MoExtend: Tuning New Experts for Modality and Task Extension

0

Sign in to get full access
Overview
- MoExtend is a method for tuning new experts for modality and task extension in large language models.
- It involves fine-tuning a mixture-of-experts (MoE) model on new tasks or modalities to enable it to handle additional capabilities.
- The paper presents experiments demonstrating MoExtend's effectiveness at extending MoE models to new settings.
Plain English Explanation
MoExtend is a technique for expanding the capabilities of large language models that use a mixture-of-experts (MoE) architecture. These models have different specialized "expert" components that handle different types of tasks or inputs.
With MoExtend, researchers can fine-tune the model by training new expert components to handle additional tasks or modalities, like image recognition or question answering. This allows the model to gain new skills without having to retrain the entire system from scratch.
The paper shows that MoExtend is effective at enabling MoE models to take on new capabilities, like adapting to new datasets or handling multimodal inputs (e.g. text and images). This suggests it could be a useful approach for scaling up multimodal language models and continually expanding their abilities.
Technical Explanation
The key idea behind MoExtend is to leverage the modular nature of MoE architectures to efficiently tune the model for new tasks or modalities. Rather than retraining the entire system, the researchers introduce new "expert" components that are specialized for the new capabilities.
They demonstrate MoExtend in the context of extending a vision-language MoE model to handle new image classification tasks. First, they pre-train the base MoE model on a large dataset. Then, they fine-tune the model by training new image classification experts while keeping the other components frozen.
The experiments show that this approach allows the model to acquire new visual skills without catastrophically forgetting its original language understanding abilities. The new experts can be selectively activated when the model encounters the new task or modality.
MoExtend builds on prior work on adapting MoE models to multimodal settings and scaling up mixture-of-experts architectures in general. The results suggest it is a promising technique for continually expanding the capabilities of language models in a modular and efficient way.
Critical Analysis
The paper provides a clear and well-designed evaluation of the MoExtend approach, demonstrating its effectiveness at enabling MoE models to acquire new skills. However, the experiments are limited to a specific vision-language setting, so further research would be needed to assess the generalizability of the technique.
Additionally, the paper does not deeply explore potential limitations or downsides of the MoExtend approach. For example, it's unclear how the method would scale as the number of tasks or modalities grows, or how to best manage the training of new experts to avoid interference with existing capabilities.
There are also open questions around the interpretability and transparency of models trained with MoExtend. Since new experts are added in a modular fashion, it may be challenging to understand the full decision-making process of the model.
Overall, the paper makes a compelling case for MoExtend as a useful technique for extending the capabilities of MoE-based language models. But further research is needed to better understand its broader applicability and potential drawbacks.
Conclusion
MoExtend is a method for efficiently tuning mixture-of-experts language models to handle new tasks and modalities. By introducing specialized new expert components, it allows the model to gain additional capabilities without catastrophically forgetting its original skills.
The experiments in the paper demonstrate the effectiveness of this approach, suggesting it could be a valuable tool for scaling up multimodal language models and continually expanding their abilities in a modular and efficient way. Further research is needed to explore the broader applicability and potential limitations of the MoExtend technique.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MoExtend: Tuning New Experts for Modality and Task Extension
Shanshan Zhong, Shanghua Gao, Zhongzhan Huang, Wushao Wen, Marinka Zitnik, Pan Zhou
