The Curious Case of Nonverbal Abstract Reasoning with Multi-Modal Large Language Models

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) are being adopted in new domains and used for novel applications.
- A new generation of foundation models, called multi-modal large language models (MLLMs), are emerging.
- MLLMs integrate verbal and visual information, opening up new possibilities for complex reasoning abilities.
- However, our understanding of the reasoning abilities of MLLMs is limited.
Plain English Explanation
[A plain English explanation of the paper's content, using analogies, examples, or metaphors to make complex concepts more accessible to a general audience.]
Large language models (LLMs) are like very advanced language-processing machines that can understand and generate human-like text. These models have been expanding into new areas and finding new ways to be useful. Now, a new generation of LLMs called multi-modal large language models (MLLMs) are emerging.
MLLMs are unique because they can work with both language and visual information, like images. This allows them to demonstrate more complex reasoning abilities that involve both words and visuals. For example, an MLLM might be able to look at an image and then describe what it sees in words, or even answer questions about the image.
However, even though MLLMs seem very promising, researchers still don't fully understand their reasoning abilities. They want to know how well these models can handle abstract, non-verbal reasoning tasks, like the kinds of logic puzzles that humans sometimes use to test their own cognitive abilities.
Technical Explanation
[A more detailed, technical explanation of the paper's content, including the experiment design, architecture, and key insights.]
In this study, the researchers assessed the non-verbal abstract reasoning abilities of open-source and closed-source MLLMs using variations of Raven's Progressive Matrices. Raven's Progressive Matrices are a type of logic puzzle that requires the ability to recognize patterns and relationships in visual information, without relying on language.
The researchers conducted experiments to see how well different MLLMs could solve these types of problems. They found that these tasks were quite challenging for the models, and there was a significant gap in performance between the open-source and closed-source MLLMs.
The researchers also uncovered some critical shortcomings in the visual and textual perceptions of the models, which led to them performing poorly on these abstract reasoning tasks. To try to improve the models' performance, the researchers experimented with different prompting techniques, such as "Chain-of-Thought" prompting. This led to a significant boost in the models' performance, in some cases up to 100%.
Critical Analysis
[A discussion of any caveats, limitations, or areas for further research mentioned in the paper, as well as any additional concerns or potential issues with the research that were not addressed.]
The paper highlights several important limitations and areas for further research. First, the researchers acknowledge that their understanding of the reasoning abilities of MLLMs is still quite limited. While the experiments using Raven's Progressive Matrices provided some insights, there may be other types of abstract reasoning tasks that these models excel at or struggle with.
Additionally, the researchers note that the visual and textual perception capabilities of the models were critical factors in their performance on these tasks. This suggests that further research is needed to better understand and improve these fundamental capabilities, which underlie the models' reasoning abilities.
Another potential issue is the significant gap in performance between the open-source and closed-source MLLMs. This raises questions about the transparency and fairness of the development of these powerful AI systems, and whether certain groups or organizations have access to more advanced models that the general public does not.
Overall, the paper highlights the need for continued research and a more nuanced understanding of the strengths, limitations, and potential biases of these emerging multi-modal language models.
Conclusion
[A summary of the main takeaways and their potential implications for the field and society at large.]
This study provides important insights into the current state of multi-modal large language models (MLLMs) and their ability to engage in abstract, non-verbal reasoning. The researchers found that these models still struggle with certain types of logic puzzles, despite their impressive language and visual processing capabilities.
The findings suggest that there is still much work to be done to fully understand and harness the potential of these powerful AI systems. As MLLMs continue to be developed and applied in new domains, it will be crucial to carefully assess their reasoning abilities, biases, and limitations, to ensure they are being used responsibly and ethically.
