Cultural Conditioning or Placebo? On the Effectiveness of Socio-Demographic Prompting
2406.11661
0
0
Abstract
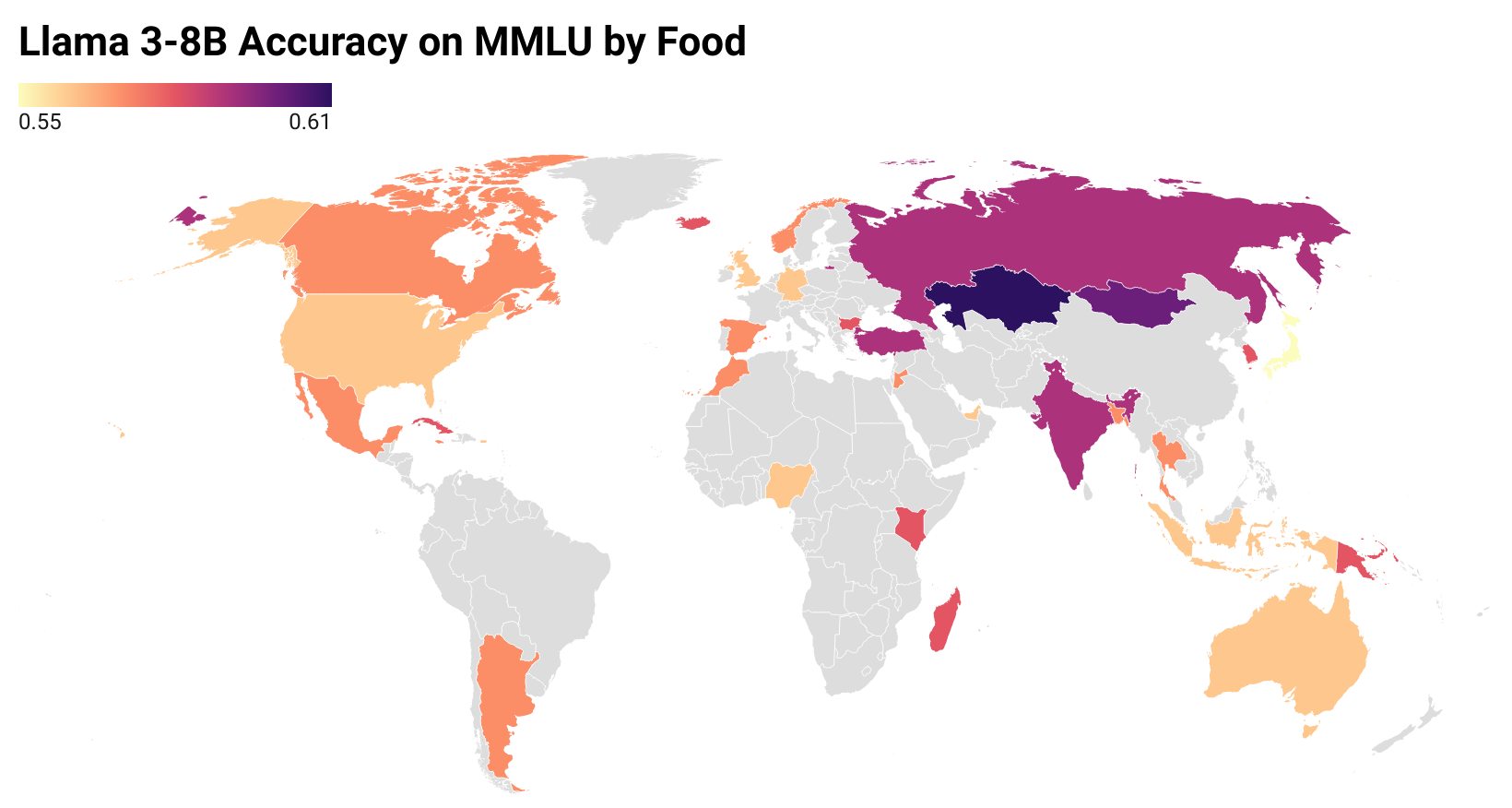
Socio-demographic prompting is a commonly employed approach to study cultural biases in LLMs as well as for aligning models to certain cultures. In this paper, we systematically probe four LLMs (Llama 3, Mistral v0.2, GPT-3.5 Turbo and GPT-4) with prompts that are conditioned on culturally sensitive and non-sensitive cues, on datasets that are supposed to be culturally sensitive (EtiCor and CALI) or neutral (MMLU and ETHICS). We observe that all models except GPT-4 show significant variations in their responses on both kinds of datasets for both kinds of prompts, casting doubt on the robustness of the culturally-conditioned prompting as a method for eliciting cultural bias in models or as an alignment strategy. The work also calls rethinking the control experiment design to tease apart the cultural conditioning of responses from placebo effect, i.e., random perturbations of model responses due to arbitrary tokens in the prompt.
