What do MLLMs hear? Examining reasoning with text and sound components in Multimodal Large Language Models

0
Sign in to get full access
Overview
- This paper examines how multimodal large language models (MLLMs) reason using both text and sound components.
- The researchers investigate the capabilities and limitations of MLLMs in understanding and reasoning about multimodal information.
- The paper provides insights into the inner workings of these complex models and highlights areas for further research and development.
Plain English Explanation
Multimodal large language models are a new class of artificial intelligence systems that can process and understand information from multiple sources, such as text and audio. These models have the potential to revolutionize how we interact with computers and access information.
In this paper, the researchers set out to explain how these multimodal models work and what they are capable of. They wanted to understand how MLLMs can use both text and sound to reason about the world and solve problems.
The researchers conducted various experiments to test the models' abilities. They found that MLLMs can indeed leverage both textual and audio information to make inferences and generate responses. However, the models also have limitations, and the researchers identified areas where further improvements are needed.
Understanding the strengths and weaknesses of MLLMs is crucial as these revolutionary technologies become more widespread. This research provides valuable insights that can help guide the transformation of large language models into cross-modal and cross-lingual systems capable of handling diverse types of information.
Technical Explanation
The paper presents an in-depth analysis of how multimodal large language models (MLLMs) reason using both text and sound components. The researchers designed a series of experiments to assess the models' ability to understand and reason about multimodal information.
The experimental setup involved presenting MLLMs with a combination of textual and audio inputs, such as descriptions of scenes accompanied by relevant sounds. The models were then asked to answer questions or generate responses that demonstrated their understanding of the multimodal information.
The results showed that MLLMs can effectively leverage both text and sound to make inferences and generate relevant outputs. The models were able to combine information from the different modalities to reach conclusions and provide meaningful responses.
However, the researchers also identified some limitations in the models' reasoning capabilities. In certain scenarios, the models struggled to fully integrate the textual and audio inputs, or they made inferences that were not fully aligned with the provided information.
The insights gained from this research can help guide the development of more advanced multimodal systems that can seamlessly process and reason about diverse types of information. By understanding the strengths and weaknesses of current MLLMs, researchers can work towards creating even more capable and versatile artificial intelligence systems.
Critical Analysis
The paper provides a valuable contribution to the understanding of multimodal large language models and their reasoning abilities. The experimental design and the insights gained offer a solid foundation for further research in this emerging field.
One potential limitation of the study is the specific set of tasks and scenarios used to evaluate the models. While the researchers aimed to cover a range of multimodal scenarios, there may be other situations or applications where the models' performance could be different. Expanding the scope of the experiments to include more diverse and complex tasks could yield additional insights.
Furthermore, the paper does not delve deeply into the potential biases or ethical considerations that may arise from the deployment of these multimodal systems. As these technologies become more prominent, it will be crucial to critically examine their societal implications and potential unintended consequences.
Overall, this research represents an important step forward in understanding the capabilities and limitations of multimodal large language models. By continuing to explore and push the boundaries of these systems, researchers can contribute to the development of more advanced and responsible artificial intelligence technologies.
Conclusion
This paper provides valuable insights into the reasoning capabilities of multimodal large language models (MLLMs) by examining their ability to process and understand both text and sound components. The researchers' findings demonstrate that these models can effectively leverage multimodal information to make inferences and generate relevant responses.
However, the study also highlights areas where MLLMs have room for improvement, such as fully integrating textual and audio inputs or making more nuanced and contextually appropriate inferences. As these technologies continue to evolve, understanding the strengths and limitations of MLLMs will be crucial for ensuring their responsible development and deployment.