Ultimately, this research highlights the ongoing challenges and opportunities in the field of artificial intelligence, and the need for continued collaboration between researchers, developers, and the broader public to ensure that these technologies are designed and deployed in ways that benefit society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
The Curious Case of Nonverbal Abstract Reasoning with Multi-Modal Large Language Models
Kian Ahrabian, Zhivar Sourati, Kexuan Sun, Jiarui Zhang, Yifan Jiang, Fred Morstatter, Jay Pujara
While large language models (LLMs) are still being adopted to new domains and utilized in novel applications, we are experiencing an influx of the new generation of foundation models, namely multi-modal large language models (MLLMs). These models integrate verbal and visual information, opening new possibilities to demonstrate more complex reasoning abilities at the intersection of the two modalities. However, despite the revolutionizing prospect of MLLMs, our understanding of their reasoning abilities is limited. In this study, we assess the nonverbal abstract reasoning abilities of open-source and closed-source MLLMs using variations of Raven's Progressive Matrices. Our experiments reveal the challenging nature of such problems for MLLMs while showcasing the immense gap between open-source and closed-source models. We also uncover critical shortcomings of visual and textual perceptions, subjecting the models to low-performance ceilings. Finally, to improve MLLMs' performance, we experiment with different methods, such as Chain-of-Thought prompting, leading to a significant (up to 100%) boost in performance. Our code and datasets are available at https://github.com/usc-isi-i2/isi-mmlm-rpm.
Read more8/23/2024
0
What is the Visual Cognition Gap between Humans and Multimodal LLMs?
Xu Cao, Bolin Lai, Wenqian Ye, Yunsheng Ma, Joerg Heintz, Jintai Chen, Jianguo Cao, James M. Rehg