Create account to get full access
Overview
- This paper investigates the effectiveness of socio-demographic prompting on language models, exploring whether it leads to cultural conditioning or a placebo effect.
- The researchers conduct experiments to understand how prompts related to the user's demographics (e.g., age, gender, ethnicity) impact the outputs of language models.
- The findings shed light on the complex interplay between language, culture, and artificial intelligence systems, with implications for fair and ethical AI development.
Plain English Explanation
The paper examines whether providing a language model with information about a user's background, such as their age, gender, or ethnicity, affects the model's responses. This is an important question because language models are increasingly used in real-world applications, and their outputs can potentially reflect and perpetuate societal biases.
The researchers conducted experiments where they gave language models prompts related to the user's demographics, and then analyzed the model's responses. They wanted to see if the model would tailor its language and content to align with the user's background, a phenomenon known as "cultural conditioning." Alternatively, the prompts could simply have a "placebo effect," where the model's responses are influenced by the user's perceived identity but not necessarily their actual background.
By understanding the nature of this effect, the researchers hope to shed light on how language models can be designed and used in a more fair and ethical way. The findings have implications for the development of AI systems that can communicate effectively and responsibly with diverse users.
Technical Explanation
The paper explores the concept of "socio-demographic prompting," where language models are provided with information about a user's age, gender, ethnicity, or other demographic characteristics as part of the input. The researchers investigate whether this type of prompting leads to "cultural conditioning," where the model's outputs are tailored to align with the user's background, or a "placebo effect," where the model's responses are influenced by the perceived user identity but not necessarily their actual demographics.
The researchers conducted a series of experiments using large language models, where they varied the socio-demographic prompts provided to the models and analyzed the resulting outputs. They used both automated metrics and human evaluations to assess the impact of the prompts on factors such as language style, sentiment, and topical content.
The findings suggest that socio-demographic prompting can have a significant influence on language model outputs, with both cultural conditioning and placebo effects observed. The extent and nature of these effects were found to depend on factors such as the specific demographic characteristics, the task or context, and the individual model being used.
The paper's insights have important implications for the development of fair and ethical AI systems, as they highlight the need to carefully consider the effects of demographic information on model behavior. The researchers discuss potential mitigations and design principles to address these issues, such as the use of "prompt engineering" and more inclusive training data.
Critical Analysis
The paper provides a nuanced and thoughtful exploration of the complex interplay between language, culture, and artificial intelligence systems. The experimental approach and analysis are generally sound, and the findings contribute valuable insights to the growing body of research on bias and fairness in language models.
However, the paper acknowledges several limitations and areas for further research. For example, the experiments were conducted on a relatively small set of language models and prompts, and the findings may not generalize to all AI systems or applications. Additionally, the paper does not delve deeply into the underlying mechanisms driving the observed effects, which could be an area for future investigation.
Another potential concern is the potential for misuse or misinterpretation of the findings. While the researchers emphasize the importance of fair and ethical AI development, the results could be misused to perpetuate harmful stereotypes or biases. It is crucial that the research community and policymakers work together to ensure that these insights are applied responsibly and in a way that promotes inclusivity and representation.
