CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts

0
📉
Sign in to get full access
Overview
- Researchers propose CuMo, a new approach to improving multimodal large language models (LLMs) that focuses on enhancing the vision encoder and MLP connector, rather than just scaling up the text-image pair data.
- CuMo incorporates Co-upcycled Top-K sparsely-gated Mixture-of-Experts (MoE) blocks into both the vision encoder and the MLP connector, which improves model scalability during training while keeping inference costs similar to smaller models.
- CuMo outperforms state-of-the-art multimodal LLMs on various VQA and visual-instruction-following benchmarks, while training exclusively on open-sourced datasets.
Plain English Explanation
Large language models (LLMs) that can handle both text and images, known as multimodal LLMs, have been a focus of recent research. However, the traditional approach of simply scaling up the amount of text-image data used to train these models is computationally expensive and may overlook important improvements that can be made to the vision side of the model.
Inspired by the success of Mixture-of-Experts (MoE) in improving the scalability of LLMs, the researchers propose a new model called CuMo. CuMo incorporates a specific type of MoE block, called Co-upcycled Top-K sparsely-gated Mixture-of-Experts, into both the vision encoder and the MLP connector of the multimodal LLM.
This MoE-based approach allows CuMo to improve the model's capabilities from the vision side, while maintaining similar inference costs to smaller models. The researchers also use a pre-training and initialization strategy, as well as auxiliary losses, to ensure the MoE blocks are balanced and effective.
By incorporating these innovations, CuMo is able to outperform state-of-the-art multimodal LLMs on a variety of benchmarks, all while using only open-sourced datasets for training. This suggests that focusing on improving the vision side of multimodal LLMs can be a fruitful area of research, beyond just scaling up the text-image data.
Technical Explanation
The researchers propose a new model called CuMo, which incorporates Co-upcycled Top-K sparsely-gated Mixture-of-Experts (MoE) blocks into both the vision encoder and the MLP connector of a multimodal large language model (LLM). This approach aims to enhance the model's capabilities from the vision side, rather than just focusing on scaling up the text-image pair data, which can be computationally expensive.
The MoE-based architecture used in CuMo has been shown to improve the scalability of LLMs during training, while keeping inference costs similar to smaller models. By applying this approach to the vision encoder and MLP connector, the researchers hypothesize that CuMo can achieve better performance on multimodal tasks compared to state-of-the-art models.
To ensure the MoE blocks are effectively utilized, CuMo first pre-trains the MLP blocks and then initializes each expert in the MoE block from the pre-trained MLP block during the visual instruction tuning stage. Additionally, the researchers use auxiliary losses to encourage a balanced loading of the experts in the MoE blocks.
The researchers evaluate CuMo on various VQA and visual-instruction-following benchmarks, and find that it outperforms state-of-the-art multimodal LLMs across different model size groups, all while training exclusively on open-sourced datasets. This suggests that the proposed approach of enhancing the vision side of multimodal LLMs can be a promising direction for improving the performance of these models.
Critical Analysis
The paper presents a compelling approach to improving multimodal LLMs by focusing on the vision encoder and MLP connector, rather than just scaling up the text-image pair data. The use of MoE blocks in these critical components of the model is an innovative solution that addresses the computational expense and scalability challenges associated with the traditional scaling approach.
However, the paper does not provide a detailed analysis of the potential limitations or caveats of the CuMo approach. For example, it would be useful to understand the impact of the pre-training and initialization strategy on the overall performance, and whether there are any trade-offs or constraints that arise from the use of MoE blocks in the vision encoder and MLP connector.
Additionally, the paper could have delved deeper into the potential implications and applications of the CuMo approach beyond the specific benchmarks evaluated. While the results are impressive, it would be valuable to explore how this approach might translate to real-world scenarios and the broader impact it could have on the development of more capable and efficient multimodal LLMs.
Overall, the CuMo approach represents a promising direction for advancing the field of multimodal LLMs, and the open-sourcing of the code and model weights is a commendable step towards enabling further research and development in this area. As with any new technique, it will be important for the research community to critically examine and build upon the insights provided in this paper to continue pushing the boundaries of what is possible with multimodal language models.
Conclusion
The researchers have proposed a novel approach called CuMo that aims to enhance the performance of multimodal large language models (LLMs) by focusing on improving the vision encoder and MLP connector, rather than just scaling up the text-image pair data. By incorporating Co-upcycled Top-K sparsely-gated Mixture-of-Experts (MoE) blocks into these critical components, CuMo is able to improve model scalability during training while maintaining similar inference costs to smaller models.