The insights from this research can contribute to the ongoing development of more advanced and versatile artificial intelligence systems capable of seamlessly processing and reasoning about diverse types of information. By continuing to push the boundaries of multimodal AI, researchers and developers can unlock new possibilities for how humans interact with and benefit from these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
What do MLLMs hear? Examining reasoning with text and sound components in Multimodal Large Language Models
Enis Berk c{C}oban, Michael I. Mandel, Johanna Devaney
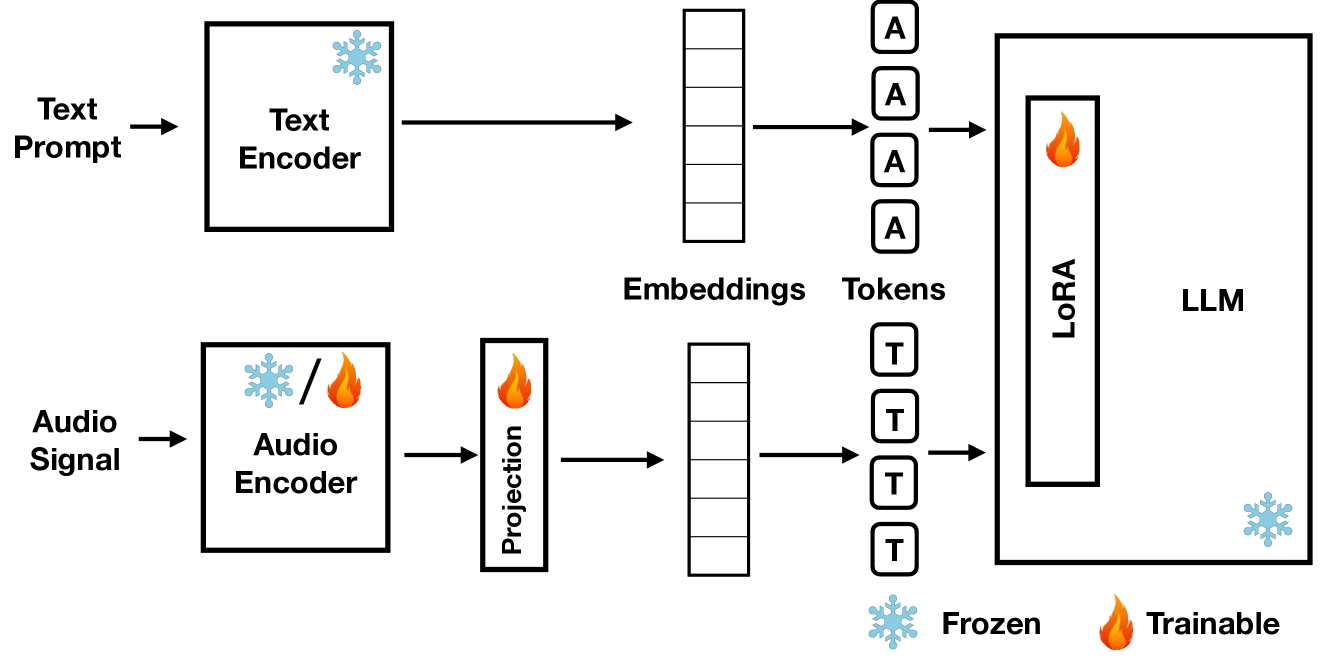
Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities, notably in connecting ideas and adhering to logical rules to solve problems. These models have evolved to accommodate various data modalities, including sound and images, known as multimodal LLMs (MLLMs), which are capable of describing images or sound recordings. Previous work has demonstrated that when the LLM component in MLLMs is frozen, the audio or visual encoder serves to caption the sound or image input facilitating text-based reasoning with the LLM component. We are interested in using the LLM's reasoning capabilities in order to facilitate classification. In this paper, we demonstrate through a captioning/classification experiment that an audio MLLM cannot fully leverage its LLM's text-based reasoning when generating audio captions. We also consider how this may be due to MLLMs separately representing auditory and textual information such that it severs the reasoning pathway from the LLM to the audio encoder.
Read more6/10/2024

0
A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
Read more4/3/2024
💬
0
The Curious Case of Nonverbal Abstract Reasoning with Multi-Modal Large Language Models
Kian Ahrabian, Zhivar Sourati, Kexuan Sun, Jiarui Zhang, Yifan Jiang, Fred Morstatter, Jay Pujara
While large language models (LLMs) are still being adopted to new domains and utilized in novel applications, we are experiencing an influx of the new generation of foundation models, namely multi-modal large language models (MLLMs). These models integrate verbal and visual information, opening new possibilities to demonstrate more complex reasoning abilities at the intersection of the two modalities. However, despite the revolutionizing prospect of MLLMs, our understanding of their reasoning abilities is limited. In this study, we assess the nonverbal abstract reasoning abilities of open-source and closed-source MLLMs using variations of Raven's Progressive Matrices. Our experiments reveal the challenging nature of such problems for MLLMs while showcasing the immense gap between open-source and closed-source models. We also uncover critical shortcomings of visual and textual perceptions, subjecting the models to low-performance ceilings. Finally, to improve MLLMs' performance, we experiment with different methods, such as Chain-of-Thought prompting, leading to a significant (up to 100%) boost in performance. Our code and datasets are available at https://github.com/usc-isi-i2/isi-mmlm-rpm.