Recently, Multimodal Large Language Models (MLLMs) have shown great promise in language-guided perceptual tasks such as recognition, segmentation, and object detection. However, their effectiveness in addressing visual cognition problems that require high-level reasoning is not well-established. One such challenge is abstract visual reasoning (AVR) -- the cognitive ability to discern relationships among patterns in a set of images and extrapolate to predict subsequent patterns. This skill is crucial during the early neurodevelopmental stages of children. Inspired by the AVR tasks in Raven's Progressive Matrices (RPM) and Wechsler Intelligence Scale for Children (WISC), we propose a new dataset MaRs-VQA and a new benchmark VCog-Bench containing three datasets to evaluate the zero-shot AVR capability of MLLMs and compare their performance with existing human intelligent investigation. Our comparative experiments with different open-source and closed-source MLLMs on the VCog-Bench revealed a gap between MLLMs and human intelligence, highlighting the visual cognitive limitations of current MLLMs. We believe that the public release of VCog-Bench, consisting of MaRs-VQA, and the inference pipeline will drive progress toward the next generation of MLLMs with human-like visual cognition abilities.
Read more6/18/2024
0
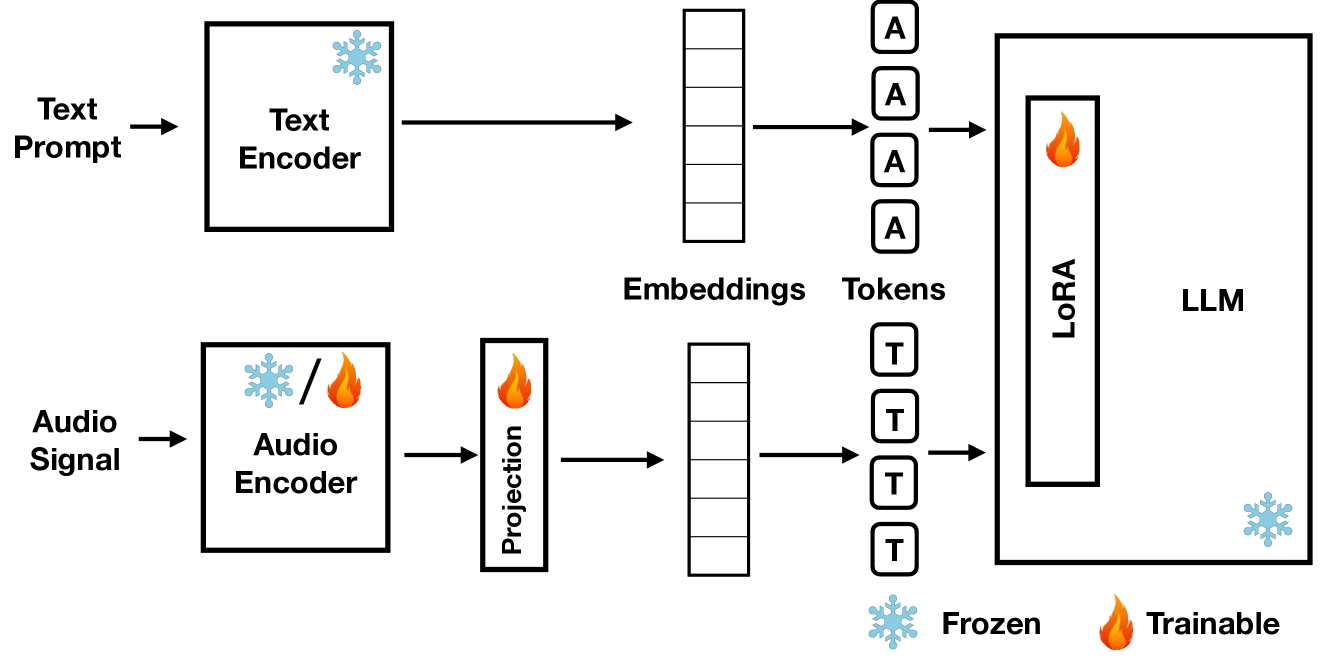
What do MLLMs hear? Examining reasoning with text and sound components in Multimodal Large Language Models
Enis Berk c{C}oban, Michael I. Mandel, Johanna Devaney
Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities, notably in connecting ideas and adhering to logical rules to solve problems. These models have evolved to accommodate various data modalities, including sound and images, known as multimodal LLMs (MLLMs), which are capable of describing images or sound recordings. Previous work has demonstrated that when the LLM component in MLLMs is frozen, the audio or visual encoder serves to caption the sound or image input facilitating text-based reasoning with the LLM component. We are interested in using the LLM's reasoning capabilities in order to facilitate classification. In