The results demonstrate that CuMo outperforms state-of-the-art multimodal LLMs across various benchmarks, suggesting that this approach of enhancing the vision side of the model can be a fruitful direction for advancing the field of multimodal language modeling. The open-sourcing of the CuMo code and model weights is a valuable contribution, as it will enable further research and development in this area.
While the paper presents a compelling solution, it could have delved deeper into the potential limitations, caveats, and broader implications of the CuMo approach. Nonetheless, this work represents an important step forward in the quest to develop more capable and efficient multimodal language models that can seamlessly integrate text and visual information, with potential applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts
Jiachen Li, Xinyao Wang, Sijie Zhu, Chia-Wen Kuo, Lu Xu, Fan Chen, Jitesh Jain, Humphrey Shi, Longyin Wen
Recent advancements in Multimodal Large Language Models (LLMs) have focused primarily on scaling by increasing text-image pair data and enhancing LLMs to improve performance on multimodal tasks. However, these scaling approaches are computationally expensive and overlook the significance of improving model capabilities from the vision side. Inspired by the successful applications of Mixture-of-Experts (MoE) in LLMs, which improves model scalability during training while keeping inference costs similar to those of smaller models, we propose CuMo. CuMo incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into both the vision encoder and the MLP connector, thereby enhancing the multimodal LLMs with minimal additional activated parameters during inference. CuMo first pre-trains the MLP blocks and then initializes each expert in the MoE block from the pre-trained MLP block during the visual instruction tuning stage. Auxiliary losses are used to ensure a balanced loading of experts. CuMo outperforms state-of-the-art multimodal LLMs across various VQA and visual-instruction-following benchmarks using models within each model size group, all while training exclusively on open-sourced datasets. The code and model weights for CuMo are open-sourced at https://github.com/SHI-Labs/CuMo.
Read more5/10/2024
0
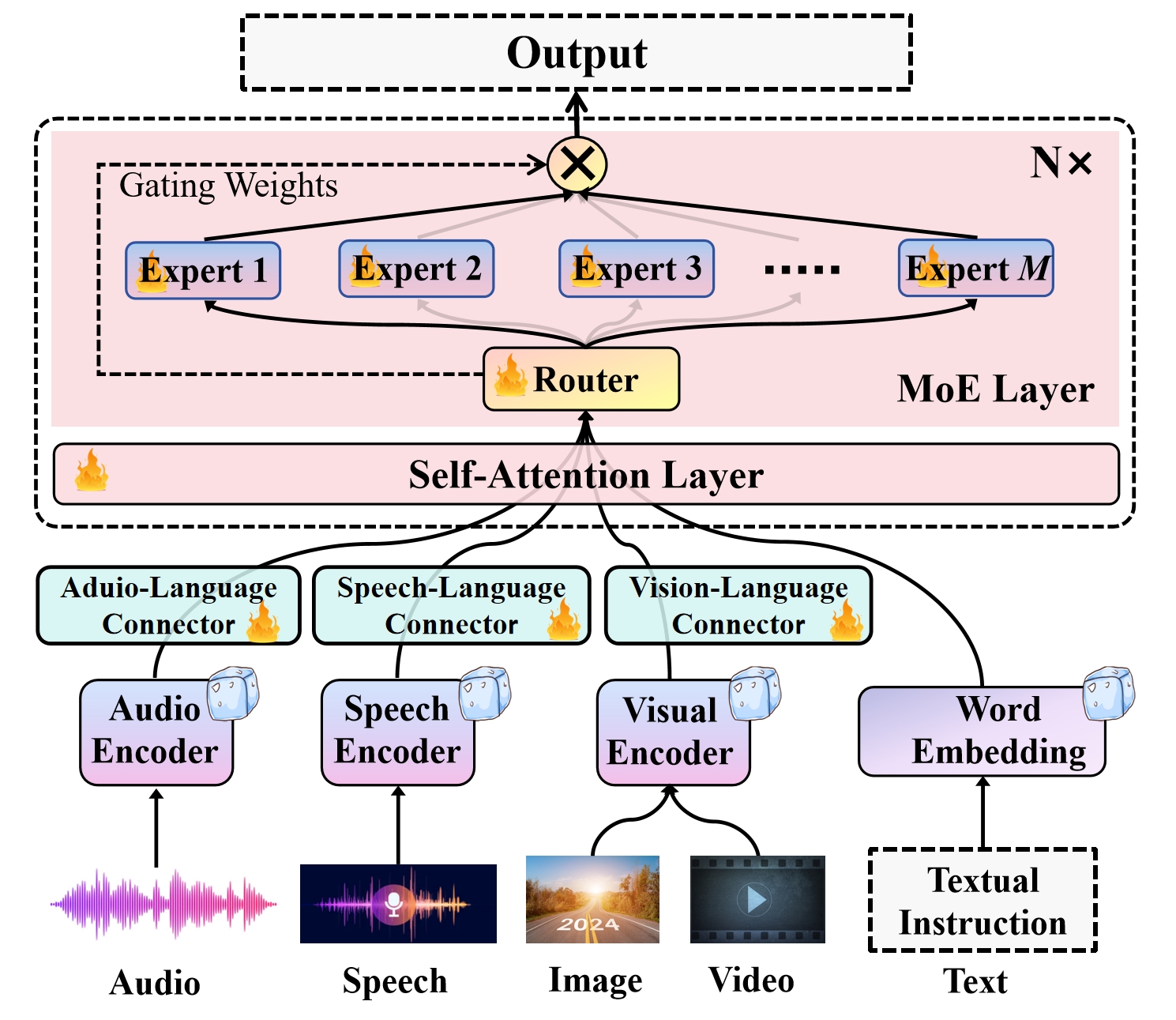
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
Read more5/21/2024

0
MoExtend: Tuning New Experts for Modality and Task Extension
Shanshan Zhong, Shanghua Gao, Zhongzhan Huang, Wushao Wen, Marinka Zitnik, Pan Zhou
Large language models (LLMs) excel in various tasks but are primarily trained on text data, limiting their application scope. Expanding LLM capabilities to include vision-language understanding is vital, yet training them on multimodal data from scratch is challenging and costly. Existing instruction tuning methods, e.g., LLAVA, often connects a pretrained CLIP vision encoder and LLMs via fully fine-tuning LLMs to bridge the modality gap. However, full fine-tuning is plagued by catastrophic