Read more8/23/2024
0
A Survey on Evaluation of Multimodal Large Language Models
Jiaxing Huang, Jingyi Zhang
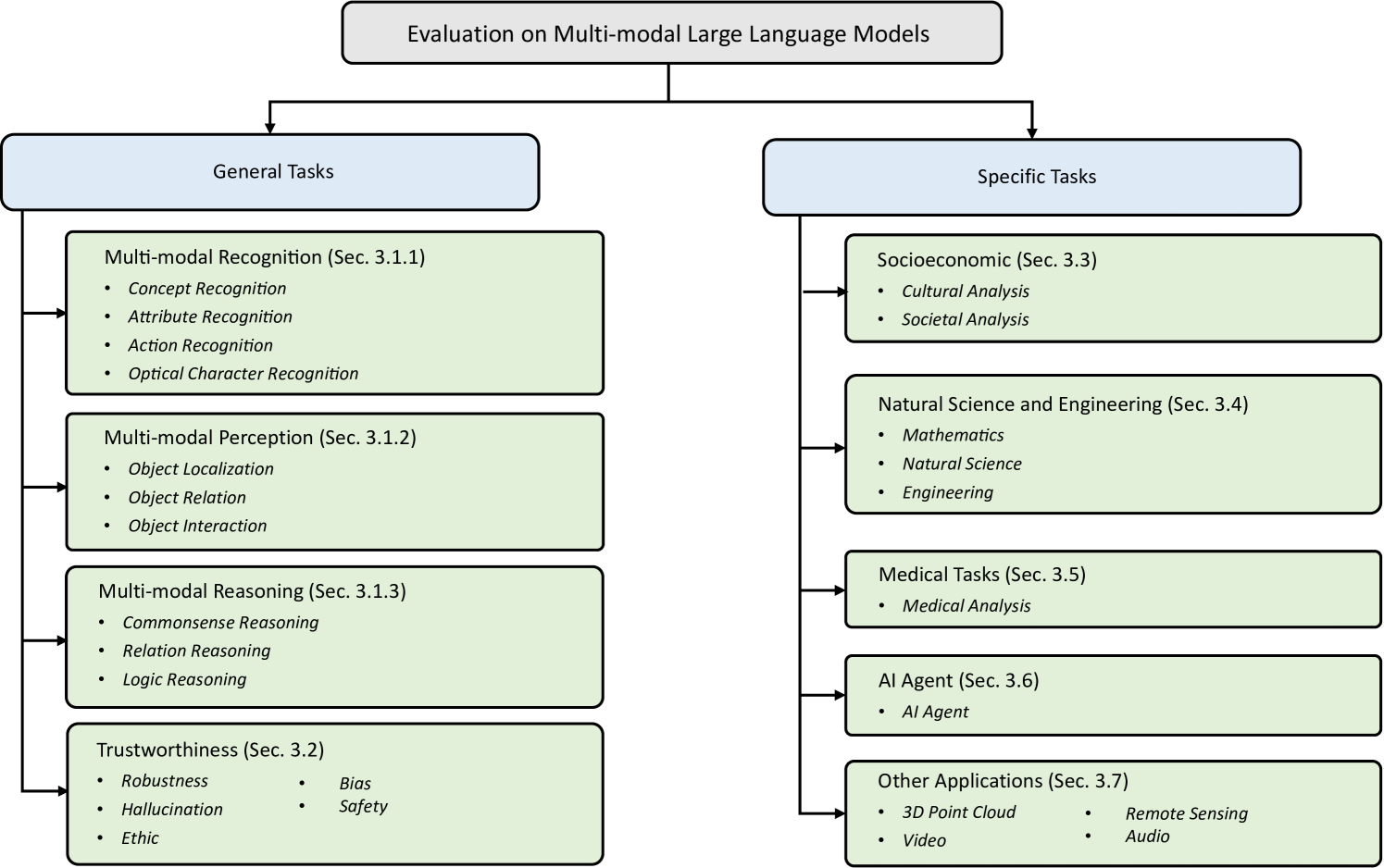
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the brain and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) what to evaluate that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) where to evaluate that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) how to evaluate that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.
Read more8/29/2024