this paper, we demonstrate through a captioning/classification experiment that an audio MLLM cannot fully leverage its LLM's text-based reasoning when generating audio captions. We also consider how this may be due to MLLMs separately representing auditory and textual information such that it severs the reasoning pathway from the LLM to the audio encoder.
Read more6/10/2024
0
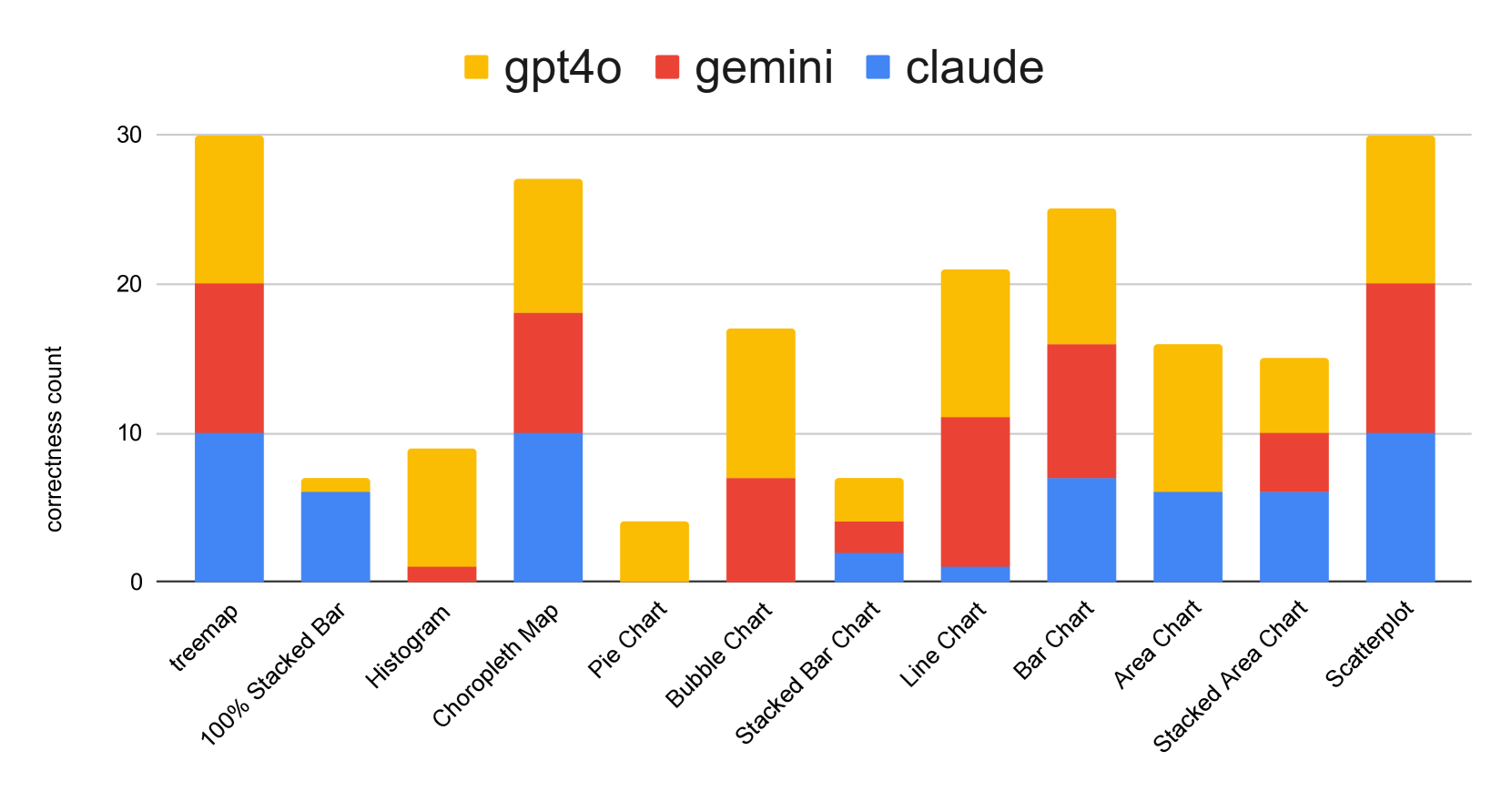
Visualization Literacy of Multimodal Large Language Models: A Comparative Study
Zhimin Li, Haichao Miao, Valerio Pascucci, Shusen Liu
The recent introduction of multimodal large language models (MLLMs) combine the inherent power of large language models (LLMs) with the renewed capabilities to reason about the multimodal context. The potential usage scenarios for MLLMs significantly outpace their text-only counterparts. Many recent works in visualization have demonstrated MLLMs' capability to understand and interpret visualization results and explain the content of the visualization to users in natural language. In the machine learning community, the general vision capabilities of MLLMs have been evaluated and tested through various visual understanding benchmarks. However, the ability of MLLMs to accomplish specific visualization tasks based on visual perception has not been properly explored and evaluated, particularly, from a visualization-centric perspective. In this work, we aim to fill the gap by utilizing the concept of visualization literacy to evaluate MLLMs. We assess MLLMs' performance over two popular visualization literacy evaluation datasets (VLAT and mini-VLAT). Under the framework of visualization literacy, we develop a general setup to compare different multimodal large language models (e.g., GPT4-o, Claude 3 Opus, Gemini 1.5 Pro) as well as against existing human baselines. Our study demonstrates MLLMs' competitive performance in visualization literacy, where they outperform humans in certain tasks such as identifying correlations, clusters, and hierarchical structures.
Read more7/17/2024