Large language models (LLMs) excel in various tasks but are primarily trained on text data, limiting their application scope. Expanding LLM capabilities to include vision-language understanding is vital, yet training them on multimodal data from scratch is challenging and costly. Existing instruction tuning methods, e.g., LLAVA, often connects a pretrained CLIP vision encoder and LLMs via fully fine-tuning LLMs to bridge the modality gap. However, full fine-tuning is plagued by catastrophic forgetting, i.e., forgetting previous knowledge, and high training costs particularly in the era of increasing tasks and modalities. To solve this issue, we introduce MoExtend, an effective framework designed to streamline the modality adaptation and extension of Mixture-of-Experts (MoE) models. MoExtend seamlessly integrates new experts into pre-trained MoE models, endowing them with novel knowledge without the need to tune pretrained models such as MoE and vision encoders. This approach enables rapid adaptation and extension to new modal data or tasks, effectively addressing the challenge of accommodating new modalities within LLMs. Furthermore, MoExtend avoids tuning pretrained models, thus mitigating the risk of catastrophic forgetting. Experimental results demonstrate the efficacy and efficiency of MoExtend in enhancing the multimodal capabilities of LLMs, contributing to advancements in multimodal AI research. Code: https://github.com/zhongshsh/MoExtend.
Read more8/9/2024
📉
0
CuMo: Scaling Multimodal LLM with Co-Upcycled Mixture-of-Experts
Jiachen Li, Xinyao Wang, Sijie Zhu, Chia-Wen Kuo, Lu Xu, Fan Chen, Jitesh Jain, Humphrey Shi, Longyin Wen
Recent advancements in Multimodal Large Language Models (LLMs) have focused primarily on scaling by increasing text-image pair data and enhancing LLMs to improve performance on multimodal tasks. However, these scaling approaches are computationally expensive and overlook the significance of improving model capabilities from the vision side. Inspired by the successful applications of Mixture-of-Experts (MoE) in LLMs, which improves model scalability during training while keeping inference costs similar to those of smaller models, we propose CuMo. CuMo incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into both the vision encoder and the MLP connector, thereby enhancing the multimodal LLMs with minimal additional activated parameters during inference. CuMo first pre-trains the MLP blocks and then initializes each expert in the MoE block from the pre-trained MLP block during the visual instruction tuning stage. Auxiliary losses are used to ensure a balanced loading of experts. CuMo outperforms state-of-the-art multimodal LLMs across various VQA and visual-instruction-following benchmarks using models within each model size group, all while training exclusively on open-sourced datasets. The code and model weights for CuMo are open-sourced at https://github.com/SHI-Labs/CuMo.
Read more5/10/2024
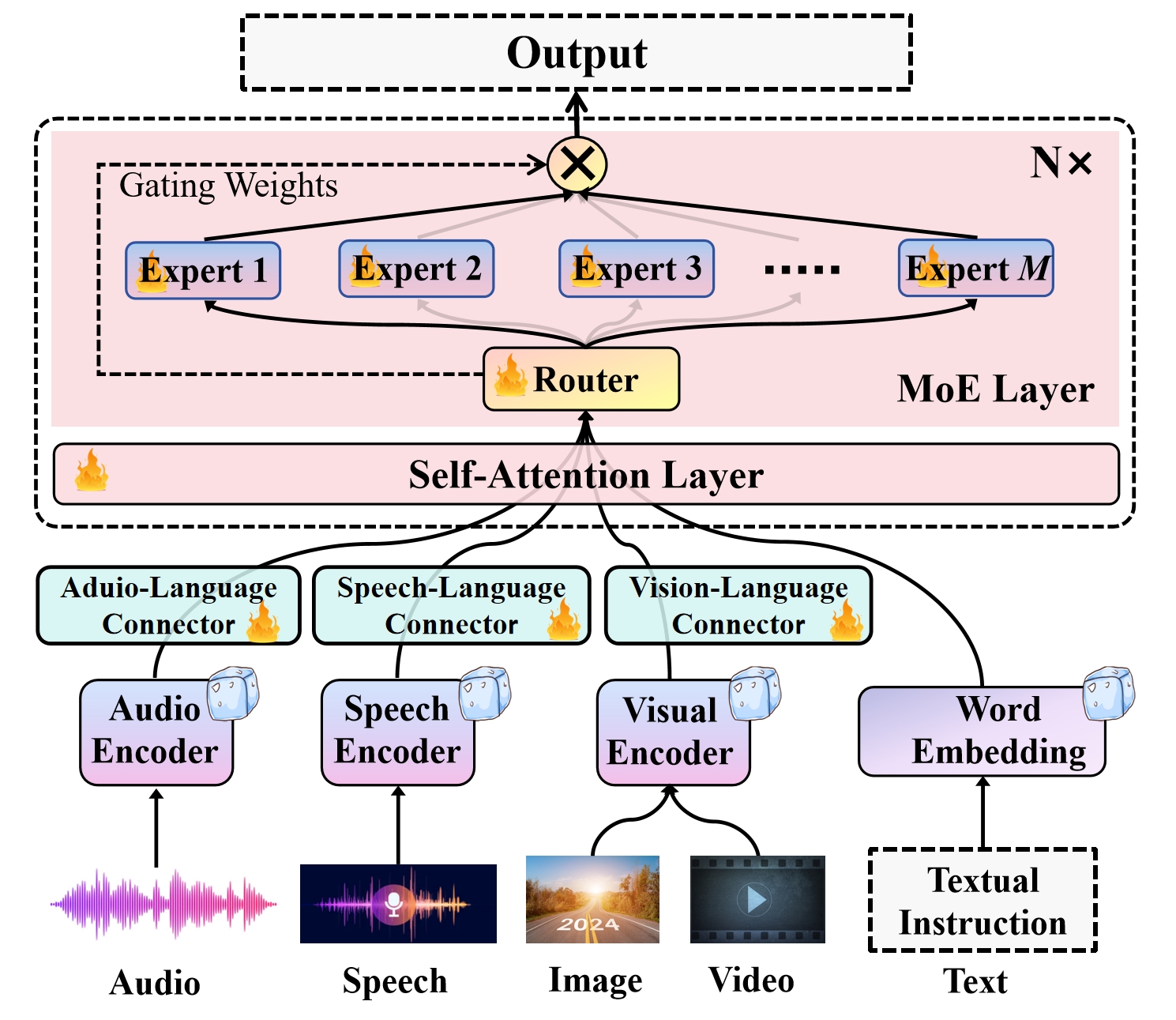
0
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
Read more5/21/2024

0
Boosting Continual Learning of Vision-Language Models via Mixture-of-Experts Adapters
Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, You He
Continual learning can empower vision-language models to continuously acquire new knowledge, without the need for access to the entire historical dataset. However, mitigating the performance degradation in large-scale models is non-trivial due to (i) parameter shifts throughout lifelong learning and (ii) significant computational burdens associated with full-model tuning. In this work, we present a parameter-efficient continual learning framework to alleviate long-term forgetting in incremental learning with vision-language models. Our approach involves the dynamic expansion of a pre-trained CLIP model, through the integration of Mixture-of-Experts (MoE) adapters in response to new tasks. To preserve the zero-shot recognition capability of vision-language models, we further introduce a Distribution Discriminative Auto-Selector (DDAS) that automatically routes in-distribution and out-of-distribution inputs to the MoE Adapter and the original CLIP, respectively. Through extensive experiments across various settings, our proposed method consistently outperforms previous state-of-the-art approaches while concurrently reducing parameter training burdens by 60%. Our code locates at https://github.com/JiazuoYu/MoE-Adapters4CL
Read more6/4/2024