Overall, the paper makes a valuable contribution to the field and raises important questions that warrant further exploration. Continued research and open dialogue on these issues will be essential for developing AI systems that are truly equitable and beneficial for all members of society.
Conclusion
This paper provides a thought-provoking examination of the impact of socio-demographic prompting on language models, exploring the complex interplay between culture, language, and AI. The findings suggest that the way language models are prompted with information about a user's background can significantly influence their outputs, leading to both cultural conditioning and placebo effects.
The insights from this research have important implications for the development of fair and ethical AI systems, as they highlight the need to carefully consider the effects of demographic information on model behavior. By understanding these dynamics, researchers and practitioners can work to design AI systems that are more inclusive, responsive, and beneficial to users from diverse backgrounds.
While the paper acknowledges limitations and areas for further study, it represents an important step forward in the ongoing effort to ensure that artificial intelligence technologies are developed and deployed in a way that promotes equity, representation, and social good. As the use of language models continues to grow, this work serves as a valuable contribution to the ongoing discourse on the responsible and ethical development of AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CULTURE-GEN: Revealing Global Cultural Perception in Language Models through Natural Language Prompting
Huihan Li, Liwei Jiang, Jena D. Huang, Hyunwoo Kim, Sebastin Santy, Taylor Sorensen, Bill Yuchen Lin, Nouha Dziri, Xiang Ren, Yejin Choi
0
0
As the utilization of large language models (LLMs) has proliferated worldwide, it is crucial for them to have adequate knowledge and fair representation for diverse global cultures. In this work, we uncover culture perceptions of three SOTA models on 110 countries and regions on 8 culture-related topics through culture-conditioned generations, and extract symbols from these generations that are associated to each culture by the LLM. We discover that culture-conditioned generation consist of linguistic markers that distinguish marginalized cultures apart from default cultures. We also discover that LLMs have an uneven degree of diversity in the culture symbols, and that cultures from different geographic regions have different presence in LLMs' culture-agnostic generation. Our findings promote further research in studying the knowledge and fairness of global culture perception in LLMs. Code and Data can be found in: https://github.com/huihanlhh/Culture-Gen/
4/30/2024
💬
New!Social Bias Evaluation for Large Language Models Requires Prompt Variations
Rem Hida, Masahiro Kaneko, Naoaki Okazaki
0
0
Warning: This paper contains examples of stereotypes and biases. Large Language Models (LLMs) exhibit considerable social biases, and various studies have tried to evaluate and mitigate these biases accurately. Previous studies use downstream tasks as prompts to examine the degree of social biases for evaluation and mitigation. While LLMs' output highly depends on prompts, previous studies evaluating and mitigating bias have often relied on a limited variety of prompts. In this paper, we investigate the sensitivity of LLMs when changing prompt variations (task instruction and prompt, few-shot examples, debias-prompt) by analyzing task performance and social bias of LLMs. Our experimental results reveal that LLMs are highly sensitive to prompts to the extent that the ranking of LLMs fluctuates when comparing models for task performance and social bias. Additionally, we show that LLMs have tradeoffs between performance and social bias caused by the prompts. Less bias from prompt setting may result in reduced performance. Moreover, the ambiguity of instances is one of the reasons for this sensitivity to prompts in advanced LLMs, leading to various outputs. We recommend using diverse prompts, as in this study, to compare the effects of prompts on social bias in LLMs.
