerning difference between these noise features, the model identifies diseased areas. Moreover, its multi-output capability mimics doctors' annotation behavior, facilitating the visualization of segmentation result consistency and ambiguity. Additionally, it quantifies output uncertainty using Generalized Energy Distance (GED), aiding interpretability and decision-making for physicians. Finally, the model integrates outputs through the Dense Conditional Random Field (DenseCRF) algorithm to refine the segmentation boundaries by considering inter-pixel correlations, which improves the accuracy and optimizes the segmentation results. We demonstrate the effectiveness of DiffSeg on the ISIC 2018 Challenge dataset, outperforming state-of-the-art U-Net-based methods.
4/26/2024

Consistency Models Made Easy
Zhengyang Geng, Ashwini Pokle, William Luo, Justin Lin, J. Zico Kolter
0
0
Consistency models (CMs) are an emerging class of generative models that offer faster sampling than traditional diffusion models. CMs enforce that all points along a sampling trajectory are mapped to the same initial point. But this target leads to resource-intensive training: for example, as of 2024, training a SoTA CM on CIFAR-10 takes one week on 8 GPUs. In this work, we propose an alternative scheme for training CMs, vastly improving the efficiency of building such models. Specifically, by expressing CM trajectories via a particular differential equation, we argue that diffusion models can be viewed as a special case of CMs with a specific discretization. We can thus fine-tune a consistency model starting from a pre-trained diffusion model and progressively approximate the full consistency condition to stronger degrees over the training process. Our resulting method, which we term Easy Consistency Tuning (ECT), achieves vastly improved training times while indeed improving upon the quality of previous methods: for example, ECT achieves a 2-step FID of 2.73 on CIFAR10 within 1 hour on a single A100 GPU, matching Consistency Distillation trained of hundreds of GPU hours. Owing to this computational efficiency, we investigate the scaling law of CMs under ECT, showing that they seem to obey classic power law scaling, hinting at their ability to improve efficiency and performance at larger scales. Code (https://github.com/locuslab/ect) is available.
6/21/2024
📈
Semantic Approach to Quantifying the Consistency of Diffusion Model Image Generation
Brinnae Bent
0
0
In this study, we identify the need for an interpretable, quantitative score of the repeatability, or consistency, of image generation in diffusion models. We propose a semantic approach, using a pairwise mean CLIP (Contrastive Language-Image Pretraining) score as our semantic consistency score. We applied this metric to compare two state-of-the-art open-source image generation diffusion models, Stable Diffusion XL and PixArt-{alpha}, and we found statistically significant differences between the semantic consistency scores for the models. Agreement between the Semantic Consistency Score selected model and aggregated human annotations was 94%. We also explored the consistency of SDXL and a LoRA-fine-tuned version of SDXL and found that the fine-tuned model had significantly higher semantic consistency in generated images. The Semantic Consistency Score proposed here offers a measure of image generation alignment, facilitating the evaluation of model architectures for specific tasks and aiding in informed decision-making regarding model selection.
4/16/2024

Stable Diffusion Segmentation for Biomedical Images with Single-step Reverse Process
Tianyu Lin, Zhiguang Chen, Zhonghao Yan, Weijiang Yu, Fudan Zheng
0
0
Diffusion models have demonstrated their effectiveness across various generative tasks. However, when applied to medical image segmentation, these models encounter several challenges, including significant resource and time requirements. They also necessitate a multi-step reverse process and multiple samples to produce reliable predictions. To address these challenges, we introduce the first latent diffusion segmentation model, named SDSeg, built upon stable diffusion (SD). SDSeg incorporates a straightforward latent estimation strategy to facilitate a single-step reverse process and utilizes latent fusion concatenation to remove the necessity for multiple samples. Extensive experiments indicate that SDSeg surpasses existing state-of-the-art methods on five benchmark datasets featuring diverse imaging modalities. Remarkably, SDSeg is capable of generating stable predictions with a solitary reverse step and sample, epitomizing the model's stability as implied by its name. The code is available at https://github.com/lin-tianyu/Stable-Diffusion-Seg
6/28/2024