forgetting, i.e., forgetting previous knowledge, and high training costs particularly in the era of increasing tasks and modalities. To solve this issue, we introduce MoExtend, an effective framework designed to streamline the modality adaptation and extension of Mixture-of-Experts (MoE) models. MoExtend seamlessly integrates new experts into pre-trained MoE models, endowing them with novel knowledge without the need to tune pretrained models such as MoE and vision encoders. This approach enables rapid adaptation and extension to new modal data or tasks, effectively addressing the challenge of accommodating new modalities within LLMs. Furthermore, MoExtend avoids tuning pretrained models, thus mitigating the risk of catastrophic forgetting. Experimental results demonstrate the efficacy and efficiency of MoExtend in enhancing the multimodal capabilities of LLMs, contributing to advancements in multimodal AI research. Code: https://github.com/zhongshsh/MoExtend.
Read more8/9/2024

0
MoVA: Adapting Mixture of Vision Experts to Multimodal Context
Zhuofan Zong, Bingqi Ma, Dazhong Shen, Guanglu Song, Hao Shao, Dongzhi Jiang, Hongsheng Li, Yu Liu
As the key component in multimodal large language models (MLLMs), the ability of the visual encoder greatly affects MLLM's understanding on diverse image content. Although some large-scale pretrained vision encoders such as vision encoders in CLIP and DINOv2 have brought promising performance, we found that there is still no single vision encoder that can dominate various image content understanding, e.g., the CLIP vision encoder leads to outstanding results on general image understanding but poor performance on document or chart content. To alleviate the bias of CLIP vision encoder, we first delve into the inherent behavior of different pre-trained vision encoders and then propose the MoVA, a powerful and novel MLLM, adaptively routing and fusing task-specific vision experts with a coarse-to-fine mechanism. In the coarse-grained stage, we design a context-aware expert routing strategy to dynamically select the most suitable vision experts according to the user instruction, input image, and expertise of vision experts. This benefits from the powerful model function understanding ability of the large language model (LLM) equipped with expert-routing low-rank adaptation (LoRA). In the fine-grained stage, we elaborately conduct the mixture-of-vision-expert adapter (MoV-Adapter) to extract and fuse task-specific knowledge from various experts. This coarse-to-fine paradigm effectively leverages representations from experts based on multimodal context and model expertise, further enhancing the generalization ability. We conduct extensive experiments to evaluate the effectiveness of the proposed approach. Without any bells and whistles, MoVA can achieve significant performance gains over current state-of-the-art methods in a wide range of challenging multimodal benchmarks. Codes and models will be available at https://github.com/TempleX98/MoVA.
Read more4/22/2024