7/4/2024
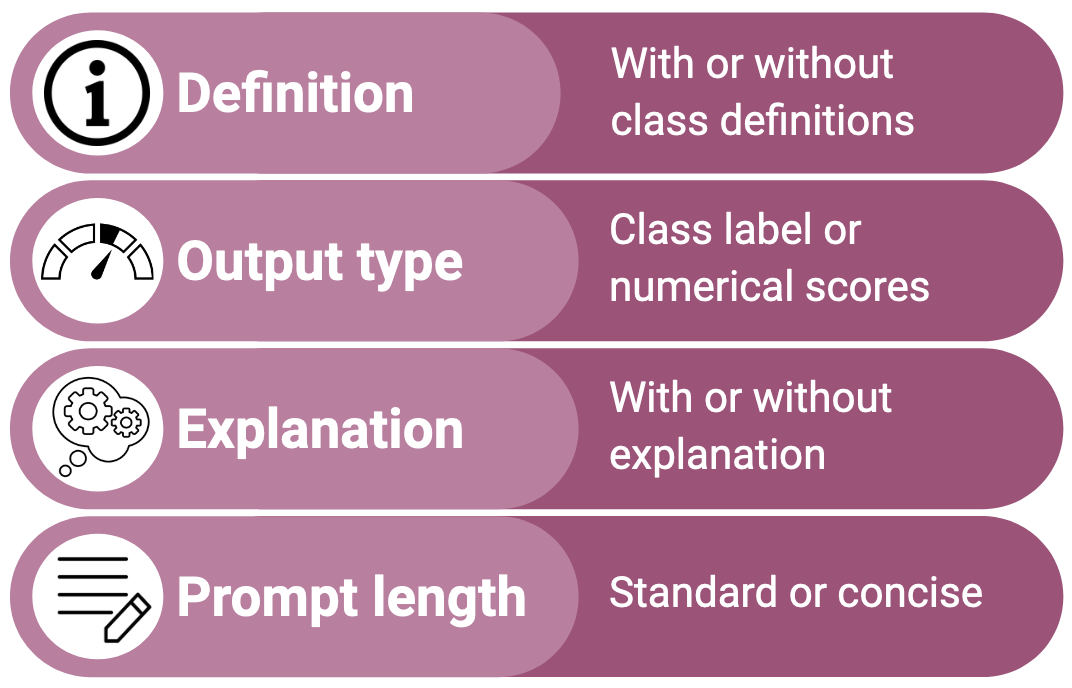
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
0
0
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
6/19/2024
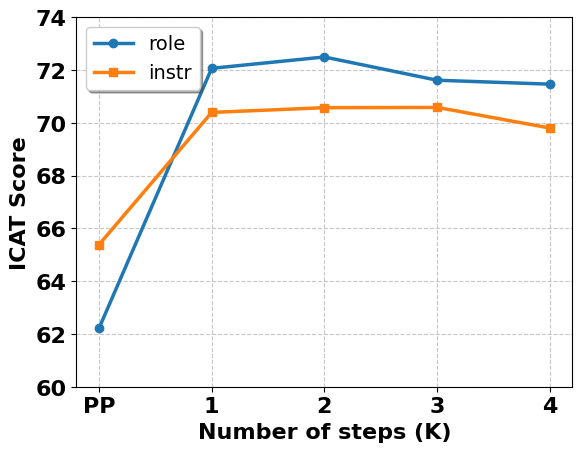
Thinking Fair and Slow: On the Efficacy of Structured Prompts for Debiasing Language Models
Shaz Furniturewala, Surgan Jandial, Abhinav Java, Pragyan Banerjee, Simra Shahid, Sumit Bhatia, Kokil Jaidka
0
0
Existing debiasing techniques are typically training-based or require access to the model's internals and output distributions, so they are inaccessible to end-users looking to adapt LLM outputs for their particular needs. In this study, we examine whether structured prompting techniques can offer opportunities for fair text generation. We evaluate a comprehensive end-user-focused iterative framework of debiasing that applies System 2 thinking processes for prompts to induce logical, reflective, and critical text generation, with single, multi-step, instruction, and role-based variants. By systematically evaluating many LLMs across many datasets and different prompting strategies, we show that the more complex System 2-based Implicative Prompts significantly improve over other techniques demonstrating lower mean bias in the outputs with competitive performance on the downstream tasks. Our work offers research directions for the design and the potential of end-user-focused evaluative frameworks for LLM use.
5/20/2024